Чтение с файла с определённой строки
У меня есть текстовый файл и мне нужно считать всю информацию, которая расположена после 25-й строки. Как это сделать? Пожалуйста, помогите!
Отслеживать
48.7k 17 17 золотых знаков 56 56 серебряных знаков 100 100 бронзовых знаков
задан 9 дек 2016 в 12:11
1,099 4 4 золотых знака 19 19 серебряных знаков 32 32 бронзовых знака
5 ответов 5
Сортировка: Сброс на вариант по умолчанию
Если небольшой файл, можно список строк получить и отбросить первые 25:
lines = file.readlines()[25:] Если файл большой, то чтобы не читать его весь сразу, можно воспользоваться тем что file является итератором на строками, разделёнными «\n»:
from itertools import islice lines = islice(file, 25, None) в этом случае lines не список, а итератор возвращающий строки из файла при его обходе, начиная с 26-ой строки, где file = open(filename) .
Считываем числовые данные из файла на Python
В данной статье речь пойдет о простой на первой взгляд задаче — считывании числовых данных из текстовых файлов на Python. В сети можно найти десятки способов решения этой задачи, однако эти алгоритмы оказываются малоэффективными при работе с большим объемом данных. В данной статье будут разобраны самые популярные методики, а также произведено сравнение их скорости работы.
Введение
Когда я только начинал изучать Python, главным помощником в работе для меня, как наверное и для большинства программистов, был Stack Overflow. Я почерпнул оттуда много полезной информации, в том числе и о работе с файлами. Однако даже такая тривиальная задача, как оказалось, имеет несколько различных решений, отличающихся друг от друга простотой реализации и скоростью работы.
Большинство предложенных методов предполагают чтение файла построчно с дальнейшим разбиением на блоки и их преобразованием из строкового типа в числовой, поскольку Python в отличии от C/C++ работает с файлами как с массивом строк. Выполнить последовательное чтение данных в массив без преобразования типов, как это можно сделать в C/C++, стандартными средствами языка невозможно (насколько мне известно), и это существенно увеличивает время работы программы при обработке больших объемов данных.
Способы чтения данных из файла
Как уже было сказано выше, файлы в Python представляют собой массив строк, поэтому все найденные методы можно символически поделить на два типа в зависимости от используемого подхода:
- построчное считывание с разбиением и преобразованием типов
- использование библиотек, которые средствами других языков (например, C/C++) считывают файл и передают полученные данные интерпретатору Python
Ниже представлена подборка самых популярных методов чтения числовых данных на Python, отмеченных сообществом Stack Overflow как «best answer».
Способ 1 — построчное считывание с преобразованием
Самый популярный и простой вариант. Заключается в построчном чтении с разбиением полученной строки на блоки, которые затем преобразуются к необходимому типу данных (в данном случае float) и добавляются к заранее созданному списку.
data = [] with open("data.txt") as f: for line in f: data.append([float(x) for x in line.split()])
Способ 2 — преобразование при помощи map
Способ аналогичен предыдущему, за исключением того, что преобразованием данных из строкового формата в числовой занимается функция map.
file = open("data.txt", "r") data = [map(float, line.split("\t")) for line in file]
Способ 3 — с использованием регулярного выражения
Данный способ можно назвать стрельбой из пушки по воробьям, однако у него все же есть свои плюсы: если данные в файле расположены хаотично и отсутствует постоянная структура, то функции split невозможно задать конкретный разделитель и для решения задачи можно использовать регулярное выражение, которое найдет в строке все числа, несмотря на их расположение и наличие разделителей.
import re file = open("data.txt") values = file.read().split("\n") data = [] for key in values: value = re.findall(r"[-+]?\d*\.\d+|\d+", key) if value != []: data.append(value)
Способ 4 — с использованием CSV Reader
Если данные записаны в виде матрицы с постоянными разделителями, то выполнить их чтение можно при помощи модуля CSV Reader, указав в качестве параметра значение разделителя.
import csv with open("data.txt") as f: data = [map(float, row) for row in csv.reader(f, delimiter='\t')]
Способ 5 — Numpy loadtxt
Библиотека Numpy предоставляет широкий набор модулей и функций для обработки числовых данных, в том числе и для чтения массивов из файлов. Одна из реализаций возможна с помощью функции loadtxt, результат работы которой будет записан в numpy.array.
import numpy as np data = np.loadtxt("data.txt", delimiter='\t', dtype=np.float)
Способ 6 — Numpy genfromtxt
Данный способ не сильно отличается от предыдущего, за исключением того, что genfromtxt предоставляет более широкий набор входных параметров: указание различных типов данных для каждого из столбцов, передача ключей для создания ассоциативного массива и так далее.
import numpy as np data = np.genfromtxt("data.txt", delimiter='\t', dtype=np.float)
Способ 7 — Pandas read_csv
Pandas — мощная библиотека для обработки данных на Python. В данном примере рассматривается только чтение данных, но её возможности этим не ограничены. Метод read_csv предоставляет широкий набор входных параметров, а также показывается высокую скорость работы даже при работе с большими объемами данных.
import pandas as pd data = pd.read_csv("data.txt", sep="\t", header=None)
Методы тестирования скорости чтения
Для тестирования скорости чтения числовых данных были сгенерированы 7 тестовых файлов, содержащих 5 столбцов и 10, 100, 1 000, 10 000, 100 000, 1 000 000 и 10 000 000 строк случайных чисел формата float. Размер самого большого файла составил 742 Мб.
Для измерения времени работы программы использовалась функция time. Существует мнение, что измерять с её помощью время работы некорректно. Однако в данном случае меня интересовало работа с большими объемами данных, когда время работы программы составляло несколько десятков секунд. В таком случае отклонение в полсекунды вносило погрешность менее 1%.
Сравнение с компилируемыми языками программирования
Программы, созданные на компилируемых языках программирования, работают быстрее, чем их аналоги, написанные на интерпретируемых языках. Мне было интересно сравнить скорость чтения каждого метода с Fortran и C++ — самыми популярными языками в научном программировании, с которыми мне также приходится иметь дело в силу специфики моей работы.
Fortran
Несмотря на то, что Fortran считается устаревшим языком, он все еще очень популярен в научном программировании благодаря простоте написания кода, скорости обмена данных и обширном количестве библиотек, созданных за последние полвека.
Например, считать числовую матрицу из файла можно всего за 3 строчки кода при условии корректности входных данных.
real, dimension (5, 1000) :: data open (1, file='data.txt') read(1, *) data
C++
Дискуссии о том, что лучше: Fortran или C++ ведутся уже давно, даже среди авторов EasyCoding этот спор возникал несколько раз, поэтому мне было еще интересней протестировать чтение матриц на данном языке.
ifstream file(«data.txt»); int count = 100000; float** data = new float*[count]; for(int i = 0; i
Результаты тестирования
В ходе эксперимента были протестированы 7 программ на языке Python и по одной на Fortran и C++, код которых представлен выше. Запуск программ осуществлялся на компьютере с Intel Core i5 2.7 GHz и 8 Гб оперативной памяти.
Для запуска программ использовались следующие интерпретаторы и компиляторы:
- Python 3.5.2
- GNU Fortran (GCC) 6.1.0
- g++ 4.2.1
Для каждой программы проводилась серия испытаний и измерялось время работы, после чего записывался результат в виде среднего арифметического полученных данных. В таблице ниже жирным в каждой строке выделено наименьшее время работы в зависимости от способа чтения и размера входного файла.
| Число строк | Способ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | Fortran | C++ | |
| 10 | 0.048 | 0.048 | 0.045 | 0.044 | 0.173 | 0.216 | 0.479 | 0.005 | 0.005 |
| 100 | 0.053 | 0.052 | 0.05 | 0.048 | 0.185 | 0.223 | 0.511 | 0.007 | 0.006 |
| 1 000 | 0.056 | 0.053 | 0.053 | 0.052 | 0.187 | 0.233 | 0.6 | 0.01 | 0.01 |
| 10 000 | 0.085 | 0.076 | 0.096 | 0.083 | 0.305 | 0.292 | 0.636 | 0.032 | 0.041 |
| 100 000 | 0.414 | 0.403 | 0.561 | 0.482 | 1.537 | 0.874 | 0.796 | 0.244 | 0.363 |
| 1 000 000 | 3.835 | 4.502 | 6.086 | 5.276 | 13.607 | 6.754 | 1.763 | 2.584 | 3.662 |
| 10 000 000 | 47.931 | 156.944 | 137.398 | 144.75 | 162.724 | 85.642 | 13.632 | 25.652 | 36.622 |
Итог
В ходе данного исследования были протестированы 7 самых популярных варианта чтения числовых матриц на языке Python, предложенными пользователями сайта Stack Overflow и отмеченными сообществом как «верный ответ». Как видно из таблицы с результатами, скорость работы программ не сильно отличается при использовании способов 1-4 на небольших объемах данных. Это связано с тем, что интерпретатор не тратит время на инициализацию сторонней библиотеки, как в методах 5-7.
Однако при увеличении объема входных данных лучше всех себя показал метод 7 с использованием библиотеки Pandas, который даже обогнал по скорости чтения данных языки C++ и Fortran.
Также из результатов теста можно видеть, что программа на Fortran справилась с чтением данных быстрей аналога на C++, что еще раз доказывает его превосходство над самым популярным языком программирования в мире.
10 commentaries to post
Наконец, нашел, что искал. Способ 6 — Numpy genfromtxt, который предоставляет более широкий набор входных параметров: указание различных типов данных для каждого из столбцов, передача ключей для создания ассоциативного массива и так далее.
Спасибо. Сэкономили время на поиск единственного, что нужно для моих вычислений по таблице «тексты-слова»…
ошибка в таблице ! 0.044 не меньше чем 0.005 а больше почти в 9 раз!
nightflash :
Нет ошибки. Автор сравнивал скорости Python решений.
С++, который обгонит всё перечисленное:
FILE* f = fopen(«data.txt», «rb») int count = 10000; float** data = new float*[count]; for(int i = 0; i < count; ++i)
Причем не особо кошерная реализация. Но соответствует предоставленному коду.
Кошерная реализация это:
fread(data, sizeof(float) * 5 * count, f);
Python: Извлечение символов из строки
Иногда нужно получить один символ из строки. Например, если сайт знает имя и фамилию пользователя, и в какой-то момент требуется вывести эту информацию в формате A. Ivanov. Для этого компьютеру потребуется взять первый символ из имени. В Python есть подходящая операция, которую мы изучим сегодня.
Представим, что из имени Alexander нужно вывести на экран только первую букву. Это выглядит так:
first_name = 'Alexander' print(first_name[0]) # => A Операция с квадратными скобками с цифрой извлекает элемент по индексу — позицией символа внутри строки. Индексы начинаются с 0 почти во всех языках программирования. Поэтому, чтобы получить первый символ, нужно указать индекс 0 . Индекс последнего элемента равен длине строки минус единица. Обращение к индексу за пределами строки приведет к ошибке:
# Длина строки 9, поэтому последний индекс — это 8 first_name = 'Alexander' print(first_name[8]) # => r print(first_name[9]) IndexError: string index out of range Чтобы лучше закрепить новые знания, посмотрите на код ниже и подумайте, что он выдаст:
magic = '\nyou' print(magic[1]) # => ? Бывают и нестандартные ситуации. Например, нужно вывести элемент из конца, причем из выражения с большим количеством символов. В этом случае можно воспользоваться отрицательным индексом, который облегчит работу программиста.
Допустимо использовать отрицательные индексы. В этом случае идет обращение к символам, начиная с конца строки. -1 — индекс последнего символа, -2 — предпоследнего и так далее. В отличие от прямой индексации, обратный отсчет идет от -1 :
first_name = 'Alexander' print(first_name[-1]) # => r Индексом может быть не только конкретное число, но и значение переменной. Посмотрите на пример ниже. Здесь мы записали индекс внутри квадратных скобок не числом, а переменной. Такой код приведет к тому же результату — выводу на экран символа A:
first_name = 'Alexander' index = 0 print(first_name[index]) # => A Чтобы выводить из выражения лишь некоторые символы, не нужно писать большое количество строк кода — достаточно извлечь элемент с помощью индекса. Также можно пользоваться отрицательным индексом, чтобы легче выводить символы с конца выражения. Далее разберемся, как с помощью этих знаний можно извлекать подстроки из строки.
Задание
Выведите на экран последний символ строки, находящейся в переменной name
Упражнение не проходит проверку — что делать? ��
Если вы зашли в тупик, то самое время задать вопрос в «Обсуждениях». Как правильно задать вопрос:
- Обязательно приложите вывод тестов, без него практически невозможно понять что не так, даже если вы покажете свой код. Программисты плохо исполняют код в голове, но по полученной ошибке почти всегда понятно, куда смотреть.
В моей среде код работает, а здесь нет ��
Тесты устроены таким образом, что они проверяют решение разными способами и на разных данных. Часто решение работает с одними входными данными, но не работает с другими. Чтобы разобраться с этим моментом, изучите вкладку «Тесты» и внимательно посмотрите на вывод ошибок, в котором есть подсказки.
Мой код отличается от решения учителя ��
Это нормально ��, в программировании одну задачу можно выполнить множеством способов. Если ваш код прошел проверку, то он соответствует условиям задачи.
В редких случаях бывает, что решение подогнано под тесты, но это видно сразу.
Прочитал урок — ничего не понятно ��
Создавать обучающие материалы, понятные для всех без исключения, довольно сложно. Мы очень стараемся, но всегда есть что улучшать. Если вы встретили материал, который вам непонятен, опишите проблему в «Обсуждениях». Идеально, если вы сформулируете непонятные моменты в виде вопросов. Обычно нам нужно несколько дней для внесения правок.
Кстати, вы тоже можете участвовать в улучшении курсов: внизу есть ссылка на исходный код уроков, который можно править прямо из браузера.
Определения
- Индекс — позиция символа внутри строки.
Извлечение текста из файлов PDF при помощи Python
В эпоху больших языковых моделей (Large Language Model, LLM) и постоянно расширяющейся сферы их применений непрерывно растёт и важность текстовых данных.
Существует множество типов документов, содержащих подобные виды неструктурированной информации, от веб-статей и постов в блогах до рукописных писем и стихов. Однако существенная часть этих данных хранится и передаётся в формате PDF. В частности, выяснилось, что за каждый год в Outlook открывают более двух миллиардов PDF, а в Google Drive и электронной почте ежедневно сохраняют 73 миллионов новых файлов PDF (2).
Поэтому разработка более систематического способа обработки этих документов и извлечения из них информации позволит нам автоматизировать процесс и лучше понять этот обширный объём текстовых данных. И в выполнении этой задачи, разумеется, нашим лучшим другом будет Python.
Но прежде чем начать процесс, нам нужно определиться с различными типами современных PDF, и в частности, с тремя, используемыми наиболее часто:
- Программно генерируемые PDF : эти PDF создаются на компьютере или при помощи технологий W3C (HTML, CSS и Javascript), или при помощи другого ПО, например, Adobe Acrobat. Такой тип файла может содержать различные компоненты, например, изображения, текст и ссылки, по всем ним можно выполнять поиск и легко их редактировать.
- Традиционные отсканированные документы : такие PDF создаются из неэлектронных носителей при помощи сканера или мобильного приложения. Эти файлы являются просто набором изображений, сохранённых вместе в файл PDF. Поэтому элементы на изображениях, например, текст или ссылки, невозможно выбирать или выполнять по ним поиск. По сути, PDF служит контейнером для таких изображений.
- Отсканированные документы с OCR : в этом случае после сканирования документа применяется ПО для оптического распознавания символов (Optical Character Recognition, OCR), распознающее текст в каждом изображении файла и преобразующее его в текст с возможностью поиска по нему и редактирования. Затем ПО добавляет на изображение слой текста, благодаря чему при просмотре файла можно выбирать его как отдельный компонент. (3)
▍ Теоретическое решение
Помня о перечисленных типах файлов PDF и различных составляющих их элементах, важно выполнить первоначальный анализ структуры PDF для определения подходящего инструмента, необходимого для каждого компонента. На основании результатов этого анализа мы будем применять соответствующий способ извлечения текста из PDF, будь то текстовый блок с метаданными, текст в изображениях или структурированный текст в таблицах. В отсканированных документах без OCR основную задачу будет выполнять методика выявления и извлечения текста из изображений. Результатом этого процесса станет словарь Python, содержащий информацию, извлечённую из каждой страницы файла PDF. Каждый ключ в этом словаре будет обозначать номер страницы документа, а соответствующее ему значение будет списком со пятью следующими вложенными списками, содержащими следующие данные:
- Текст, извлечённый из каждого текстового блока корпуса
- Формат текста в каждом текстовом блоке (тип и размер шрифта)
- Текст, извлечённый из изображений на странице
- Текст, извлечённый из таблиц в структурированном формате
- Полное текстовое содержимое страницы

Таким образом мы сможем обеспечить более логичное разделение извлечённого текста по исходным компонентам; к тому же это иногда может помочь нам проще извлекать информацию, обычно встречаемую в конкретном компоненте (например, название компании в изображении логотипа). Кроме того, извлечённые из текста метаданные, например, тип и размер шрифта, можно использовать для упрощения распознавания заголовков текста или важного выделенного текста, что позволит нам ещё сильнее разделить его или выполнять постобработку текста по отдельным блокам. Наконец, сохранение структурированной информации таблиц в понятном для LLM виде существенно повысит качество инференсов, которые модель будет делать о взаимосвязях внутри извлечённых данных. Далее эти результаты можно будет скомбинировать в вывод всей текстовой информации на каждой странице.
На рисунках ниже показана блок-схема этой методики.

▍ Установка всех необходимых библиотек
Перед началом этого проекта нам установить библиотеки. Будем предполагать, что у вас установлен Python 3.10 или более новая версия. В противном случае можно установить его отсюда. Затем установим следующие библиотеки:
PyPDF2 : для считывания файла PDF по пути репозитория.
pip install PyPDF2Pdfminer : для выполнения анализа структуры и извлечения текста и формата из PDF. (Python 3 поддерживает версия .six библиотеки.)
pip install pdfminer.sixPdfplumber : для распознавания таблиц на странице PDF и извлечения информации из них.
pip install pdfplumberPdf2image : для преобразования обрезанного изображения PDF в изображение PNG.
pip install pdf2imagePIL : для чтения изображения PNG.
pip install PillowPytesseract : для извлечения текста из изображений при помощи технологии OCR
Её устанавливать немного сложнее, потому что сначала необходимо установить Google Tesseract OCR — платформу OCR, основанную на модели LSTM, которая занимается распознаванием линий и паттернов символов.
Для установки на машину Mac через Brew достаточно сделать следующее:
brew install tesseractПользователи Windows для установки библиотеки могут воспользоваться этой ссылкой. Затем после скачивания и установки ПО необходимо добавить пути к его исполняемым файлам в переменные окружения компьютера. Или же можно выполнить следующие команды, чтобы напрямую добавить их пути в скрипт Python:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'Затем можно установить библиотеку Python
pip install pytesseractНаконец, мы импортируем все библиотеки в начале нашего скрипта.
# Для считывания PDF import PyPDF2 # Для анализа структуры PDF и извлечения текста from pdfminer.high_level import extract_pages, extract_text from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure # Для извлечения текста из таблиц в PDF import pdfplumber # Для извлечения изображений из PDF from PIL import Image from pdf2image import convert_from_path # Для выполнения OCR, чтобы извлекать тексты из изображений import pytesseract # Для удаления дополнительно созданных файлов import osИтак, теперь всё готово, можно приступать к самому интересному.
▍ Анализ структуры документа при помощи Python

Для предварительного анализа мы воспользовались библиотекой Python PDFMiner, чтобы разделить текст из документа на несколько объектов страниц, а затем разбить и исследовать структуру каждой страницы. В файлах PDF отсутствует структурированная информация (абзацы, предложения и слова, воспринимаемые человеческим глазом). Они понимают только отдельные символы текста и их положение на странице. PDFMiner пытается воссоздать содержимое страницы в отдельных символах и их расположении на в файле. Затем, сравнивая расстояния этих символов от других, он собирает слова, предложения, строки и абзацы текста. (4) Чтобы добиться этого, библиотека:
Разделяет отдельные страницы из файла PDF при помощи высокоуровневой функции extract_pages() и преобразует их в объекты LTPage .
Затем для каждого объекта LTPage, она итеративно обходит каждый элемент сверху вниз и пытается идентифицировать один из соответствующих компонентов:
- LTFigure , обозначающий область PDF, которая может быть изображениями, встроенными в страницу как другой документ PDF.
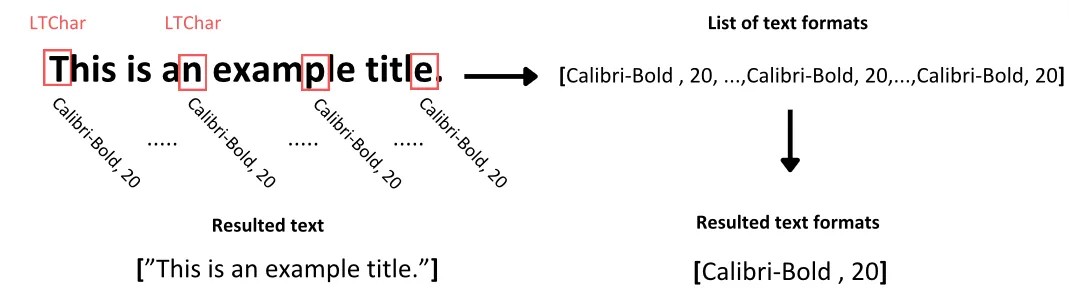
- LTTextContainer , обозначающий группу текстовых строк в прямоугольной области, которая затем анализируется, превращаясь в список объектов LTTextLine . Каждый из них представляет собой список объектов LTChar , в которых хранятся отдельные символы текста вместе с их метаданными. (5)
- LTRect , обозначающий двухмерный прямоугольник, который можно использовать для задания рамок изображений или для создания таблиц в виде объекта LTPage.
for pagenum, page in enumerate(extract_pages(pdf_path)): # Итеративно обходим элементы, из которых состоит страница for element in page: # Проверяем, является ли элемент текстовым if isinstance(element, LTTextContainer): # Функция для извлечения текста из текстового блока pass # Функция для извлечения формата текста pass # Проверка элементов на наличие изображений if isinstance(element, LTFigure): # Функция для преобразования PDF в изображение pass # Функция для извлечения текста при помощи OCR pass # Проверка элементов на наличие таблиц if isinstance(element, LTRect): # Функция для извлечения таблицы pass # Функция для преобразования содержимого таблицы в строку passРазобравшись с аналитической частью процесса, давайте создадим функции, необходимые для извлечения текста из каждого компонента.
▍ Определяем функцию извлечения текста из PDF
После этого извлечение текста из контейнера текста становится очень простой задачей.
# Создаём функцию для извлечения текста def text_extraction(element): # Извлекаем текст из вложенного текстового элемента line_text = element.get_text() # Находим форматы текста # Инициализируем список со всеми форматами, встречающимися в строке текста line_formats = [] for text_line in element: if isinstance(text_line, LTTextContainer): # Итеративно обходим каждый символ в строке текста for character in text_line: if isinstance(character, LTChar): # Добавляем к символу название шрифта line_formats.append(character.fontname) # Добавляем к символу размер шрифта line_formats.append(character.size) # Находим уникальные размеры и названия шрифтов в строке format_per_line = list(set(line_formats)) # Возвращаем кортеж с текстом в каждой строке вместе с его форматом return (line_text, format_per_line)То есть чтобы извлечь текст из контейнера текста, мы просто используем метод get_text () элемента LTTextContainer. Этот метод получает все символы, из которых состоят слова в конкретном прямоугольнике корпуса, сохраняя вывод в список текстовых данных. Каждый элемент в этом списке представляет сырую текстовую информацию, содержащуюся в контейнере.
Теперь для определения формата текста мы итеративно обойдём объект LTTextContainer для получения доступа по отдельности к каждой строке текста в этом корпусе. На каждой итерации создаётся новый объект LTTextLine , обозначающий строку текста в этом блоке корпуса. Затем мы проверяем, содержит ли текст вложенный элемент строки. Если да, то мы получаем доступ к каждому отдельному символу как LTChar, который содержит все метаданные этого символа. Из этих метаданных мы извлекаем два типа форматов и сохраняем их в отдельном списке, расположенном в соответствии с исследуемым текстом:
- Тип шрифта символов, в том числе его полужирность или курсивность
- Размер шрифта символа
▍ Определяем функцию для извлечения текста из изображений
Здесь всё будет несколько сложнее.
Как обрабатывать текст в изображениях, найденных в PDF?
Во-первых, нам нужно определить, что хранящиеся в PDF элементы изображений не отличаются по формату от файла, например, JPEG или PNG. В таком случае для применения к ним ПО OCR нам сначала нужно будет отделить их от файла, а затем преобразовать их в формат изображения.
# Создаём функцию для вырезания элементов изображений из PDF def crop_image(element, pageObj): # Получаем координаты для вырезания изображения из PDF [image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1] # Обрезаем страницу по координатам (left, bottom, right, top) pageObj.mediabox.lower_left = (image_left, image_bottom) pageObj.mediabox.upper_right = (image_right, image_top) # Сохраняем обрезанную страницу в новый PDF cropped_pdf_writer = PyPDF2.PdfWriter() cropped_pdf_writer.add_page(pageObj) # Сохраняем обрезанный PDF в новый файл with open('cropped_image.pdf', 'wb') as cropped_pdf_file: cropped_pdf_writer.write(cropped_pdf_file) # Создаём функцию для преобразования PDF в изображения def convert_to_images(input_file,): images = convert_from_path(input_file) image = images[0] output_file = "PDF_image.png" image.save(output_file, "PNG") # Создаём функцию для считывания текста из изображений def image_to_text(image_path): # Считываем изображение img = Image.open(image_path) # Извлекаем текст из изображения text = pytesseract.image_to_string(img) return textЧтобы добиться этого, мы выполняем следующий процесс:
- Применяем метаданные из объекта LTFigure, обнаруженного из PDFMiner, чтобы обрезать прямоугольник изображения, используя его координаты в структуре страницы. Затем сохраняем его как новый PDF в нашу папку при помощи библиотеки PyPDF2 .
- Затем используем функцию convert_from_file () из библиотеки pdf2image для преобразования всех файлов PDF в папке в список изображений, сохраняя их в формат PNG.
- Наконец, теперь, когда у нас есть файлы изображений, мы считываем их в нашем скрипте при помощи пакета Image модуля PIL и реализуем функцию image_to_string () библиотеки pytesseract, чтобы извлечь текст из изображений при помощи движка OCR tesseract.
▍ Определяем функцию для извлечения текста из таблиц
В этом разделе мы будем извлекать более логически структурированный текст из таблиц на странице PDF. Это чуть более сложная задача, чем извлечение текста из корпуса, потому что нам нужно учитывать дробность информации и взаимосвязи между примерами данных, представленными в таблице.
Хотя существует множество библиотек для извлечения из PDF табличных данных (самая популярная из них — это Tabula-py ), мы выявили в их функциональности определённые ограничения.
На наш взгляд, самое очевидное из них — это то, что библиотека помечает разные строки в таблице при помощи специальным символом разрыва строки \n в тексте таблицы. В большинстве случаев это работает достаточно неплохо, но не позволяет распознать таблицу правильно, когда текст в ячейке разделён на две или более строки, что приводит к добавлению ненужных пустых строк и потере контекста извлечённой ячейки.
Ниже показан пример этого при попытке извлечения данных из таблицы при помощи tabula-py:

Кроме того, извлечённая информация выводится в Pandas DataFrame, а не в строку. В большинстве случаев этот формат может быть предпочтительным, но в случае трансформеров, работающих с текстом, перед отправкой в модель эти результаты необходимо преобразовывать.
Поэтому для выполнения этой задачи мы использовали библиотеку pdfplumber . Во-первых, она создана на основе pdfminer.six, которую мы уже использовали для предварительного анализа, то есть она содержит схожие объекты. Кроме того, её методика распознавания таблиц основана на элементах строк и их пересечениях, составляющих ячейку, содержащую текст, а затем и саму таблицу. Благодаря этому после определения ячейки таблицы мы можем извлечь только содержимое внутри ячейки, не перенося информацию о том, сколько строк должно рендериться. Получим содержимое таблицы, мы сформатируем его в напоминающую таблицу строку и сохраним в соответствующий список.
# Извлечение таблиц из страницы def extract_table(pdf_path, page_num, table_num): # Открываем файл pdf pdf = pdfplumber.open(pdf_path) # Находим исследуемую страницу table_page = pdf.pages[page_num] # Извлекаем соответствующую таблицу table = table_page.extract_tables()[table_num] return table # Преобразуем таблицу в соответствующий формат def table_converter(table): table_string = '' # Итеративно обходим каждую строку в таблице for row_num in range(len(table)): row = table[row_num] # Удаляем разрыв строки из текста с переносом cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row] # Преобразуем таблицу в строку table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n') # Удаляем последний разрыв строки table_string = table_string[:-1] return table_stringЧтобы сделать это, мы создали две функции, extract_table() для извлечения содержимого таблицы в список списков, и table_converter() , для объединения содержимого этих списков напоминающую таблицу строку.
В функции extract_table() :
- Мы открываем файл PDF.
- Переходим к исследуемой странице файла PDF.
- Из списка таблиц, найденных на странице библиотекой pdfplumber, мы выбираем нужную нам.
- Извлекаем содержимое таблицы и выводим его в список вложенных списков, представляющих собой каждую строку таблицы.
- Мы итеративно обходим каждый вложенный список и очищаем его содержимое от ненужных разрывов строк, возникающих из-за текста с переносами.
- Объединяем каждый элемент строки таблицы, разделяя их символом | для создания структуры ячейки таблицы.
- Наконец, мы добавляем разрыв строки в конце, чтобы перейти к следующей строке таблицы.
▍ Соединяем всё вместе
Теперь, когда все компоненты кода готовы, давайте объединим их, чтобы получить полнофункциональный код. Можете скопировать код отсюда или найти его с примером PDF в моём репозитарии Github здесь.
# Находим путь к PDF pdf_path = 'OFFER 3.pdf' # создаём объект файла PDF pdfFileObj = open(pdf_path, 'rb') # создаём объект считывателя PDF pdfReaded = PyPDF2.PdfReader(pdfFileObj) # Создаём словарь для извлечения текста из каждого изображения text_per_page = <> # Извлекаем страницы из PDF for pagenum, page in enumerate(extract_pages(pdf_path)): # Инициализируем переменные, необходимые для извлечения текста со страницы pageObj = pdfReaded.pages[pagenum] page_text = [] line_format = [] text_from_images = [] text_from_tables = [] page_content = [] # Инициализируем количество исследованных таблиц table_num = 0 first_element= True table_extraction_flag= False # Открываем файл pdf pdf = pdfplumber.open(pdf_path) # Находим исследуемую страницу page_tables = pdf.pages[pagenum] # Находим количество таблиц на странице tables = page_tables.find_tables() # Находим все элементы page_elements = [(element.y1, element) for element in page._objs] # Сортируем все элементы по порядку нахождения на странице page_elements.sort(key=lambda a: a[0], reverse=True) # Находим элементы, составляющие страницу for i,component in enumerate(page_elements): # Извлекаем положение верхнего края элемента в PDF pos= component[0] # Извлекаем элемент структуры страницы element = component[1] # Проверяем, является ли элемент текстовым if isinstance(element, LTTextContainer): # Проверяем, находится ли текст в таблице if table_extraction_flag == False: # Используем функцию извлечения текста и формата для каждого текстового элемента (line_text, format_per_line) = text_extraction(element) # Добавляем текст каждой строки к тексту страницы page_text.append(line_text) # Добавляем формат каждой строки, содержащей текст line_format.append(format_per_line) page_content.append(line_text) else: # Пропускаем текст, находящийся в таблице pass # Проверяем элементы на наличие изображений if isinstance(element, LTFigure): # Вырезаем изображение из PDF crop_image(element, pageObj) # Преобразуем обрезанный pdf в изображение convert_to_images('cropped_image.pdf') # Извлекаем текст из изображения image_text = image_to_text('PDF_image.png') text_from_images.append(image_text) page_content.append(image_text) # Добавляем условное обозначение в списки текста и формата page_text.append('image') line_format.append('image') # Проверяем элементы на наличие таблиц if isinstance(element, LTRect): # Если первый прямоугольный элемент if first_element == True and (table_num+1) = lower_side and element.y1 Приведённый выше скрипт выполняет следующие действия:
Импортирует необходимые библиотеки.
Открывает файл PDF при помощи библиотеки pyPDF2 .
Извлекает каждую страницу в PDF и итеративно выполняет следующие этапы.
Определяет, есть ли на странице таблицы и создаёт их список при помощи pdfplumner.
Находит все вложенные в страницу элементы и сортирует в порядке их нахождения в структуре страницы.
Затем для каждого элемента:
Проверяет, текстовый ли это контейнер, и не встречается ли он в табличном элементе. Затем использует функцию text_extraction () для извлечения текста с его форматом, в противном случае пропускает этот текст.
Проверяет, изображение ли это, и использует функцию crop_image () для вырезания компонента изображения из PDF, преобразует его в файл изображения при помощи convert_to_images () и извлекает из него текст при помощи OCR функцией image_to_text ().
Проверяет, прямоугольный ли это элемент. Если да, то проверяет, является ли первый прямоугольник частью таблицы на странице, и если да, то переходит к следующим этапам:
- Находит ограничивающий прямоугольник таблицы, чтобы не извлекать этот текст заново при помощи функции text_extraction().
- Извлекает содержимое таблицы и преобразует его в строку.
- Добавляет двоичный параметр, чтобы указать, что мы извлекаем текст из таблицы.
- Этот процесс завершится после последнего LTRect, относящегося к ограничивающему прямоугольнику таблицы, когда следующий элемент в структуре страницы не является прямоугольным объектом. (Все остальные объекты, составляющие таблицу, будут пропущены)
- page_text: содержит текст, взятый из текстовых контейнеров в PDF (если текст был извлечён из другого элемента, здесь будет сохранено условное обозначение)
- line_format: содержит форматы извлечённого выше текста (если текст извлечён из другого элемента, здесь будет сохранено условное обозначение)
- text_from_images: содержит тексты, извлечённые из изображений на странице
- text_from_tables: содержит напоминающую таблицу строку с содержимым таблиц
- page_content: содержит в списке элементов весь текст, рендерящийся на странице
Затем мы закрываем файл PDF и удаляем все дополнительные файлы, созданные в процессе работы.
Наконец, мы можем отобразить содержимое страницы, объединив элементы в списке page_content.
▍ Заключение
Мне кажется, эта методика использует наилучшие характеристики многих библиотек и делает процесс адаптируемым к различным типам PDF и видам встречаемых элементов, однако основную часть работы выполняет PDFMiner. Кроме того, информация о формате текста может помочь нам в выявлении возможных заголовков, которые разделяют текст на отдельные логические блоки, а не просто содержимого страницы, и идентифицировать текст повышенной важности.
▍ Ссылки:
- https://www.techopedia.com/12-practical-large-language-model-llm-applications
- https://www.pdfa.org/wp-content/uploads/2018/06/1330_Johnson.pdf
- https://pdfpro.com/blog/guides/pdf-ocr-guide/#:~:text=OCR technology reads text from, a searchable and editable PDF.
- https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html#id1
- https://github.com/pdfminer/pdfminer.six