Загрузите что угодно на Google Диск с помощью Google Colab
Google Collab – это бесплатная онлайн-платформа, предоставляемая Google, которая предоставляет ЦП, графический процессор и другую инфраструктуру для выполнения сложных вычислений и анализа данных. Google Collab предоставляет среду блокнота Jupyter для запуска кода Python. Мы можем загрузить что угодно на диск Google с помощью Google Collab, подключив наш диск Google к Collab. В этой статье мы поймем, как можно загрузить что-либо на Google Диск с помощью Google Collab.
Шаг 1. Настройка совместной работы Google
Если у вас есть учетная запись Google, вы можете открыть веб-сайт Google Collab и нажать «Новый блокнот», чтобы создать новый блокнот Jupyter. Чтобы получить доступ к Google Collab, вам необходимо иметь учетную запись Google.
Шаг 2. Подключение Google Диска
Чтобы загрузить что-либо на Google Диск с помощью Google Collab, вам необходимо подключить свою учетную запись Google Drive из среды Google Collab. Чтобы подключить диск Google к Collab, запустите следующий код на ноутбуке Jupyter в Collab.
После запуска кода вы получите запрос на аутентификацию вашей учетной записи Google и разрешение Collab доступа к вашему диску. Следуйте инструкциям в командной строке и завершите процесс аутентификации.
from google.collab import drive drive.mount('/content/drive') Выход

Шаг 3. Загрузка файлов на Google Диск.
После того, как ваш диск подключен к среде совместной работы, вы можете загружать файлы из Интернета прямо на свой диск Google, используя следующий синтаксис кода.
Синтаксис
!wget -P /content/drive/My\ Drive [file URL] Здесь [URL-адрес файла] — URL-адрес файла, который вы хотите загрузить. !wget используется для загрузки файлов из Интернета, а -P указывает место хранения файла на диске Google.
Пример
В приведенном ниже примере мы загрузили логотип Python и сохранили его в корневом каталоге нашего диска.
!wget -P /content/drive/My\ Drive https://www.python.org/static/img/python-logo.png Выход

Заключение
В этой статье мы обсудили, как можно загружать файлы из Интернета прямо на наш диск Google. Чтобы загрузить что-либо на наш диск Google, нам нужно смонтировать наш диск Google в среде совместной работы. После того, как диск смонтирован в Collab, мы можем загрузить на него любой файл с помощью команды wget.
Все права защищены. © Linux-Console.net • 2019-2024
Быстрая загрузка большого количества данных в Google Colab
Доброго времени суток, Хабр. Решил поделиться своим знанием, как можно быстро загрузить большое количество файлов в Google Colab с Google Drive.
Всем известно, что Google Colab отличная бесплатная платформа для обучения и экспериментов над Нейронными Сетями.
На платформе Google Colab Вам бесплатно предоставят мощную видеокарту на которой вы сможете поэкспериментировать с обучением своей нейросети на протяжении примерно 12 часов.
Затем сеанс прервется, но на следующий день от Google можно опять будет получить видеокарту и продолжить свои эксперименты.
Нейронным сетям требуется очень много данных для обучения, особенно если речь идет о нейросетях работающих с изображениями.
Для обучения таких нейросетей необходимо загрузить в обучающую и валидационную выборки тысячи и сотни изображений. К сожалению, если эти изображения загружать непосредственно из вашего Google Drive, это занимает неприлично долгое время — десятки минут или даже часы. Ведь каждое обращение за файлом в Google Drive и получение от него ответа с содержимым файла происходит последовательно и не быстро.
Обидно тратить время доступа к бесплатной видеокарте на загрузку данных, да и не разумно это.
А мы люди разумные, поэтому мы один раз обратимся к Google Drive считаем наши данные запакованные заранее в zip архив, распакуем полученный zip архив в память Google Colab и считаем свои данные со скоростью в сотни раз большей чем с Google Drive последовательно по одному файлу.
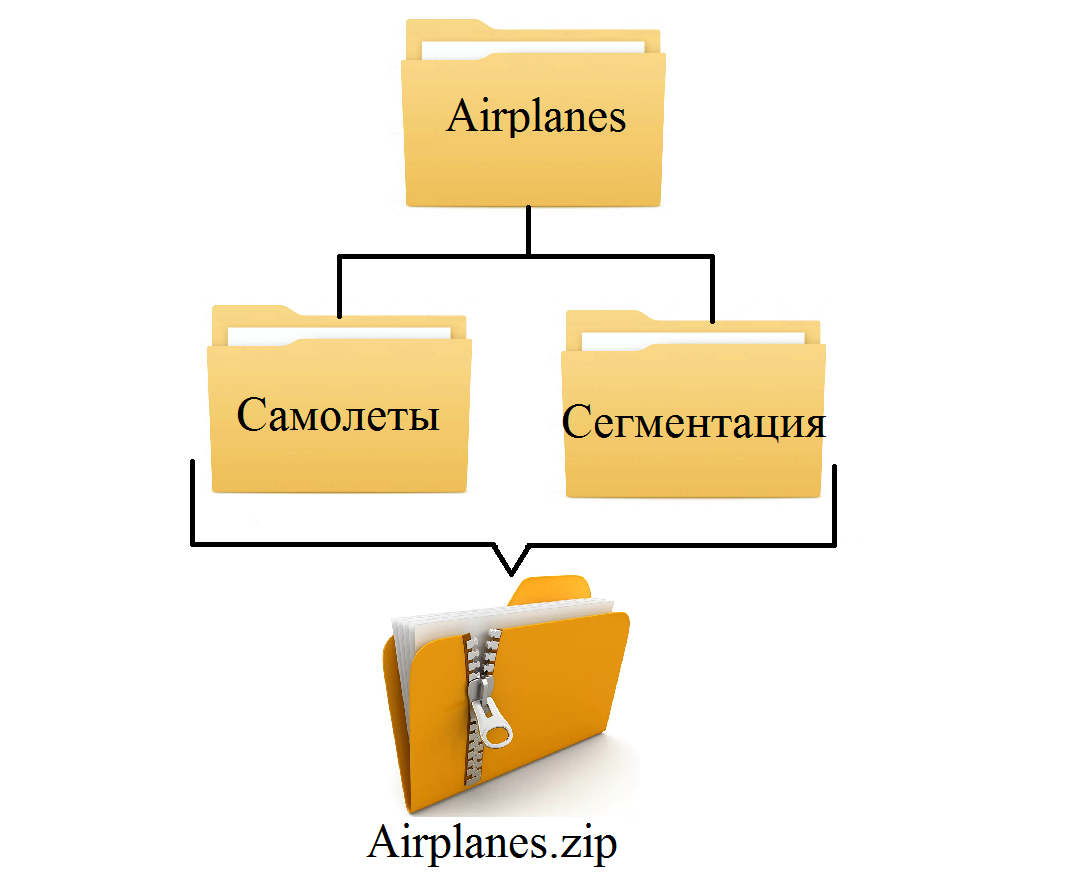
Для эксперимента со скорость загрузки данных в Colab я взял имеющуюся у меня базу «Airplanes» для сегментационной нейросети.
В этой базе есть папка с изображениями «самолеты» и папка «сегментация», где хранятся маски изображений самолетов из вышеназванной папки.
В каждой папке по 1005 изображений 1920*1080.
В общей сложности нам предстоит загрузить 2010 файлов.
Я заранее загрузил к себе на Google Drive как саму базу с изображениями, так и ее zip архив.
Структура Обучающей Базы:
Итак, приступим к скоростной загрузке данных с Google Drive:
-
Запускаем Google Colab и импортируем необходимые нам для этого библиотеки и модули
Выполняем команду на подключение к Google Drive

Переходим по ссылке для выбора свое аккаунта Google

Выбираем свой аккаунт в Google
Подтверждаем доступ Colab к Google Drive
Копируем авторизационный код для доступа к Google Drive
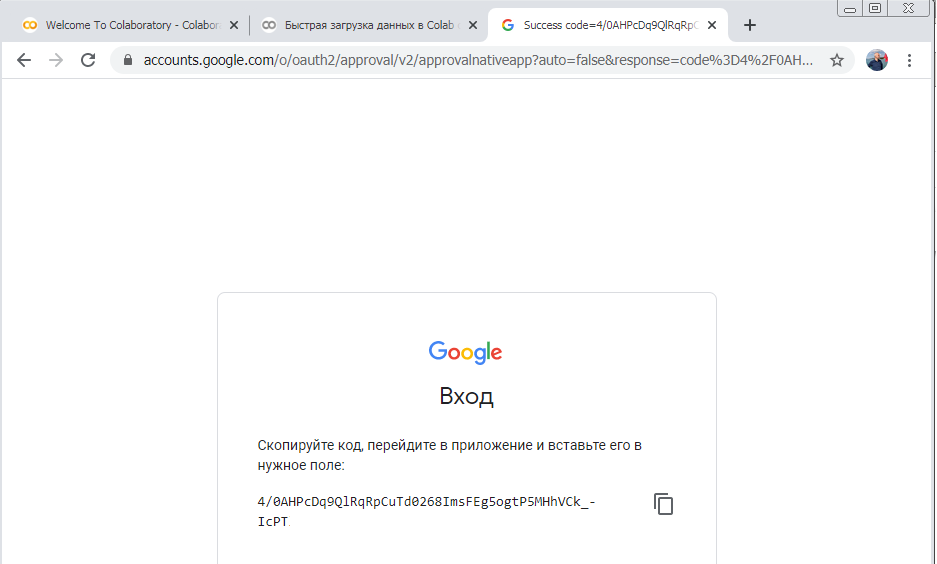
Вставляем авторизационный код в строку и получаем доступ к своему Google Drive

Прописываем путь к архиву с обучающей базой данных и разархивируем ее память Colab

Для тестирования скорости чтения файлов я написал функцию, которая пройдется по всем подкаталогам обучающей базы и в каждом подкаталоге прочитает все файлы которые в нем хранятся.
Тестируем скорость чтения всех файлов
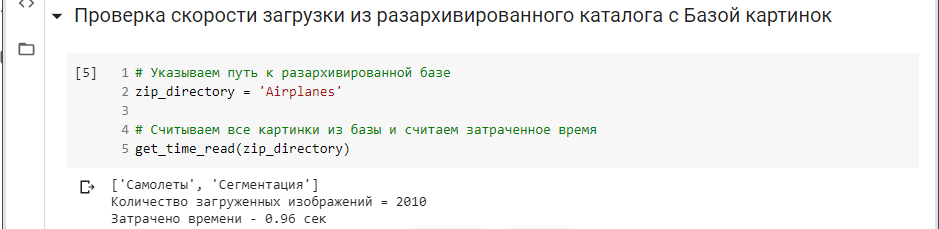
Как видно, время за которое мы загрузили 2010 файлов c размером изображения 1920*1080 составило всего 0,96 сек.
То есть, менее чем за секунду, мы загрузили весь наш объем информации.

Как мы видим для загрузки из каталога 2010 файлов хранящихся на Google Drive нам потребовалось уже 1500 секунд, а ведь это 25 минут.
Это 25 минут простоя вашего экспериментов с нейросетью.
Надеюсь, статья была для вас полезной и теперь загрузка большого количества файлов с Google Drive в Colab больше уже не проблема.
Загружайте свои обучающие данные в сотни раз быстрее чем делали до этого ранее.
Всего четыре простых шага.
- Запаковать Обучающую Базу в zip архив.
- Загрузить zip файл с Обучающей Базой к себе на Google Drive
- Распаковать zip файл с Обучающей базой в память Colab
- Прочитать все файлы памяти Colab в вашу программу
Для тех, кому нужен код, описанный в статье, добро пожаловать ко мне на GitHub.
Colaboratory. Работаем с локальной файловой системой Вашего компьютера и Google диском

# wget — закачка с сети Internet на Google диск в папку /content/gdrive/My\ Drive ( My\ Drive — пробел в имени файла в системе Linux экранируется обратным слэшем ) файла с входными данными нейронной сети (в нашем случае: dogscats.zip — множество портретов кошек и собак для обучения и тестирования нейронной сети):
! wget -P /content/gdrive/My\ Drive http://files.fast.ai/data/dogscats.zip
!unzip /content/gdrive/My\ Drive/dogscats.zip -d /content/gdrive/My\ Drive/
!git clone https://github.com/fastai/fastai.git /content/gdrive/My\ Drive/fastai
PATH = «/content/gdrive/My Drive/dogscats/»
os.listdir(PATH)
Управление файлами в Google Colab
Google Colaboratory — бесплатная среда Jupyter Notebook, которая выполняется на облачных серверах Google и позволяет использовать аппаратное оборудование бэкенда, например GPU and TPU. В результате вы можете работать со всеми возможностями Jupyter Notebook, не устанавливая его на локальной машине.
Colab поставляется (почти) со всеми настройками, позволяющими начать процесс программирования, за исключением датасетов. Как же с помощью Colab получить к ним доступ?
В данной статье мы рассмотрим:
- как загружать данные в Colab из разных источников;
- как произвести обратную запись из Colab в эти источники данных;
- ограничения Google Colab при работе с внешними файлами.
Операции с директориями и файлами в Google Colab
Поскольку Colab позволяет делать все, что угодно, в локально размещенном Jupyter Notebook, то появляется возможность работать с командами оболочки, такими как ls , dir , pwd , cd , cat , echo и т.д., с помощью магической команды для строки ( % ) или bash-команды ( ! ).
Для просмотра структуры директории воспользуйтесь панелью файлового менеджера слева.
Как загружать и скачивать файлы в/из Google Colab
Поскольку блокнот Colab размещается на облачных серверах Google, то по умолчанию отсутствует прямой доступ к файлам на вашем локальном диске (в отличие от расположенного на компьютере блокнота) или в любой другой среде.
Однако Colab предоставляет разные варианты подключения к практически любому источнику данных. Посмотрим, как это происходит.
Обращение к GitHub из Google Colab
Вы можете либо клонировать весь репозиторий GitHub в среду Colab, либо получить доступ к отдельным файлам по их необработанной ссылке.
Клонирование репозитория GitHub
Клонирование репозитория Github в среду Colab происходит по такому же принципу, как и на локальный компьютер, а именно с помощью git clone . По завершении этой процедуры обновите менеджер файлов для просмотра содержимого.
И теперь файлы можно читать точно так же, как и на локальном компьютере.
Скачивание отдельных файлов непосредственно с GitHub
Если для работы нужно лишь несколько файлов, а не весь репозиторий, то можно обойтись без его клонирования в Colab и скачать эти файлы непосредственно с GitHub.
- Кликните на файл в репозитории.
- Кликните на View Raw.
- Скопируйте URL необработанного файла.
- Используйте этот URL как местоположение файла.
Обращение к локальной файловой системе через Google Colab
Читать и записывать файлы из/в локальную файловую систему можно с помощью менеджера или кода Python.
Обращение к локальным файлам через менеджер файлов
Загрузка файлов из локальной файловой системы через менеджер
Для загрузки любых файлов из локальной файловой системы в текущую рабочую директорию Colab можно воспользоваться опцией Upload в верхней части панели менеджера файлов.
Для загрузки файлов напрямую в поддиректорию нужно:
- Кликнуть на три точки, появляющиеся при наведении курсора на каталог.
- Выбрать опцию Upload.
3. Выбрать файлы для загрузки из диалогового окна File Upload.
4. Подождать завершения загрузки, процесс выполнения которой отображается в нижней части панели менеджера файлов.
По окончании процесса загрузки читать файлы можно привычным для вас способом.
Скачивание файлов в локальную файловую систему через менеджер файлов
Кликните на три точки, появляющиеся при наведении курсора на имя файла и выберите опцию Download.
Обращение к локальной файловой системе посредством кода Python
Для осуществления этого шага предварительно требуется импортировать модуль files из google.colab library :
from google.colab import files
Загрузка файлов из локальной файловой системы посредством кода Python
Применяем метод загрузки объекта files :
uploaded = files.upload()
В результате открывается диалоговое окно File Upload:
Выбираем файлы для загрузки и ждем завершения. Ход ее выполнения отображается:
Объект uploaded является словарем, где имена файлов и их содержимое хранятся в виде пар “ключ-значение”:
По окончании загрузки считать его можно точно так же, как и любой другой файл из Colab:
df4 = pd.read_json("News_Category_Dataset_v2.json", lines=True)
Также есть способ считать его напрямую из директории uploaded , используя библиотеку io :
import io
df5 = pd.read_json(io.BytesIO(uploaded['News_Category_Dataset_v2.json']), lines=True)
Убедитесь, что имя файла соответствует тому файлу, который вы хотите скачать.
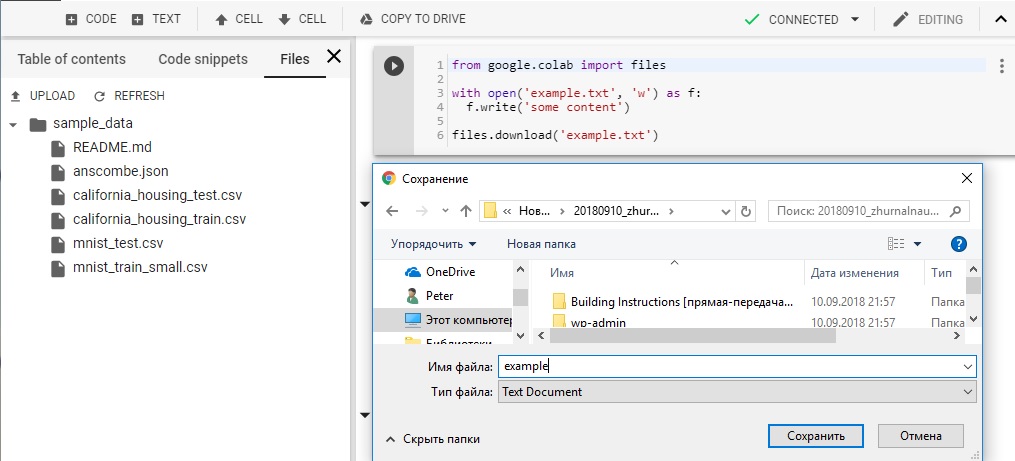
Скачивание файлов из Colab в локальную систему посредством кода Python
Применение метода download объекта files позволяет скачать любой файл из Colab на локальный диск. Процесс выполнения отображается, и по его завершении можно выбрать на локальном компьютере место для сохранения файла.
Обращение к Google Диску из Google Colab
Рассмотрим пошагово, как с помощью модуля drive из google.colab можно смонтировать весь Google Диск в Colab:
1. Выполняем следующий код с целью получения ссылки для аутентификации:
from google.colab import drive
drive.mount('/content/gdrive')
2. Открываем ссылку.
3. Выбираем аккаунт Google, диск которого нужно смонтировать.
4. Разрешаем Google Drive Stream доступ к вашему аккаунту Google.
5. Копируем отображенный код, вставляем его в текстовое окно, как показано ниже, и нажимаем Enter.
По окончании монтирования получаем сообщение “Mounted at /content/gdrive” (”Смонтировано в/содержимое/gdrive”), после чего можно просматривать содержимое диска из панели менеджера файлов.
Теперь взаимодействовать с Google Диск можно точно так же, как и с каталогом в среде Colab. Любые изменения, связанные с этим каталогом, будут сразу же отображаться на Google Диске, файлы которого вы можете читать как и любые другие.
Кроме того, можно даже напрямую делать запись из Colab на Google Диск, применяя обычные операции с файлами/каталогами.
! touch "/content/gdrive/My Drive/sample_file.txt"
Эта команда создаст файл на Google Диске, который отобразится на панели менеджера файлов при ее обновлении:
Обращение к Google Таблицам из Google Colab
Для обращения к Google Таблицам:
- Прежде всего, необходимо аутентифицировать аккаунт для соединения с Colab. С этой целью выполняем следующий код:
from google.colab import auth
auth.authenticate_user()
2. В результате получаем ссылку для аутентификации и открываем ее.
3. Выбираем аккаунт Google для соединения.
4. Разрешаем Google Cloud SDK доступ к вашему аккаунту Google.
5. Наконец, копируем отображаемый код, вставляем его в текстовое окно и нажимаем Enter.
Для взаимодействия с Google Таблицами потребуется импортировать предустановленную библиотеку gspread. Чтобы разрешить ей доступ к вашему аккаунту Google воспользуемся методом GoogleCredentials из предустановленной библиотеки oauth2client.client:
import gspread
from oauth2client.client import GoogleCredentials
gc = gspread.authorize(GoogleCredentials.get_application_default())
После выполнения кода в текущей рабочей директории будет создан файл adc.json с учетными данными, которые нужны gspread для получения доступа к вашему аккаунту Google.
Теперь создавайте или скачивайте Google таблицы напрямую из среды Colab.
Создание/обновление Google таблицы в Colab
- Создаем рабочую книгу с помощью метода create объекта gc :
wb = gc.create('demo')
2. Как только она готова, можно ее посмотреть на sheets.google.com.
3. Прежде всего, открываем рабочую книгу для записи в нее значений:
ws = gc.open('demo').sheet1
4. Затем выбираем ячейки для заполнения:
5. Таким образом мы создаем список ячеек с индексами (R1C1) и значениями (на данный момент пустыми). Можно изменить отдельные ячейки, обновив их атрибут значения:
6. Для обновления этих ячеек в рабочей таблице применяем метод update_cells :
7. Все изменения отображаются в вашей Google таблице.
Скачивание данных из Google таблицы
1. Открываем рабочую книгу с помощью метода open объекта gc :
wb = gc.open('demo')
2. Затем считываем все строки отдельной рабочей таблицы, задействуя метод get_all_values :
3. Для загрузки этих данных в датафрейм задействуем метод from_record объекта DataFrame :
Обращение к Google Cloud Storage (GCS) из Google Colab
Для работы с GCS необходим проект Google Cloud (GCP). Вы можете создавать и подключаться к корзинам GCS в Colab через предустановленную утилиту командной строки gsutil .
1. Сначала указываем ID проекта:
project_id = ''
2. Для доступа к GCS проводим аутентификацию вашего аккаунта Google:
from google.colab import auth
auth.authenticate_user()
3. Выполнив вышеуказанный код, получаем ссылку для аутентификации и открываем ее.
4. Выбираем аккаунт Google для соединения.
5. Разрешаем доступ Google Cloud SDK к вашему аккаунту Google.
6. Теперь копируем отображаемый код, вставляем его в текстовое окно и нажимаем Enter.
7. Затем настраиваем gsutil для работы с проектом:
! gcloud config set project
8. Вы можете создать корзину с помощью соответствующей команды mb (“make bucket”). У корзин GCP должны быть универсальные уникальные имена, поэтому воспользуемся предустановленной библиотекой uuid для создания такого рода ID:
import uuidbucket_name = f'sample-bucket-'
! gsutil mb gs://
9. Как только корзина готова, загружаем в нее файл из среды Colab:
! gsutil cp /tmp/to_upload.txt gs:///
! gsutil cp gs:///
По завершении скачивания файл отображается на панели менеджера файлов в Colab в указанном месте.
Обращение к AWS S3 из Google Colab
Для доступа к S3 из Colab потребуется создать аккаунт AWS, настроить IAM, а также сгенерировать ключ доступа и секретный ключ доступа. Необходимо также установить библиотеку awscli в среду Colab:
1. Устанавливаем библиотеку awscli:
! pip install awscli
2. После установки запускаем настройку AWS командой aws configure :
3. Вводим access_key и secret_access_key в текстовое окно и нажимаем Enter:
Теперь можно скачивать любые файлы из S3:
! aws s3 cp s3:// ./ --recursive
--exclude "*" --include
filepath_on_s3 позволяет указать один файл или подобрать несколько файлов по шаблону.
Вам придет уведомление о завершении скачивания, после чего файлы будут доступны в заданном месте для дальнейшего использования.
Для загрузки файла просто поменяйте местами аргументы источника и назначения:
! aws s3 cp ./ s3:// --recursive --exclude "*" --include
file_to_upload позволяет указать один файл или подобрать несколько файлов по шаблону.
Вы получите уведомление об окончании загрузки, и загруженные файлы будут доступны в корзине S3 в заданном каталоге: https://s3.console.aws.amazon.com/s3/buckets// /?region=
Обращение к датасетам Kaggle из Google Colab
Для скачивания датасетов из Kaggle требуется наличие аккаунта и API-токена.
- Для создания API-токена заходим в My Account, после чего — Create New API Token.
- Открываем файл kaggle.json и копируем его содержимое в виде < "username":"########", "key":"################################" >.
- Выполняем следующие команды в Colab:
! mkdir ~/.kaggle #создаем каталог .kaggle в корневой директории
! echo '' > ~/.kaggle/kaggle.json #записываем учетные данные kaggle API в kaggle.json
! chmod 600 ~/.kaggle/kaggle.json # устанавливаем разрешения
! pip install kaggle #устанавливаем библиотеку kaggle
4. После создания файла kaggle.json в Colab и установки библиотеки Kaggle приступаем к поиску датасета с помощью следующей команды:
! kaggle datasets list -s
5. Скачиваем нужный датасет с помощью команды:
! kaggle datasets download -d -p /content/kaggle/
Датасет будет загружен и доступен по указанному пути (в данном случае /content/kaggle/ ).
Обращение к базам данных MySQL из Google Colab
1. Для работы с реляционными базами данных необходимо импортировать предустановленную библиотеку sqlalchemy.
import sqlalchemy
2. Вводим данные для подключения и создаем движок:
HOSTNAME = 'ENTER_HOSTNAME'
USER = 'ENTER_USERNAME'
PASSWORD = 'ENTER_PASSWORD'
DATABASE = 'ENTER_DATABASE_NAME'
connection_string = f'mysql+pymysql://:@/'
engine = sqlalchemy.create_engine(connection_string)
3. Создаем SQL-запрос и загружаем его результаты в датафрейм с помощью pd.read_sql_query() :
query = f"SELECT * FROM ."
import pandas as pd
df = pd.read_sql_query(query, engine)
Ограничения Google Colab при работе с файлами
При работе с Colab важно помнить о том, что доступ к загружаемым файл ограничен по времени. Colab — это временная среда, в которой тайм-аут простоя составляет 90 минут, а абсолютный тайм-аут — 12 часов. Это значит, что отключение среды выполнения происходит в случае 90 минутного простоя или 12-ти часового использования. Такое отключение приводит к потери всех переменных, состояний, установленных пакетов и файлов, вследствие чего при повторном подключении вас ждет встреча с абсолютно новой и чистой средой.
Кроме того, дисковое пространство Colab ограничено 108 Гб, только 77 Гб из которых доступны пользователю. Этого объема достаточно для решения большинства задач, но вот при работе с крупными датасетами, например изображениями или видео, данное обстоятельство нельзя упускать из внимания.
Заключение
Google Colab — превосходный инструмент для тех, кто стремится обуздать мощь высокопроизводительных вычислительных ресурсов, таких как GPU, без оглядки на их стоимость.
В данной статье мы рассмотрели большинство способов, благодаря которым вы сможете максимально продуктивно работать с Google Colab, читая внешние файлы или данные в Google Colab и производя обратную запись из нее в эти внешние источники данных.
В зависимости от сценария использования или архитектуры данных вы можете запросто применять вышеописанные методы для подключения источника данных напрямую к Colab и приступать к программированию.
Полезные информационные ресурсы
- Getting Started with Google Colab | How to use Google Colab
- External data: Local Files, Drive, Sheets and Cloud Storage
- Importing Data to Google Colab — the CLEAN Way
- Get Started: 3 Ways to Load CSV files into Colab by A. Apte
- Downloading Datasets into Google Drive via Google Colab by Kevin Luk
- ИИ: решение неверно поставленных задач
- Будущее практического применения чат-ботов
- Межорганизационный обмен данными