Как освободиться от Яндекс-дзена и прилипшей строки в поиске
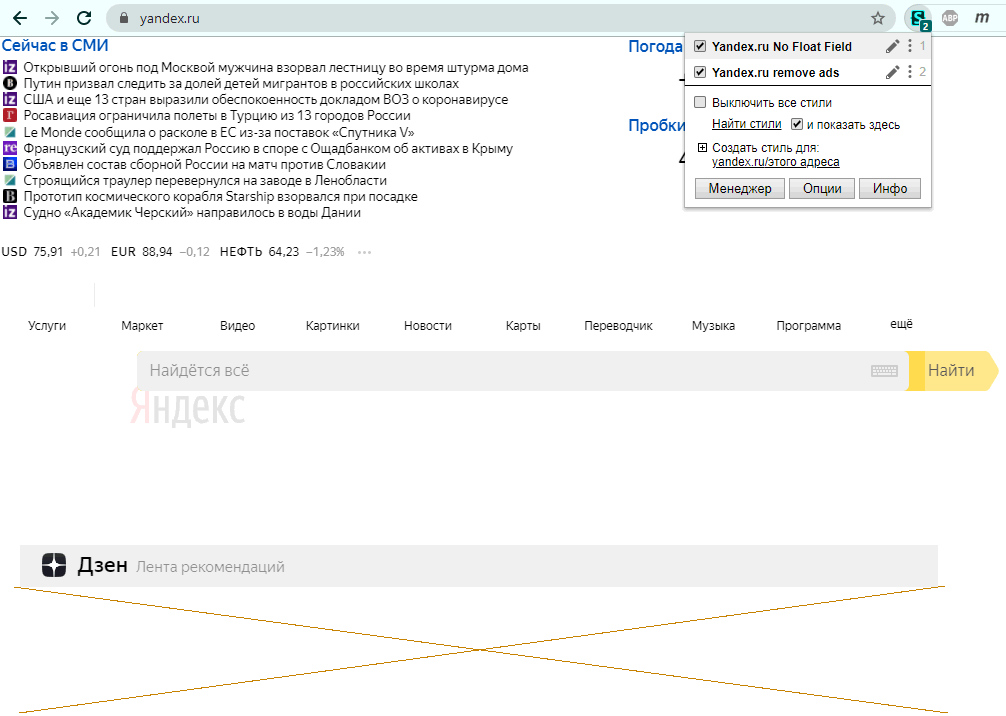
Речь пойдёт о юзер-стилях, помогающих программистам не отвлекаться на Дзен и не закрывать часть окна браузера поисковой строкой Яндекса.
Нет сомнения, что читатели сайта всё это знают, но не часто реагируют на желания Яндекса улучшить жизнь большинства. Я тоже, хотя когда-то писал эти стили для себя, уже почти год не реагировал на ребрендинг Главной Яндекса, когда окончательно убрали настраиваемые Виджеты и ввели Дзен. Но сегодня навёл некоторый порядок (когда окончательно стало понятно, что там особо нечего смотреть, а если и есть, то не в режиме рекламы), чтобы Яндексом было эффективнее пользоваться).
Появление Дзена и самозапускающихся видео изрядно мешает программисту или любому исследователю, который пришёл на сайт за запросом, а тут — картинки и видео начинают показывать своё и отбирают с таким трудом достигнутое сосредоточение на работе ) или просто время.
Дзен-баннеры под поиском
Кому-то — наоборот, видео и реклама привлечёт свежие ассоциации и обогатит вид скудной поисковой строки, но мы сейчас — про сосредоточенного на своей задаче пользователя. Что ему от Главной страницы Яндекса надо?
- поисковая строка;
- контекстные подсказки под ней;
- без анимаций и баннеров вокруг;
- конечно, без Дзена.
Для решения этой задачи в десктопном браузере нужно установить юзер-стиль «Yandex remove ads» с сайта userstyles.org. Прежде чем его установить, в браузере нужно установить расширение (webextension) Stylus для Хрома (Яндекса, Оперы, Вивальди, других), для Firefox. И немного запастись терпением… Почему?
К сожалению, он с трудом справляется с потоком посетителей, всегда очень тормозит и может открыть страницу за 1-2 минуты. Но сайт полезный, старый, собравший в себе многие юзерстили, и лучшего хостинга для них пока не придумали — он уже последних года 3 в таком состоянии.
Если удастся этот стиль поставить, будут наблюдаться решения таких вопросов:
- Двигающаяся карусель из текстовых новостей показана статически, без анимаций,
- Между строчками есть пустоты, потому что там иногда появляются баннеры, вёрстка которых периодически меняется и меняет привычный расклад полезных блоков. Чтобы изменения наблюдались с меньшими последствиями, место для баннеров сохранено.
- На страницах картинок, погоды и новостей тоже по возможности убраны лишние элементы,
- Дзен не отображается, кроме заголовка, при наведении мыши на который весь Дзен виден, если с него продолжать не сводить мышку. Впрочем иногда бывает, что Яндекс не выдаёт заголовок, и тогда наводить мышь не на что. «Беда» не большая — во множестве ссылок яндексовых порталов по ссылке «ещё» с Главной есть отдельная ссылка на Дзен-портал, там стили ничего не давят и там Дзену — «самое место».
- На страницу поиска ходят для поиска, поэтому на Главной видим его, бледный логотип (или дудлы) и 4 виджета с новостями, погодой, валютами и пробками.
- Если надо залогиниться в Яндекс, эти стили временно нужно отключить, потом включить после логина. Не настраивается красивая форма входа, потому что Яндекс, бывает, слишком часто меняет вёрстку, портя исправляющие стили. Поэтому лучше их не иметь.
- Код стилей имеет долгое наследие различных старых вариантов версток, которые не удаляются по причине, что неизвестно, когда старые варианты у компании становятся полностью забытыми. А кода прибавляют они сравнительно немного.
- Тот или другой стиль на лету выключается или включается через значок расширения в тулбаре (как на фото вверху над катом), не требуя перезагрузки страницы и никак не влияя на её содержимое — можно манипулировать юзерстилями, не боясь потерять что-то набранное на странице.
Как не закрывать часть окна плавающей строкой поиска?
Для этой задачи есть другой юзерстиль — «Yandex No Float Field». С ним верхнее поле с поисковой строкой перестаёт плавать и закрывать часть экрана, а плавает только логотип слева, при наведении на который появляется поисковая строка (без прокрутки вверх).
Дополнительно, этот стиль делает список подсказок чуть прозрачным и не полностью перекрывающим полезное содержание страницы. А 3 ссылки на поиск по Гуглу, Bing и Mail поставлены повыше, не в самом низу страницы.
В итоге, видим, что при желании одними стилями можно улучшить вид поисковика, засоряющего интерфейс визуальными эффектами. Кроме названных 2 стилей, есть решения разных авторов в виде юзерскриптов с подавлением рекламных баннеров, в том числе, специфических для данного сайта.
Хотелось бы, конечно, видеть эти удобства в функциях самого сайта Яндекс, чтобы в десктопном и в мобильном дизайнах не требовалось бы пользоваться расширениями для улучшения его прямых функций поиска. К примеру, интерфейс Гугла при похожих возможностях — проще и практичнее. (Хотя по прилипшей строке тоже пришлось позаниматься и с ним.)
Как закрыть «лишние» страницы сайта от индексации в поисковиках: 3 способа и пошаговая инструкция
Термин «Индексация» означает действия поисковых роботов, в результате которых они «считывают» и сохраняют в базы Яндекса и Гугла содержимое сайта: картинки, видеоролики и другие вебматериалы.
Когда в индекс попадают только полезные материалы, в поисковой выдаче по нужным запросам будут выходить только релевантные веб-ресурсы. Частая ошибка при оптимизации сайта — не исключать страницы, которые не следует показывать в результатах поиска. В этой статье покажем, как скрывать их от индексации и рассмотрим все способы.
Почему нельзя индексировать весь сайт целиком
Во-первых, для Интернет-пользователей наличие в выдаче бесполезного контента затрудняет поиск нужной информации, как следствие — поисковики понижают сайты с «ненужными» страницами в выдаче.
Во-вторых, есть требование поисковиков к уникальности контента. Когда какая-либо информация дублируется на разных веб-страницах — для роботов она уже не уникальная, поэтому без настройки запрета не обойтись, если:
- У вас версия сайта для мобайла на отдельном домене
- Вы тестируете сайт на другом домене — поисковые роботы также могут принять одинаковые страницы за дубликаты.
В-третьих, у поисковиков есть ограничение по количеству веба для сканирования, для каждого ресурса — своя цифра, она называется краулинговый бюджет. Когда он уходит на редиректы, спам и прочую фигню, его может не хватить на действительно ценные материалы.
В-четвертых, когда вы кардинально меняете дизайн и структуру, лучше скрыть сайт, чтобы он за это время не потерял позиции в поиске из-за низких показателей юзабилити.
Что нужно закрывать от индексации
Закрыть от индексации рекомендуем следующие страницы.
Дубли
Это страницы сайта, единственное различие которых — URL-адреса. Когда несколько одинаковых или почти одинаковых веб-страниц попадают в индексирование, они конкурируют между собой, в результате чего сайт серьезно теряет позиции в выдаче.
Во всех случаях, когда контент открывается не по одному URL-адресу, а по нескольким, система считает его дублем и пессимизирует сайт, на котором находится такой контент.
Кроме того, это сильно влияет и на скорость обхода сайта программами, так как нужно просмотреть уже не одну страницу, а несколько, то есть краулинговый бюджет тратится не по назначению.
Документы для скачивания
Примеры: политика конфиденциальности, обучающие материалы, руководства.
Когда заголовки документов появляются в выдаче выше, чем веб-страницы с ответом на тот же запрос, это плохая идея. Человек может скачать документ и не пойти дальше изучать контент.
Веб в разработке
Они пока не решают задачи пользователей и не готовы к конкуренции — ни к чему показывать их поисковым роботам, иначе рейтинг сайта в поисковиках может упасть.
Технические страницы
К ним относится всё, что относится к служебным целям, но не информативно с точки зрения SEO для пользователей. Примеры:
- Результаты поиска по сайту
- Формы связи и регистрации
- Личный кабинет
- Корзина пользователя
- Пагинация — с ней не всё однозначно, поэтому этот вид разберем отдельно
Как проверить, корректно ли работает запрет индексации
Прежде чем переходить к инструкции, важный момент: ни один способ не гарантирует на 100%, что поисковые роботы не будут игнорировать запрет. Поэтому всегда проверяйте результат в панели веб-мастеров Google Search Console и Яндекс.Вебмастер.
В первом инструменте при настройке запрета должен быть статус, как на скриншоте ниже:
В Вебмастере Яндекса зайдите в раздел «Индексирование» и проверьте статус любого URL.
Скрыть от сканирования можно как отдельные веб-страницы, фрагменты и разделы сайта, так и весь сайт целиком. Далее рассмотрим все способы по порядку и разберем, когда какой лучше применять.
Как закрыть страницы от индексации в robots.txt
Robots.txt — самый распространенный способ. Вы используете текстовый файл под этим именем, чтобы задать в нем веб-страницы, которые поисковые программы будут посещать в ходе индексации и исключить те, которые посещать не нужно. То есть для поисковиков файл robots служит ориентиром.
Шаг 1. Найдите или создайте robots.txt
Первое, что нужно найти — корневую папку сайта. Именно туда загружаются все каталоги и файлы сайта. Для этого зайдите в панель управления хостингом, там вы увидите нужный домен и в блоке «Корневая директория» — путь.
Когда файла в корневой папке нет, это значит, что для поисковиков нет ограничений по индексации, и в выдачу может попасть какая угодно страница с сайта. Чтобы этого не допустить, откройте на компьютере пустой документ в формате txt, сохраните под этим именем и залейте.
Путь до домена — тот же. В панели управления хостингом нажмите кнопки «Каталог» — «Закачать» и загрузите, который создали.
Шаг 2. Пропишите список роботов, для которых работает запрет
Первая строка в документе будет такой, если вы хотите запретить индексацию для всех без исключения:
Если, например, только Яндекс — такой:
Шаг 3. Примените директиву Disallow и укажите адрес
Через двоеточие напишите адрес. Выглядит это примерно так:
В этой схеме catalog означает раздел, page — адрес.
Чтобы запретить сканирование для всех поисковиков, кроме какого-то определенного, например, Гугла, задайте это в четырех строках подряд:
Директива Allow позволяет Гуглу индексировать сайт.
Чтобы запретить индексацию целого раздела, нужно прописать его название со слешами:
Чтобы поисковые роботы не посещали сайт целиком, в файле пропишите такие строки:
Мнение экспертов
Отчасти директивы Crawl-delay потеряли свою актуальность. Максим Ворошин, SEO-специалист MKlines, назвал случаи, когда условие в robots.txt может не сработать. Для Яндекса оно обязательное лишь отчасти: если на закрытый материал ведут несколько ссылок или идет трафик, есть вероятность, что он появится в индексе поисковика. Что касается системы Гугла — для появления закрытой страницы в поиске достаточно того, чтобы на неё вело много ссылок.
По опыту эксперта Алены Рыбиной, блогера SEOFY, Яндексу безразлично, как закрывать страницы от индекса — они в любом случае пропадут из базы. Ситуация, когда Гугл индексирует, несмотря на robots.txt, бывает не часто — как правило, поисковик придерживается инструкций индексации. Бывали и исключения, например, когда индексировались страницы плагинов и с динамическими параметрами, несмотря на то, что в настройке не было ошибок.
При этом, как отмечает Анастасия Шестова, руководитель направления поискового продвижения ИнтерЛабс, обычно количество таких страниц невелико и не является значимой проблемой.
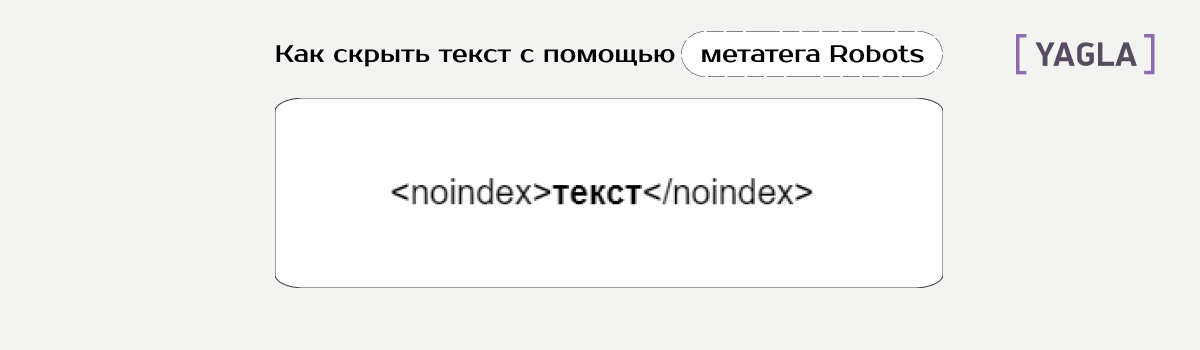
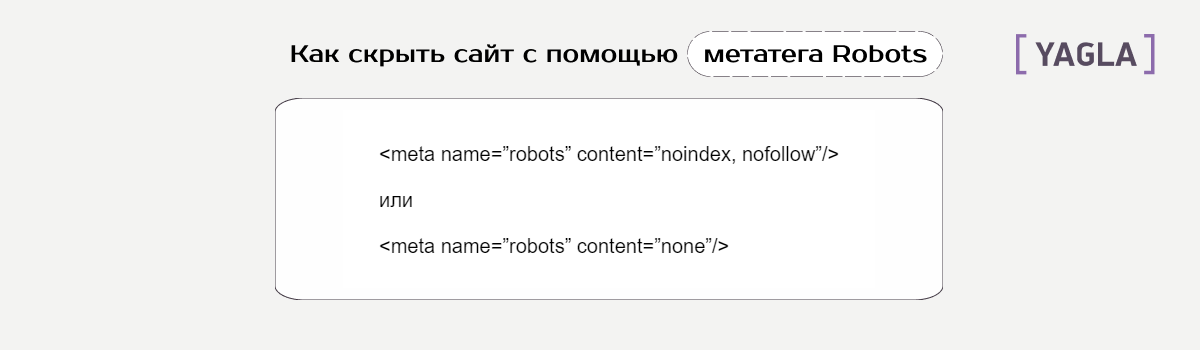
Как закрыть страницы от индексации через метатег Robots
Если программы всё-таки индексируют веб из файла Robots.txt, есть альтернативный способ — директивы noindex и nofollow в метатеге Robots. Их нужно добавить в страницы.
Способ метатега помогает скрыть:
- Конкретный кусок текста.
- Ссылку.
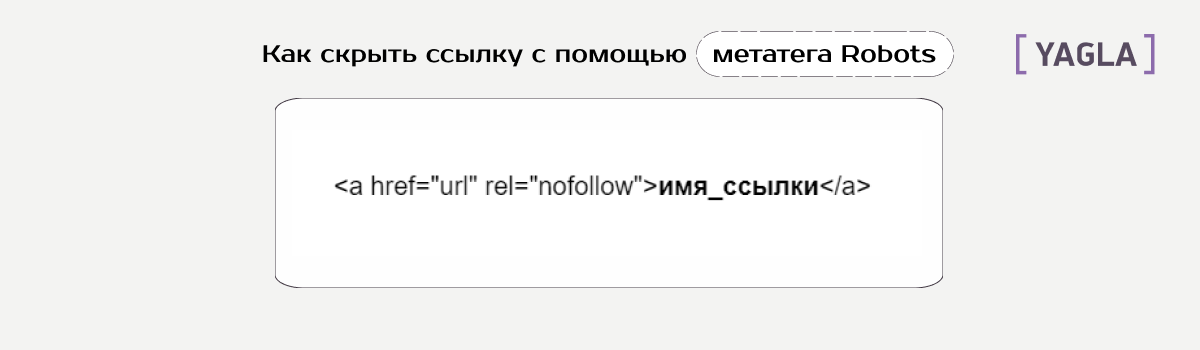
- Весь контент полностью.
Разница между первым и вторым вариантом — во втором вы запретите индексацию, но при этом также обрубите передачу статического веса страниц.
Как правило, метатег Robots — самый простой способ запретить индексацию. Он работает 100% для всех поисковых систем. Однако если проверка в Search Console и Вебмастере показывает, что запрет индексации не действует, скопируйте в файл .htaccess следующий кусок кода:
SetEnvIfNoCase User-Agent «^Googlebot» search_bot
SetEnvIfNoCase User-Agent «^Yandex» search_bot
SetEnvIfNoCase User-Agent «^Yahoo» search_bot
SetEnvIfNoCase User-Agent «^Aport» search_bot
SetEnvIfNoCase User-Agent «^BlogPulseLive» search_bot
SetEnvIfNoCase User-Agent «^msnbot» search_bot
SetEnvIfNoCase User-Agent «^Mail» search_bot
SetEnvIfNoCase User-Agent «^spider» search_bot
SetEnvIfNoCase User-Agent «^igdeSpyder» search_bot
SetEnvIfNoCase User-Agent «^Robot» search_bot
SetEnvIfNoCase User-Agent «^php» search_bot
SetEnvIfNoCase User-Agent «^Snapbot» search_bot
SetEnvIfNoCase User-Agent «^WordPress» search_bot
SetEnvIfNoCase User-Agent «^Parser» search_bot
SetEnvIfNoCase User-Agent «^bot» search_bot
Метатег Robots удаляет из индекса быстрее, чем robots.txt, так как последний способ системы используют как рекомендацию, а не жесткое правило.
Максим Ворошин, SEO-специалист MKlines
Как закрыть страницы от индексации через X-Robots-Tag
Этот способ запрещает индексацию контента определенного формата. Другое название — HTTP-заголовок на уровне сервера. Проще это реализовать через .htaccess, то есть с помощью таких строк в документе:
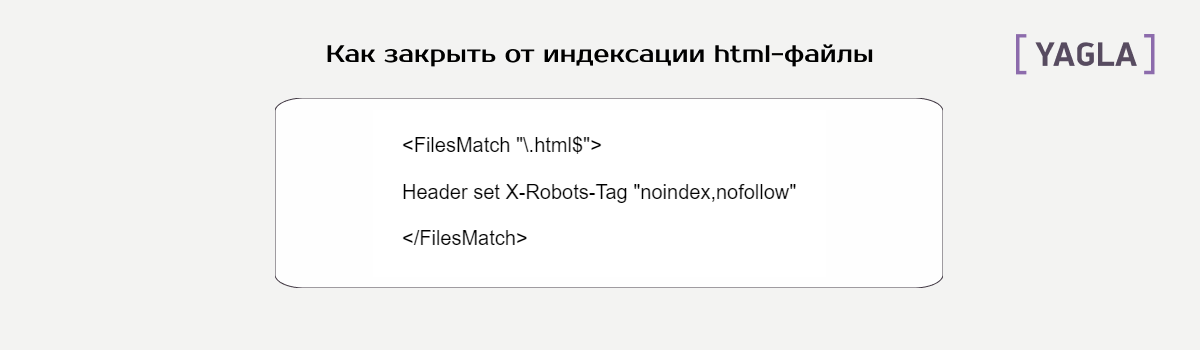
Это для html. А чтобы бот не не индексировал изображения на сайте, можно отключить форматы .png, .jpeg, .jpg, .gif:
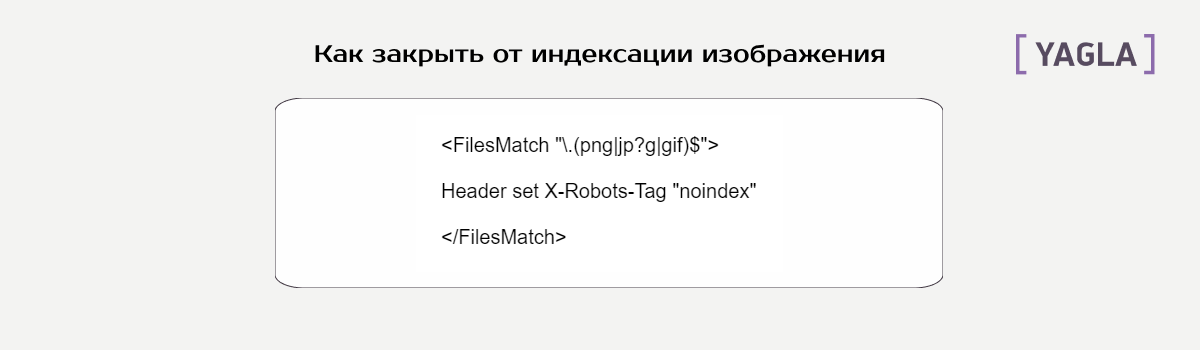
По аналогии в директиве FilesMatch можно использовать любой формат.
О методе заголовков на уровне сервера Google рассказывал еще в 2007 году. По словам эксперта Максима Ворошина, этот метод работает в 100% случаев, но используется реже остальных.
Важное преимущество — в том, что метод можно использовать как для html-страниц, так и для любого типа содержимого, например, файлов .doc и .pdf.
Как закрыть страницы пагинации от индексации
Нет единого мнения, стоит ли скрывать их от сканирования.
Аргумент «против» — актуальный для интернет-магазинов: риск, что товары не на первой странице каталога будут выпадать из индекса из-за низкой ссылочной массы.
Аргумент «за» — возможность появления дублей title на сайте.
Что касается настройки запрета для пагинации, перечисленные в статье способы не помогут. Оптимальный вариант — канонический способ rel=»canonical» с указанием главной страницы категории. В этом случае поисковики обходят ссылки на страницах пагинации, но сами страницы не появляются в индексе.
Заключение
Если показывать в поиске все подряд материалы сайта, в том числе заведомо бесполезные для посетителей, сайт может серьезно «просесть» в выдаче по позициям. В том числе есть смысл ставить запрет на индексацию для всех страниц, которые пока не готовы к потоку пользователей.
Сделать это можно тремя способами:
- Прописать в документе robots.txt
- Применить директиву noindex
- Использовать HTTP-заголовок на уровне сервера
В то же время ни один способ не дает гарантии, что закрытые страницы не попадут в базы поисковиков, поэтому стоит дополнительно проверить результат по URL-адресам в сервисах Яндекс.Вебмастер и Search Console.
Как быстро вывести лишнюю жидкость из организма?
В человеческом организме содержится примерно 60% воды, необходимой для всех биопроцессов.
Ежедневно следует употреблять как минимум 2–2,5 литра воды. Однако многие замечают, что жидкость задерживается, из-за чего увеличивается масса тела, развивается отечность. Прислушавшись к рекомендациям специалистов, как выводить лишнюю жидкость из организма, получится решить проблему самостоятельно. Избавиться от скопившейся жидкости дома не проблема, потому что существует большое количество способов, направленных на выведение воды.
Основные причины появления отеков и задержки жидкости в организме
Есть конкретные причины, провоцирующие скопление жидкости в человеческом организме:
- генетическая предрасположенность;
- отрицательно сказывается на функционировании лимфатической системы нарушение водно-солевого баланса;
- вредные привычки, потребление большого количества вредной еды и малая подвижность;
- травмы, тяжелый физический труд или занятия спортом;
- сбой в гормонах, спровоцированный болезнями органов эндокринной системы;
- скопление лимфы может наблюдаться из-за аллергии и воспалений;
- задерживается вода в тканях и межтканевых пространствах по причине чрезмерного потребления мочегонных препаратов;
- стрессовые ситуации, депрессия, тревога.
Как считают специалисты, главными причинами застоя воды являются болезни, связанные с проблемами в функционировании почечной, сердечной и сосудистой системы.
Как можно вывести лишнюю жидкость из организма – способы
Важно понимать, что задержка воды – это только следствие каких-то патологических процессов в организме. Воспользовавшись одним из эффективных способов, получится привести в норму водный баланс в тканях.
Нормализация питания
Правила питания, которые необходимо соблюдать при отеках и избытке жидкости, играют важную роль и являются обязательными в комплексном восстановлении дома. Эксперты утверждают, что качественный рацион при отклонении количества лимфы от нормальных показателей в сторону повышения, является залогом устранения излишков. Помимо этого, систематическое соблюдение базовых принципов здорового питания дает возможность снизить риск скопления воды в организме.
Первостепенно в домашних условиях следует:
- нормализовать питьевой режим;
- снизить употребление соли, так как она провоцирует отеки.
Чтобы рассчитать норму употребления воды на день, можно применить такую формулу: вес (кг) x 0,03 (если активность высокая x 0,04) = количество воды (л). Например: Масса тела 80 кг х 0,03 = 2,4 л – это нормальное количество воды на сутки.
Нужно исключить из питания любую ненатуральную пищу, в составе которой присутствуют химические элементы, наносящие вред организму. Следует убрать из рациона:
- острое;
- копчености;
- жирную и жареную еду.
Необходимо убрать из меню пищу с повышенным содержанием сахара. Пользу принесет зеленый чай и напитки на травах. Диетическое питание при застое лимфатической жидкости предусматривает полный отказ от алкоголя.
В рацион обязательно включают пищу с повышенным содержанием К, Mg. С утра правильно потреблять пищу, которая содержит преимущественно сложные углеводы.
Следует добавить в меню овощную и фруктовую продукцию, обладающую мочегонным действием. Она не только устранит скопившуюся воду, но и обогатит клетки питательными элементами. Также надо потреблять больше:
- зелени;
- злаков;
- рыбных блюд;
- кисломолочной продукции.
Главное понимать, что необходимо соблюдать время потребления еды. Ужин должен быть минимум за 3 часа до ночного отдыха.
Имеются определенные продукты, выводящие лишнюю жидкость из организма и параллельно поставляющие в клетки полезные вещества, витамины.
К более простым и эффективным можно отнести:
- лимон;
- сельдерей;
- свекла;
- кабачок;
- сок клюквы;
- петрушка;
- овес;
- помидоры;
- имбирь;
- огурец;
- арбуз;
- морковь.
В разумных количествах можно употреблять кофе и другие содержащие кофеин напитки, которые окажут влияние на выведение лишней жидкости из организма.
Разгрузочные дни
Вывести скопившуюся воду из организма получится путем кратковременного голодания. Разгрузочные дни бывают различными: базирующиеся на питье или на моно-питании. Для качественного снижения веса важно пить в разгрузочный день минимум 1 л чистой воды. Следует внимательно выбрать любой подходящий метод разгрузки, проводить его хотя бы единожды в неделю, пробуя чередовать здоровый рацион.
Разгрузка на кефире: 1,5 литра нежирного кисломолочного напитка в сутки поможет в разы уменьшить массу тела, устранить отечность, другие проявления избытка жидкости.
Разгрузочный день на тыквенном соке:
- позволит устранить накопившуюся воду в организме;
- обеспечит витаминами.
Главное – сок тыквы должен быть натуральным, лучше брать свежевыжатый продукт.
Разгрузка не должна быть частой, достаточно 1–2 дней в неделю.
Физические упражнения
Физические способы ликвидации лишней жидкости из организма активно применяются как самостоятельно, так и комплексно с прочими лечебными мероприятиями. Для приведения в норму водно-солевого баланса в организме правильно практиковать циклами любые физические упражнения:
- быстро ходить;
- бегать;
- плавать;
- ездить на велосипеде и т.п.
При активном движении мышечная ткань увеличивает скорость тока лимфатической жидкости, тем самым повышая выведение застоявшейся воды и шлаковых веществ из организма.
Устранить жидкость можно, воспользовавшись комплексом таких упражнений:
- березка;
- велосипед;
- кошка;
- подъем парашютиста.
Для достижения положительного результата от занятий физкультурой нужно постепенно наращивать продолжительность и силу нагрузок. Эти правила нельзя нарушать, так как неподготовленный к спорту организм может вместо ожидаемой пользы получить серьезный вред. Выбирая физические упражнения, следует принимать во внимание состояние здоровья, учитывать возрастной критерий и индивидуальные возможности организма.
Если нагрузки противопоказаны, для улучшения движения лимфатической жидкости и функционального состояния тела специалисты советуют применять упражнения, более простые в реализации и требующие умеренного напряжения мышц. К примеру:
- ходьба на носках;
- повороты;
- наклоны;
- поднятие ног из лежачего положения.
При исполнении упражнений необходимо глубоко дышать, не задерживать воздух. Вдыхать следует через нос. Все движения выполнять выдыхая, а вдыхать воздух, возвращаясь в исходное положение.
Расслабляющие ванны
Результативный метод вывода лишней воды – горячая ванна, облегчающая состояние и улучшающая качество жизни.
Популярна процедура с использованием соды, соединенной с морской солью. Для приготовления, необходимо набрать ванну до половины и развести в ней:
- 250 грамм соды;
- 500 грамм соли.
Температура воды должна быть в пределах +37-39 0 С. Оставаться в лечебной ванне необходимо не дольше четверти часа.
Если захочется, можно увеличить терапевтический результат данной процедуры, включив в состав средства примерно 20 капель эфирного масла:
- грейпфрутового;
- апельсинового;
- гераниевого масла.
Эфирные соединения не только нормализуют обмен веществ на клеточном уровне, но и тонизируют, омолаживают кожные покровы. А зная, какие продукты выводят лишнюю жидкость из организма, и сочетая их с другими способами, получится быстро добиться положительного эффекта, снять отеки, похудеть.
Методик разработано много, но перед тем, как воспользоваться ими, обязательно необходимо проконсультироваться со специалистом.
Другие статьи:
Дарсонвализация – физиотерапевтический эффект для волос
Среди большого разнообразия процедур, предназначенных для укрепления волос, особое место занимает дарсонвализация.
Как выбрать шампунь?
Представительницы прекрасного пола, уделяющие своей внешности особенное внимание, понимает особенности своей кожи и волос, знает, какая ей подходит косметика и какой шампунь лучше выбрать.
Как избавиться от милиумов на лице?
Поверхностное кистообразное образование на коже, состоящее из плотной сальной пробки и кератина, называется милиумом.
Как удалять страницы из индекса Google и Яндекса — восемь способов под разные ситуации без вреда для SEO

На любом сайте время от времени возникает необходимость в удалении страниц. Если просто удалить документ в админке, он останется в поисковом индексе. По крайней мере, так будет продолжаться какое-то время. Чтобы полностью убрать страницы и их содержимое из результатов поиска Google и Яндекса используют другие подходы. Способов это сделать довольно много, но ни один из них не является универсальным.
Оптимальную схему удаления всегда выбирают по ситуации. В противном случае, можно не только оставить в поиске нежелательное содержимое, но и навредить SEO-оптимизации своего сайта. Далее мы разберем восемь самых рабочих способов удаления URL-адресов. Расскажем, в каких случаях уместно применять каждый из методов и как избежать распространенных ошибок, негативно влияющих на SEO.
Как проверить присутствие страницы в индексе
Прежде чем приступать к удалению страниц, логично убедиться, действительно ли они присутствуют в индексе. Во-первых, это нужно, поскольку и Google, и Яндекс могут игнорировать некоторые страницы (обычно с малозначительным содержимым); во-вторых, если мы говорим, например, о 404-х страницах, со временем они сами вылетают из индекса.
Обычно индексирование страниц проверяют через запрос с поисковым оператором site:
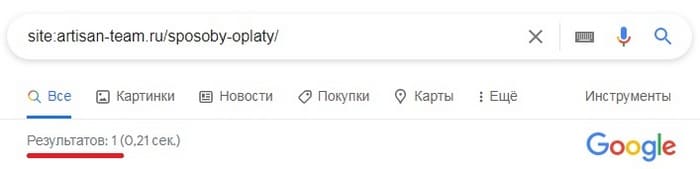
Если поисковик находит URL-адрес через оператор site:, вероятнее всего, документ проиндексирован (но бывают и исключения)
Этот способ, действительно, самый удобный. Он незаменим, например, для быстрого анализа конкурентов, когда нужно на глаз оценить масштаб их сайтов. Но для точеной проверки URL он не подходит, т. к. может в некоторых случаях предоставлять некорректные данные. Например, в результатах поиска может быть показан не запрашиваемый документ, а страница с редиректом, которой формально не существует.
Чтобы точно понять, есть URL в индексе или нет, лучше использовать консоли вебмастера Google и Яндекса.
В Google Search Console вся актуальная информация, касающаяся индексирования страниц, доступна на вкладке Индекс → Покрытие:
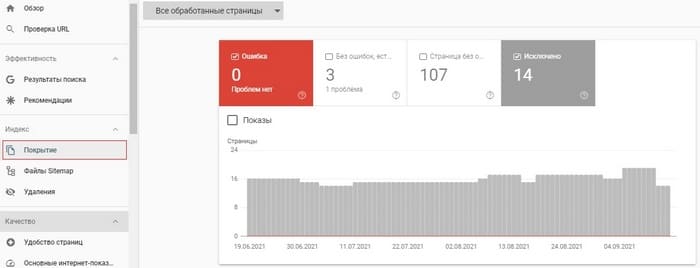
Чтобы проверить страницу еще быстрее, просто вставьте нужный URL-адрес в строку поиска вверху консоли.

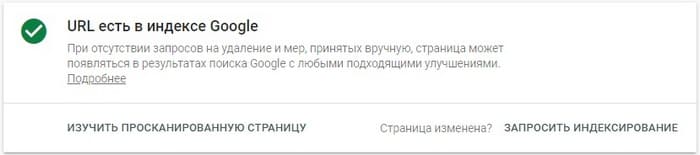
Если страница в индексе, будет доступно соответствующее уведомление:
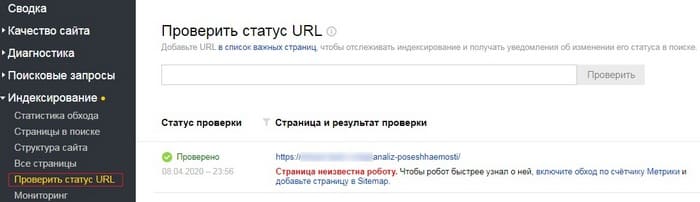
В Яндекс.Вебмастере (Индексирование → Проверить статус URL) для проверки индексирования также предусмотрен отдельный инструмент.
Способ 1. Удаление страницы
Вам ничто не мешает поступить самым очевидным способом – и просто удалить страницу вместе со всем ее содержимым в админке сайта. Это весьма топорный метод, но и его можно использовать, если быть в курсе некоторых нюансов.
После удаления документа этим способом необходимо проверить коды ответа сервера, и убедиться, что они отдают статус HTTP 404 (не найдено) или 410 (удалено). Хоть фактически страница и удалена, тем не менее она остается в индексе и продолжает ранжироваться, до момента пока поисковые роботы не совершат переобход сайта. В отдельных случаях это может занять довольно много времени. В дополнение к этому, даже несмотря на фактическое отсутствие документа, содержимое удаленной страницы будет оставаться доступным в кэше для всех желающих.

Также при удалении и деиндексировании страниц могут возникнуть проблемы с файлами, формат которых отличен от HTML, например, документами PDF, DOC, XLS и др. – их нужно удалять с сервера полностью.
Как мы видим, у этого способа есть немало нюансов, поэтому во многих случаях он не подходит. Его не нужно использовать в следующих ситуациях:
Когда необходимо удалить страницы в срочном порядке . Например, если это документы, сгенерированные вредоносным скриптом после взлома сайта. Ждать запрошенной переиндексации в этом случае – плохой вариант.
Когда на страницу стоят сильные обратные ссылки . Удаление документа в этом случае приведет к «сгоранию» сигналов, усиливающих SEO вашего сайта.
Когда нужно оставить страницу доступной для пользователей . Например, это может быть актуальным, если вы не хотите, чтобы в индексе ранжировались технические страницы с неуникальным контентом (пользовательское соглашение, политика конфиденциальности и пр.).
В этих и ряде других случаев используют менее топорные способы скрытия страниц из поиска.
Способ 2. Использование инструментов для удаления URL
В Google есть отдельный инструмент для быстрой деактивации нежелательных URL. Но его название может вводить в заблуждение, поскольку он удаляет страницы из поиска не навсегда, а только на время . Это удобно, когда нужно действовать незамедлительно, например, после взлома сайта, но в дальнейшем нужно не забыть применить другой метод постоянного удаления.
Эффект от блокировки длится порядка шести месяцев. Все это время Google видит и обрабатывает отклоненные страницы, но не отображает их в выдаче. На обработку самого запроса на скрытие может уйти до суток, хотя на практике это происходит значительно быстрее. В отдельных случаях система может не выполнить запрос на удаление URL, поэтому после подачи заявки нужно отслеживать ее статус, и если она будет отклонена, вам сообщат по какой именно причине. Вместе с самой страницей также на время можно убрать из выдачи ее кэшированную версию.
Таким образом, инструмент для деактивации URL в Google целесообразно использовать только при форс-мажорах, когда нужно экстренно удалить документ:
- при взломах;
- утечке данных;
- сбоях в работе CMS с последующим генерированием «мусорных» страниц и т. д.
Для удаленных URL-адресов, с кодом статуса 404, 502 или 503, запрос на блокировку не работает.
Инструмент для удаления в выдаче Яндекса
Запросить ускоренное удаление URL из выдачи Яндекса можно через соответствующий инструмент в Вебмастере. Но здесь есть важный нюанс: этот способ подходит только для деиндексирования документов, которые уже удалены либо закрыты для сканирования поисковыми роботами (через тег noindex или блокировку в robots.txt).
Способ 3. Добавление метатега robots с директивой noindex
С помощью метатега robots в HTML-коде страницы вы можете указывать поисковым работам правила обработки для конкретных URL-адресов. Чтобы запретить к индексированию нужную страницу и исключить ее из результатов поиска, к метатегу robots добавляют параметр noindex. Саму запись размещают в элементе head и выглядит она так:
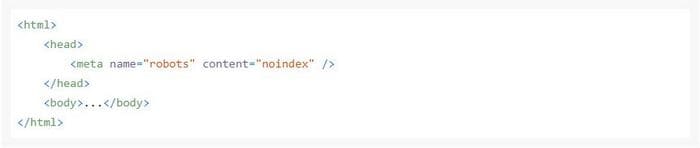
Запрещающую директиву noindex в метатеге robots (не путать с robots.txt) можно использовать в поиске Google, Яндекс и Bing.
Для каких случаев такой способ НЕ подходит:
- для закрытия страниц, имеющих качественные обратные ссылки (noindex заблокирует передачу ссылочных сигналов);
- для URL-адресов, которые нужно скрыть от части пользователей.
- для закрытия от индексирования дополнительных типов файлов, например, PDF, XLS и т. д.
Чтобы поисковые краулеры увидели и распознали метатеги с нужными директивами, страницы должны быть доступны для сканирования. Поэтому важно удостовериться, что они не закрыты от обхода в robots.txt.
Способ 4. Noindex в ответе заголовка X-Robots-Tag
Запрет на индексирование определенных URL также можно сделать через настройку HTTP-заголовка X-Robots-Tag на сервере. В этом случае используют уже упомянутую директиву noindex. HTTP-ответ, где заголовок запрещает индексирование документа, выглядит так:

Запрет через X-Robots-Tag принято считать более надежным способом деиндексирования, чем использование noindex в метатеге robots, поскольку вероятность, что поисковые краулеры проигнорируют директиву HTTP-заголовка значительно ниже. Также этот способ незаменим, когда URL-адрес, который нужно удалить из индекса, это не веб-страница, а, например, PDF-файл.
Тем не менее этот вариант не подходит, если нужно закрыть страницу, которая имеет хорошие обратные ссылки. Также данный способ неуместен, когда нужно деиндексировать страницу максимально оперативно.
Способ 5. Ограничение доступа к странице
Страницы с ограниченным доступом, например, защищенные паролем, по умолчанию закрыты для обхода поисковыми роботами и, соответственно, содержимое таких документов не попадает в индекс. Это довольно специфический способ управления индексированием, и актуален он лишь в тех случаях, когда нужно предоставить доступ к страницам только небольшому кругу пользователей. С технической точки зрения для ограничения доступа можно использовать одно из следующих решений:
- систему учетных записей;
- HTTP-аутентификацию;
- доступ по подтвержденным IP-адресам.
В этих случаях поисковые роботы не смогут проиндексировать содержимое страниц, а сам контент не будет доступен сторонним пользователям. Это актуально при создании внутренних сетей, публикации платного или другого непубличного контента. Также доступ к страницам лучше ограничивать на этапах разработки или тестирования сайта, чтобы исключить индексирование технического «мусора». Если непубличный контент уже попал в индекс и его нужно срочно скрыть из кэша, используют метод №2.
Способ 6, 7 и 8. Деиндексирование с перераспределением ссылочного веса
Описанные выше способы касались удаления из индекса URL, по большей части не представляющих ценности для сайта. Теперь поговорим о ситуациях, когда нужно деиндексировать документы, которые полезны для продвижения и передают ценные SEO-сигналы. Обычно здесь имеют ввиду страницы с качественными обратными ссылками, которые по каким-то причинам нужно скрыть из индекса.
Деиндексирование URL с сохранением их ссылочного веса проводят одним из трех методов.
6. Создание 301-редиректа
Редирект – это техническая настройка, которая автоматически перенаправляет с одного URL-адреса на другой. Их бывает несколько видов, но нас интересует главным образом редирект с кодом 301. Он не просто автоматически перенаправляет пользователей с неактуальной страницы (А) на нужную версию (В), но и указывает поисковым роботам, что весь ссылочный вес документа А нужно перераспределить на документ В, а саму исходную страницу удалить из индекса.
Важно понимать, что такие перенаправления работают только между тематически релевантными URL. Если вы решите сделать 301-редирект со страницы А, которая по содержанию не соотносится со страницей В, поисковикам сильно не понравятся такие манипуляции. Они не только блокируют перераспределение ссылочного веса, но и могут начать учитывать редирект как ложную ошибку (soft 404). Таким образом нужная версия страницы будет недоступной для пользователей.
Больше о принципах работы 301-редиректа и тонкостях его настройки – читайте в отдельной статье.
7. Атрибут rel=”canonical”
Добавление канонического тега rel=”canonical” – классическое решение проблемы дублей и один из способов управления индексированием. Если разные страницы на сайте имеют очень похожее содержимое или полностью повторяются – это серьезный недочет оптимизации. Поисковики умеют объединять такие дубли в группы. Из этого набора они выбирают самую информативную и релевантную страницу (ее называют канонической ), а остальное удаляют из индекса. Но полагаться на работу алгоритмов не стоит, и лучше указать каноническую страницу самому – при помощи тега rel=”canonical”.
Технически в такой каноникализации нет ничего сложного: на всех второстепенных страницах нужно добавить фрагмент кода, который будет сообщать поисковикам, что это дубль, и указывать на основную (каноническую) страницу.
Например, у нас есть основная страница ( www.example.com/blog ) и ее дубль ( www.example.com/blog_2 ). Чтобы подсказать поисковикам, какой документ главный, в HTML-код страницы /blog_2 нужно добавить такой фрагмент:

Атрибут rel=”canonical” поддерживается всеми поисковыми системами. При этом его нужно использовать, только когда страницы действительно дублируются или очень похожи по содержанию. Если поисковик посчитает, что это не так, атрибут rel=”canonical” будет проигнорирован, поскольку это рекомендация, а не обязательная директива. Также каноникалы имеют свойство слетать, поэтому их нужно время от времени проверять, особенно если на сайте проводили технические работы или вносили другие серьезные изменения.
Canonical не используют в связке с noindex (способ 3 и 4). Это конфликтующие сигналы для поисковиков, поскольку атрибут rel=”canonical” дает указание, что нужно проиндексировать другую страницу, а noindex рекомендует убрать документ из индекса. При использовании сразу двух атрибутов поисковые системы, вероятнее всего, учтут canonical, а noindex просто проигнорируют. Но возможен и обратный сценарий – тогда страницы не смогут передавать ссылочные сигналы, а это уже серьезный недочет внутренней оптимизации (по крайней мере, если таких страниц много).
8. Настройка обработки параметров URL
Параметры — это часть URL, которая присоединяется обычно после знака ? в конце адреса. Необходимость в них чаще всего возникает, когда нужно отфильтровать страницу по каким-то характеристикам.
Например, у нас есть карточка женского платья со стандартным URL:

Если мы выберем другой цвет товара, исходная страница поменяет URL на такой:

А если мы найдем это же платье через фильтр магазина, URL карточки уже будет выглядеть так.

Во всех трех случаях мы имеем дело с одной и той же страницей, но разными URL. Чтобы помочь поисковикам корректно сканировать такие дубли, нужно задать настройки обработки параметров. В Google это делают с помощью инструмента «Параметры URL». Подробнее о принципах его использования – в официальной справке. Сам способ применяют исключительно для страниц с параметрами. Во всех остальных случаях применяют атрибут rel=”canonical” или другой из описанных выше методов каноникализации.
В Яндексе, насколько мы в курсе, подобного инструмента не предусмотрено. Чтобы исключить сканирование одинаковых страниц с параметрами, здесь используют другие схемы:
- отклонение в robots.txt через директиву clean-param;
- использование noindex/nofollow;
- каноникализацию через rel=”canonical”.
Как удалить картинки из поискового индекса
Когда нужно оперативно убрать изображение из поиска – удаляют всю страницу, используя способ №1. Это самая быстрая схема, которая к тому же позволяет сразу вычистить фото из кэша. Но инструмент удаления URL работает только под Google, поэтому картинки будут оставаться доступными в Яндексе. К тому же, если нужно убрать изображение из поиска, далеко не всегда целесообразно удалять всю страницу.
Более универсальный, хоть и не такой быстрый, способ скрыть картинки от Google и Яндекса – ограничить их сканирование в файле robots.txt, используя директиву Disallow (она запрещает индексирование разделов сайта, отдельных страниц или конкретного файла). При этом сами изображения будут оставаться на сайте. Это оптимальный вариант для тех, кто использует на своих страницах заимствованные фото и не хочет лишний раз засвечивать их в поиске.

изображение, расположенное по указанному адресу, будет закрыто от индексирования в Google
Этот способ более гибкий благодаря поддержке подстановочных знаков. В robots.txt можно запретить сканирование картинок определенного формата, например, только GIF-файлов:

Также здесь можно дать указание, отображать картинки в основном поиске, но блокировать их на вкладке с изображениями. Это позволит странице, например, отображаться в колдунщике с подтянутым фото на вкладке «Все результаты».
Директива Disallow поддерживается Google и Яндексом, но при необходимости можно заблокировать ранжирование изображений только в одной из поисковых систем. В то же время этот способ не такой быстрый, и чтобы фото пропали из результатов выдачи, придется дождаться переиндексирования.