Как установить python-googleapi в Ubuntu / Debian
Для установки python-googleapi в Ubuntu / Linux Mint / Debian, введите в Терминал :
sudo apt update
sudo apt install python-googleapi

Подробная информация о пакете:
Клиентская библиотека API Google API — Python 2.x
python install module apiclient
New to python, and trying to install a module «apiclient» since my ide pycharm does not recognize that import:
from apiclient.discovery import build - pip install apiclient
- download manually the package from
/Users/nirregev/anaconda/bin/google-api-python-client-1.5.0 and ran this on my mac terminal python setup.py install but still pycharm does not recognize this module. According to pycharm I have the following interpreters installed:
/Library/Frameworks/Python.framework/Versions/3.5/bin/python3.5 /Users/nirregev/anaconda/bin/python /System/Library/Frameworks/Python.framework/Versions/2.7/bin/python2.7 2,642 21 21 silver badges 25 25 bronze badges
asked Mar 14, 2016 at 8:28
135 1 1 gold badge 2 2 silver badges 7 7 bronze badges
importantly, when I try to import this in ipython , it work fine
Mar 14, 2016 at 8:55
5 Answers 5
Try this:
sudo pip install --upgrade google-api-python-client OR
Make sure you only have google-api-python-client installed. If you have apiclient installed, it will cause a collision. So, run the following:
pip install --force-reinstall google-api-python-client 1 1 1 silver badge
answered Mar 14, 2016 at 8:34
Kaleem Ullah Kaleem Ullah
6,869 3 3 gold badges 42 42 silver badges 47 47 bronze badges
does it matter from which location in the file system I will run pip ?
Mar 14, 2016 at 8:49
I just ran these 2 pip commands and it says «requirement already met»
Mar 14, 2016 at 8:51
yes it matter if you use virtual environments. better to run pip in project directory. and for more information please click Answer Source. this will help you more.
Mar 14, 2016 at 10:04
/Users/nirregev/anaconda/bin/python /Users/nirregev/PycharmProjects/test/PrepareTrainingData.py Traceback (most recent call last): File «/Users/nirregev/PycharmProjects/test/PrepareTrainingData.py», line 3, in
Mar 14, 2016 at 10:19
look over here Due to an issue around in-place upgrades for Python packages, it’s not possible to do an upgrade from version 1.2 to 1.3. Instead, setup.py attempts to detect this and prevents it. Simply remove the previous version and reinstall to fix this.
Mar 14, 2016 at 10:44
I ran into this problem and had a tough time figuring it out. In the end, this worked for me:
pip install google-api-python-client==1.5.3
Before doing this, I had version 1.6.2 installed. What I think is going on is that later versions of google-api-python-client dropped the apiclient in favor of the googleapiclient alias; which is an issue because some packages (e.g. airflow) still use that apiclient.discovery import.
Hope this helps.
answered May 24, 2017 at 19:05
XtremeCurling XtremeCurling
141 2 2 bronze badges
If you have python3 installed somewhere and you are to install apiclient, it may be installing it in your python3 directory. I had the same problem and when I uninstalled python3 my program ran smoothly.
answered Mar 24, 2017 at 20:08
11 1 1 bronze badge
If you have got both python 2 and python 3 and you’re trying to use python 2 for this purpose try the following: sudo pip2 install google-api-python-client==1.5.3 . This worked for me.
answered Jun 28, 2017 at 2:34
Aanchal Adhikari Aanchal Adhikari
303 4 4 silver badges 12 12 bronze badges
I am on Mac, using brew’s python, and this worked for me:
1 — As suggested by others, install the API client using pip:
sudo pip install --upgrade google-api-python-client 2 — Make sure you are calling the library in your code as googleapiclient , and not as apiclient , which is deprecated.
3 — Tell Python to look for packages in the pip folder:
export PYTHONPATH=/usr/local/lib/python2.7/site-packages To make it permanent, add the above line to either your .profile or .bash_profile file in your $HOME .
Работаем с API Google Drive с помощью Python
Решил написать достаточно подробную инструкцию о том как работать с API Google Drive v3 с помощью клиентской библиотеки Google API для Python. Статья будет полезна тем, кому приходится часто работать с документами в Google Drive: скачивать и загружать новые документы, удалять файлы, создавать папки.
Также я покажу пример того как можно с помощью API скачивать файлы Google Sheets в формате Excel, или наоборот: заливать в Google Drive файл Excel в виде документа Google Sheets.
Использование API Google Drive может быть полезным для автоматизации различной рутины, связанной с отчетностью. Например, я использую его для того, чтобы по расписанию загружать заранее подготовленные отчеты в папку Google Drive, к которой есть доступ у конечных потребителей отчетов.
Все примеры на Python 3.
Создание сервисного аккаунта и получение ключа
Прежде всего создаем сервисный аккаунт в консоли Google Cloud и для email сервисного аккаунта открываем доступ на редактирование необходимых папок. Не забудьте добавить в папку файлы, если их там нет, потому что файл нам понадобится, когда мы будем выполнять первый пример — скачивание файлов из Google Drive.
Я записал небольшой скринкаст, чтобы показать как получить ключ для сервисного аккаунта в формате JSON.
Установка клиентской библиотеки Google API и получение доступа к API
Сначала устанавливаем клиентскую библиотеку Google API для Python
pip install --upgrade google-api-python-clientДальше импортируем нужные модули или отдельные функции из библиотек.
Ниже будет небольшое описание импортируемых модулей. Это для тех кто хочет понимать, что импортирует, но большинство просто может скопировать импорты и вставить в ноутбук 🙂
- Модуль service_account из google.oauth2 понадобится нам для авторизации с помощью сервисного аккаунта.
- Классы MediaIoBaseDownload и MediaFileUpload, как ясно из названий, пригодятся, чтобы скачать или загрузить файлы. Эти классы импортируются из googleapiclient.http
- Функция build из googleapiclient.discovery позволяет создать ресурс для обращения к API, то есть это некая абстракция над REST API Drive, чтобы удобнее обращаться к методам API.
from google.oauth2 import service_account from googleapiclient.http import MediaIoBaseDownload,MediaFileUpload from googleapiclient.discovery import build import pprint import io pp = pprint.PrettyPrinter(indent=4)Указываем Scopes. Scopes — это перечень возможностей, которыми будет обладать сервис, созданный в скрипте. Ниже приведены Scopes, которые относятся к API Google Drive (из официальной документации):
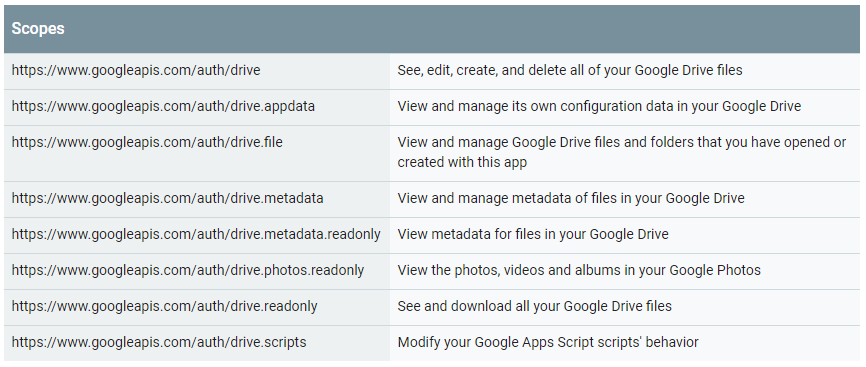
Как видно, разные Scope предоставляют разный уровень доступа к данным. Нас интересует Scope «https://www.googleapis.com/auth/drive», который позволяет просматривать, редактировать, удалять или создавать файлы на Google Диске.
Также указываем в переменной SERVICE_ACCOUNT_FILE путь к файлу с ключами сервисного аккаунта.
SCOPES = ['https://www.googleapis.com/auth/drive'] SERVICE_ACCOUNT_FILE = '/home/makarov/Google Drive Test-fc4f3aea4d98.json'Создаем Credentials (учетные данные), указав путь к сервисному аккаунту, а также заданные Scopes. А затем создаем сервис, который будет использовать 3ю версию REST API Google Drive, отправляя запросы из-под учетных данных credentials.
credentials = service_account.Credentials.from_service_account_file( SERVICE_ACCOUNT_FILE, scopes=SCOPES) service = build('drive', 'v3', credentials=credentials)Получение списка файлов
Теперь можно получить список файлов и папок, к которым имеет доступ сервис. Для этого выполним запрос list, выдающий список файлов, со следующими параметрами:
- pageSize — количество результатов выдачи. Можете смело ставить максимальное значение 1000. У меня стоит 10 результатов, чтобы показать как быть, когда нужно получить результаты по следующей страницы результатов
- параметр files() в fields — параметр, указывающий, что нужно возвращать список файлов, где в скобках указан список полей для файлов, которые нужно показывать в результатах выдачи. Со всеми возможными полями можно познакомиться в документации (https://developers.google.com/drive/api/v3/reference/files) в разделе «Valid fields for files.list». У меня указаны поля для файлов: id (идентификатор файла в Drive), name (имя) и mimeType (тип файла). Чуть дальше мы рассмотрим пример запроса с большим количеством полей
- nextPageToken в fields — это токен следующей страницы, если все результаты не помещаются в один ответ
results = service.files().list(pageSize=10, fields="nextPageToken, files(id, name, mimeType)").execute()Получили вот такие результаты:
pp.pprint(results)
print(len(results.get('files')))Получив из результатов nextPageToken мы можем передать его в следущий запрос в параметре pageToken, чтобы получить результаты следующей страницы. Если в результатах будет nextPageToken, это значит, что есть ещё одна или несколько страниц с результатами
nextPageToken = results.get('nextPageToken') results_for_next_page = service.files().list(pageSize=10, fields="nextPageToken, files(id, name, mimeType)", pageToken=nextPageToken).execute() print (results_for_next_page.get('nextPageToken'))
Таким образом, мы можем сделать цикл, который будет выполняться до тех пор, пока в результатах ответа есть nextPageToken. Внутри цикла будем выполнять запрос для получения результатов страницы и сохранять результаты к первым полученным результатам
results = service.files().list(pageSize=10, fields="nextPageToken, files(id, name, mimeType)").execute() nextPageToken = results.get('nextPageToken') while nextPageToken: nextPage = service.files().list(pageSize=10, fields="nextPageToken, files(id, name, mimeType, parents)", pageToken=nextPageToken).execute() nextPageToken = nextPage.get('nextPageToken') results['files'] = results['files'] + nextPage['files'] print(len(results.get('files')))Дальше давайте рассмотрим какие ещё поля можно использовать для списка возвращаемых файлов. Как я уже писал выше, со всеми полями можно ознакомиться по ссылке. Давайте рассмотрим самые полезные из них:
- parents — ID папки, в которой расположен файл/подпапка
- createdTime — дата создания файла/папки
- permissions — перечень прав доступа к файлу
- quotaBytesUsed — сколько места от квоты хранилища занимает файл (в байтах)
results = service.files().list( pageSize=10, fields="nextPageToken, files(id, name, mimeType, parents, createdTime, permissions, quotaBytesUsed)").execute()Отобразим один файл из результатов с расширенным списком полей. Как видно permissions содержит информацию о двух юзерах, один из которых имеет role = owner, то есть владелец файла, а другой с role = writer, то есть имеет право записи.
pp.pprint(results.get('files')[0])
Очень удобная штука, позволяющая сократить количество результатов в запросе, чтобы получать только то, что действительно нужно — это возможность задать параметры поиска для файлов. Например, мы можем задать в какой папке искать файлы, зная её id:
results = service.files().list( pageSize=5, fields="nextPageToken, files(id, name, mimeType, parents, createdTime)", q="'1mCCK9QGQxLDED8_pgq2dyvkmGRXhWEtJ' in parents").execute() pp.pprint(results['files'])
С синтаксисом поисковых запросов можно ознакомиться в документации. Ещё один удобный способ поиска нужных файлов — по имени. Вот пример запроса, где мы ищем все файлы, содержащие в названии «data»:
results = service.files().list( pageSize=10, fields="nextPageToken, files(id, name, mimeType, parents, createdTime)", q="name contains 'data'").execute() pp.pprint(results['files'])
Условия поиска можно комбинировать. Возьмем условие поиска в папке и совместим с условием поиска по названию:
results = service.files().list( pageSize=10, fields="nextPageToken, files(id, name, mimeType, parents, createdTime)", q="'1uuecd6ndiZlj3d9dSVeZeKyEmEkC7qyr' in parents and name contains 'data'").execute() pp.pprint(results['files'])
Скачивание файлов из Google Drive
Теперь рассмотрим как скачивать файлы из Google Drive. Для этого нам понадобится создать запрос request для получения файла. После этого задаем интерфейс fh для записи в файл с помощью библиотеки io, указав в filename название файла (таким образом, можно сохранять файлы из Google Drive сразу с другим названием). Затем создаем экземпляр класса MediaIoBaseDownload, передав наш интерфейс для записи файла fh и запрос для скачивания файла request. Следующим шагом скачиваем файл по небольшим кусочкам (чанкам) с помощью метода next_chunk.
Если из предыдущего описания вам мало что понятно, не запаривайтесь, просто укажите свой file_id и filename, и всё у вас будет в порядке.
file_id = '1HKC4U1BMJTsonlYJhUKzM-ygrIVGzdBr' request = service.files().get_media(fileId=file_id) filename = '/home/makarov/File.csv' fh = io.FileIO(filename, 'wb') downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() print ("Download %d%%." % int(status.progress() * 100))Файлы Google Sheets или Google Docs можно конвертировать в другие форматы, указав параметр mimeType в функции export_media (обратите внимание, что в предыдущем примере скачивания файла мы использоали другую функцию get_media). Например, файл Google Sheets можно конвертировать и скачать в виде файла Excel.
file_id = '10MM2f3V98wTu7GsoZSxzr9hkTGYvq_Jfb2HACvB9KjE' request = service.files().export_media(fileId=file_id, mimeType='application/vnd.openxmlformats-officedocument.spreadsheetml.sheet') filename = '/home/makarov/Sheet.xlsx' fh = io.FileIO(filename, 'wb') downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() print ("Download %d%%." % int(status.progress() * 100))Затем скачанный файл можно загнать в датафрейм. Это достаточно простой способ получить данные из Google Sheet в pandas-dataframe, но есть и другие способы, например, воспользоваться библиотекой gspread.
import pandas as pd df = pd.read_excel('/home/makarov/Sheet.xlsx') df.head(5)
Загрузка файлов и удаление в Google Drive
Рассмотрим простой пример загрузки файла в папку. Во-первых, нужно указать folder_id — id папки (его можно получить в адресной строке браузера, зайдя в папку, либо получив все файлы и папки методом list). Также нужно указать название name, с которым файл загрузится на Google Drive. Это название может быть отличным от исходного названия файла. Параметры folder_id и name передаем в словарь file_metadata, в котором задаются метаданные загружаемого файла. В переменной file_path указываем путь к файлу. Создаем объект media, в котором будет указание по какому пути находится загружаемый файл, а также указание, что мы будем использовать возобновляемую загрузку, что позволит нам загружать большие файлы. Google рекомендует использовать этот тип загрузки для файлов больше 5 мегабайт. Затем выполняем функцию create, которая позволит загрузить файл на Google Drive.
folder_id = '1mCCK9QGQxLDED8_pgq2dyvkmGRXhWEtJ' name = 'Script_2.py' file_path = '/home/makarov/Script.py' file_metadata = < 'name': name, 'parents': [folder_id] >media = MediaFileUpload(file_path, resumable=True) r = service.files().create(body=file_metadata, media_body=media, fields='id').execute() pp.pprint(r)
Как видно выше, при вызове функции create возвращается id созданного файла. Можно удалить файл, вызвав функцию delete. Но мы этого делать не будет так как файл понадобится в следующем примере
service.files().delete(fileId='18Wwvuye8dOjCZfJzGf45yQvB87Lazbzu').execute()Сервисный аккаунт может удалить ли те файлы, которые были с помощью него созданы. Таким образом, даже если у сервисного аккаунта есть доступ на редактирование папки, то он не может удалить файлы, созданные другими пользователями. Понять что файл был создан помощью сервисного аккаунта можно задав поисковое условие с указанием email нашего сервисного аккаунта. Узнать email сервисного аккаунта можно вызвав атрибут signer_email у объекта credentials
print (credentials.signer_email)
results = service.files().list( pageSize=10, fields="nextPageToken, files(id, name, mimeType, parents, createdTime)", q="'namby-pamby@tensile-verve-232214.iam.gserviceaccount.com' in owners").execute() pp.pprint(results['files'][0:3])
Дальше — больше. С помощью API Google Drive мы можем загрузить файл с определенным mimeType, чтобы Drive понял к какому типу относится файл и предложил соответствующее приложение для его открытия.
folder_id = '1mCCK9QGQxLDED8_pgq2dyvkmGRXhWEtJ' name = 'Sample data.csv' file_path = '/home/makarov/sample_data_1.csv' file_metadata = < 'name': name, 'mimeType': 'text/csv', 'parents': [folder_id] >media = MediaFileUpload(file_path, mimetype='text/csv', resumable=True) r = service.files().create(body=file_metadata, media_body=media, fields='id').execute() pp.pprint(r)
Но ещё более классная возможность — это загрузить файл одного типа с конвертацией в другой тип. Таким образом, мы можем залить csv файл из примера выше, указав для него тип Google Sheets. Это позволит сразу же конвертировать файл для открытия в Гугл Таблицах. Для этого надо в словаре file_metadata указать mimeType «application/vnd.google-apps.spreadsheet».
folder_id = '1mCCK9QGQxLDED8_pgq2dyvkmGRXhWEtJ' name = 'Sheet from csv' file_path = '/home/makarov/notebooks/sample_data_1.csv' file_metadata = < 'name': name, 'mimeType': 'application/vnd.google-apps.spreadsheet', 'parents': [folder_id] >media = MediaFileUpload(file_path, mimetype='text/csv', resumable=True) r = service.files().create(body=file_metadata, media_body=media, fields='id').execute() pp.pprint(r)
Таким образом, загруженный нами CSV-файл будет доступен как Гугл Таблица:

Ещё одна часто необходимая функция — это создание папок. Тут всё просто, создание папки также делается с помощью метода create, надо только в file_metadata указать mimeType «application/vnd.google-apps.folder»
folder_id = '1uuecd6ndiZlj3d9dSVeZeKyEmEkC7qyr' name = 'New Folder' file_metadata = < 'name': name, 'mimeType': 'application/vnd.google-apps.folder', 'parents': [folder_id] >r = service.files().create(body=file_metadata, fields='id').execute() pp.pprint(r)
Заключение
Все содержимое этой статьи также представлено в виде ноутбука для Jupyter Notebook.
В этой статье мы рассмотрели лишь немногие возможности API Google Drive, но одни из самых необходимых:
- Просмотр списка файлов
- Скачивание документов из Google Drive (в том числе, скачивание с конвертацией, например, документов Google Sheets в формате Excel)
- Загрузка документов в Google Drive (также как и в случае со скачиванием, с возможностью конвертации в нативные форматы Google Drive)
- Удаление файлов
- Создание папок
Вступайте в группу на Facebook и подписывайтесь на мой канал в Telegram, там публикуются интересные статьи про анализ данных и не только.
Введение в Google Analytics API: краткое руководство по Python для установленных приложений
Оптимизируйте свои подборки Сохраняйте и классифицируйте контент в соответствии со своими настройками.
В этом руководстве описывается, как получить доступ к аккаунту Google Analytics, отправлять запросы в API этого сервиса, обрабатывать ответы и извлекать результаты обработки с применением Core Reporting API 3.0, Management API 3.0 и OAuth 2.0.
Примечание. Цель этих кратких руководств – помочь пользователю выполнить авторизацию API с помощью клиентских библиотек Google API. Поскольку эти библиотеки постоянно обновляются, информации о последних изменениях здесь может не быть. Если вы не нашли нужные сведения, ознакомьтесь с документацией по клиентским библиотекам и справочной информацией.
Шаг 1. Включите Google Analytics API
Перед началом работы с Google Analytics API используйте инструмент настройки, чтобы создать проект в Google API Console, включить API и зарегистрировать учетные данные.
Чтобы создать идентификатор веб-клиента или клиента установленного приложения, нужно указать название продукта в окне запроса доступа. Если вы ещё не указали название, вам будет предложено это сделать.
Создайте идентификатор клиента
Откройте раздел «Учетные данные» и выполните следующие действия:
- Нажмите Создать учетные данные и выберите Идентификатор клиента OAuth.
- В разделе Тип приложения выберите Другие типы.
- Введите название.
- Нажмите кнопку Создать.
Выберите созданные учетные данные и нажмите Скачать файл JSON. Сохраните файл как client_secrets.json . Он понадобится вам позже.
Шаг 2. Установите клиентскую библиотеку Google
Вы можете использовать менеджер пакетов или скачать и установить клиентскую библиотеку для Python вручную:
pip
Рекомендуется использовать pip, специальный инструмент для установки пакетов Python:
sudo pip install --upgrade google-api-python-client
Setuptools
Можно также использовать инструмент easy_install, входящий в пакет setuptools:
sudo easy_install --upgrade google-api-python-client
Установка вручную
Загрузите последнюю клиентскую библиотеку для Python, распакуйте код и выполните его:
sudo python setup.py install
Возможно, вам придется вызвать команду с помощью прав администратора ( sudo ), чтобы установить Python в систему.
Шаг 3. Настройте пример
Вам нужно создать файл HelloAnalytics.py с кодом этого примера.
- Скопируйте или скачайте приведенный ниже исходный код для HelloAnalytics.py .
- Переместите ранее загруженный файл client_secrets.json в директорию, содержащую код образца.
"""A simple example of how to access the Google Analytics API.""" import argparse from apiclient.discovery import build import httplib2 from oauth2client import client from oauth2client import file from oauth2client import tools def get_service(api_name, api_version, scope, client_secrets_path): """Get a service that communicates to a Google API. Args: api_name: string The name of the api to connect to. api_version: string The api version to connect to. scope: A list of strings representing the auth scopes to authorize for the connection. client_secrets_path: string A path to a valid client secrets file. Returns: A service that is connected to the specified API. """ # Parse command-line arguments. parser = argparse.ArgumentParser( formatter_class=argparse.RawDescriptionHelpFormatter, parents=[tools.argparser]) flags = parser.parse_args([]) # Set up a Flow object to be used if we need to authenticate. flow = client.flow_from_clientsecrets( client_secrets_path, scope=scope, message=tools.message_if_missing(client_secrets_path)) # Prepare credentials, and authorize HTTP object with them. # If the credentials don't exist or are invalid run through the native client # flow. The Storage object will ensure that if successful the good # credentials will get written back to a file. storage = file.Storage(api_name + '.dat') credentials = storage.get() if credentials is None or credentials.invalid: credentials = tools.run_flow(flow, storage, flags) http = credentials.authorize(http=httplib2.Http()) # Build the service object. service = build(api_name, api_version, http=http) return service def get_first_profile_id(service): # Use the Analytics service object to get the first profile id. # Get a list of all Google Analytics accounts for the authorized user. accounts = service.management().accounts().list().execute() if accounts.get('items'): # Get the first Google Analytics account. account = accounts.get('items')[0].get('id') # Get a list of all the properties for the first account. properties = service.management().webproperties().list( accountId=account).execute() if properties.get('items'): # Get the first property id. property = properties.get('items')[0].get('id') # Get a list of all views (profiles) for the first property. profiles = service.management().profiles().list( accountId=account, webPropertyId=property).execute() if profiles.get('items'): # return the first view (profile) id. return profiles.get('items')[0].get('id') return None def get_results(service, profile_id): # Use the Analytics Service Object to query the Core Reporting API # for the number of sessions in the past seven days. return service.data().ga().get( ids='ga:' + profile_id, start_date='7daysAgo', end_date='today', metrics='ga:sessions').execute() def print_results(results): # Print data nicely for the user. if results: print 'View (Profile): %s' % results.get('profileInfo').get('profileName') print 'Total Sessions: %s' % results.get('rows')[0][0] else: print 'No results found' def main(): # Define the auth scopes to request. scope = ['https://www.googleapis.com/auth/analytics.readonly'] # Authenticate and construct service. service = get_service('analytics', 'v3', scope, 'client_secrets.json') profile = get_first_profile_id(service) print_results(get_results(service, profile)) if __name__ == '__main__': main()
Шаг 4. Запустите образец
После того как вы включили Google Analytics API, установили клиентскую библиотеку Google API для Python и настроили код примера, он готов к запуску.
Запустите образец, используя следующий код:
python HelloAnalytics.py
- Приложение загрузит страницу авторизации в браузере.
- Если вы ещё не вошли в аккаунт Google, вам будет предложено это сделать. Если вы вошли в несколько аккаунтов Google, вы должны будете выбрать для авторизации один из них.
После выполнения всех шагов образец выведет имя первого профиля авторизованного пользователя в Google Analytics и количество сеансов за последние семь дней.
Примечание. Для успешного запуска примера нужно иметь по крайней мере один ресурс и профиль Google Analytics.
Имея авторизованный служебный объект Analytics, вы можете запустить любой из примеров кода, приведенных в справочных материалах по Management API. Например, можно попробовать изменить код, чтобы использовать метод accountSummaries.list.
Устранение неполадок
AttributeError: ‘Module_six_moves_urllib_parse’ object has no attribute ‘urlparse’
Эта ошибка может возникать в Mac OS X, когда установка по умолчанию модуля six (зависимого компонента этой библиотеки) завершается до того, как установлен инструмент pip. Чтобы устранить проблему, добавьте место установки инструмента pip в системную переменную среды PYTHONPATH :
-
Определите место установки инструмента pip с помощью следующей команды:
pip show six | grep "Location:" | cut -d " " -f2 export PYTHONPATH=$PYTHONPATH:
source ~/.bashrc Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons «С указанием авторства 4.0», а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2019-01-23 UTC.