Как в ворде стрелочку поставить над буквой (вектор) ?

Обводишь буквы например — pb. В меню тыкаешь > Вставка > Формула > Диакритические знаки. Открывается окошко и там находишь знак вектора. В итоге получится pb со стрелочкой сверху.

Похожие вопросы
По умолчанию в Word-е нет проверки русской орфографии.
Установи Microsoft Proofing Tools. Если надо, пиши лично, как-нить скину.
Набираешь нужный текст, потом выделяешь его, потом твои действия: ФОРМАТ —> ШРИФТ, там в подразделе «Видоизменение» ставишь галку рядом с «контур» 😉
Надеюсь понятно и по теме =)
не ставяТся (что делаюТ)
Мешает драйвер интеловской видеокарты. Убирайте из процессов hkcmd.exe — всё заработает. И вообще, как это вы не следите, что за процессы загружаются при старте? Или ваш администратор не выполняет свои обязанности, опять же..
для исправления ошибок в Ворде не обязателен Proofing Tools. надо просто настройки поставить в Ворде.
1. окрываем Ворд
2. tools
3. options
4. там одна из закладок есть — Spelling & Grammar
5. ставим галочки если нужна коррекция при написании, и т.д.
Как поставить знак вектора в Microsoft Word ??
Как поставить стрелку над буквой (обозначение вектора) в MS Word?
Это вообще можно сделать в ворде?
Лучший ответ
Это сделать можно, открываеш редактор формул: вставка=>объект=>Microsoft Equationm, а там уже ищеш как тебе надо со стрелочкой без стрелочки в какую сторону и выбираеш вот и все.
Остальные ответы
Зайди в редактор формул — это такой значок в виде корня (мат) на панели инструментов 😎
Вставка — символ там можно выбрать все что нужно !
ну как это сделать символьно не помню, а вот могу подсказать, может нарисуешь?
Советую поковыряться с Microsoft Equation. В нем можно набирать довольно сложные формулы, если потратить некоторое время на его изучение. Он понравится тем, кто любит мышкой возить по экрану. А другим советую изучить издательскую систему TeX (очень мощная вещь: ) )
Похожие вопросы
Вставить в ворд векторную картинку
Доброго всем дня!
Нужно вставить в ворд векторную картинку, но так, чтобы в ворде можно было спокойно и без лишних программ редактировать отдельные векторные элементы.
Конкретно, просят вставить в ворд карту Украины, но так, чтобы можно было перекрашивать области.
Прислали пару образцов — там рисунок выполнен как автофигура — т.е. тот же вектор, как и в иллюстраторе, с возможностью двигать узловые точки и все подобное.
Можно вставить карту из Корела, но тогда и редактировать можно только в кореле.
Какие есть варианты?
попробовал через экспорт в emf и wmf — без толку. eps тоже как то странно вставляется и редактируется кусками.
гугл, также, скуп на подобную информацию.
Векторное представление слов
Векторное представление слов (англ. word embedding) — общее название для различных подходов к моделированию языка и обучению представлений в обработке естественного языка, направленных на сопоставление словам из некоторого словаря векторов небольшой размерности.
One-hot encoding

Рисунок 1. Пример one-hot encoding для словаря из 9 слов. Источник
Пусть число различных слов равно [math]K[/math] . Сопоставим слову с номером [math]i[/math] вектор длины [math]K[/math] , в котором [math]i[/math] -тая координата равна единице, а все остальные — нулям (рис. 1). Недостатком one-hot encoding является то, что по векторным представлениям нельзя судить о схожести смысла слов. Также вектора имеют очень большой размер, из-за чего их неэффективно хранить в памяти.
word2vec
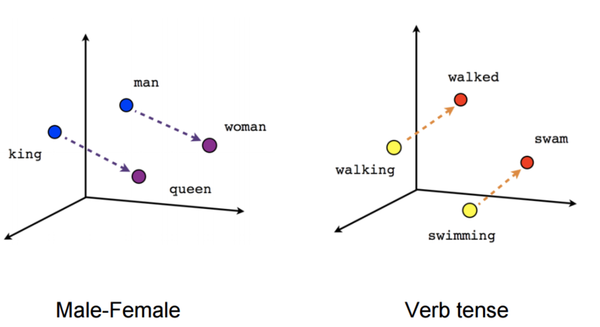
Рисунок 2. Полученные векторы-слова отражают различные грамматические и семантические концепции.
[math]W_ + (W_ — W_) = W_[/math]
[math]W_ — W_ = W_ — W_[/math]
word2vec — способ построения сжатого пространства векторов слов, использующий нейронные сети. Принимает на вход большой текстовый корпус и сопоставляет каждому слову вектор. Сначала он создает словарь, а затем вычисляет векторное представление слов. Векторное представление основывается на контекстной близости: слова, встречающиеся в тексте рядом с одинаковыми словами (а следовательно, имеющие схожий смысл) (рис. 2), в векторном представлении имеют высокое косинусное сходство (англ. cosine similarity):
В word2vec существуют две основных модели обучения: Skip-gram (рис. 3) и CBOW (англ. Continuous Bag of Words) (рис. 4). В модели Skip-gram по слову предсказываются слова из его контекста, а в модели CBOW по контексту подбирается наиболее вероятное слово. На выходном слое используется функция [math]softmax[/math] или его вариация, чтобы получить на выходе распределение вероятности каждого слова. В обеих моделях входные и выходные слова подаются в one-hot encoding, благодаря чему при умножении на матрицу [math]W[/math] , соединяющую входной и скрытый слои, происходит выбор одной строки [math]W[/math] . Размерность [math]N[/math] является гиперпараметром алгоритма, а обученная матрица [math]W[/math] — выходом, так как ее строки содержат векторные представления слов.
Для ускорения обучения моделей Skip-gram и CBOW используются модификации [math]softmax[/math] , такие как иерархический [math]softmax[/math] и negative sampling, позволяющие вычислять распределение вероятностей быстрее, чем за линейное время от размера словаря.


fastText
Недостатком word2vec является то, что с его помощью не могут быть представлены слова, не встречающиеся в обучающей выборке. fastText решает эту проблему с помощью [math]N[/math] -грамм символов. Например, [math]3[/math] -граммами для слова яблоко являются ябл, бло, лок, око. Модель fastText строит векторные представления [math]N[/math] -грамм, а векторным представлением слова является сумма векторных представлений всех его [math]N[/math] -грамм. Части слов с большой вероятностью встречаются и в других словах, что позволяет выдавать векторные представления и для редких слов.
Примеры кода с использованием библиотеки Gensim
Загрузка предобученной модели русского корпуса
import gensim import gensim.downloader as download_api russian_model = download_api.load('word2vec-ruscorpora-300')
# Выведем первые 10 слов корпуса.
# В модели "word2vec-ruscorpora-300" после слова указывается часть речи: NOUN (существительное), ADJ (прилагательное) и так далее.
# Но существуют также предоубученные модели без разделения слов по частям речи, смотри репозиторий list(russian_model.vocab.keys())[:10] # ['весь_DET', 'человек_NOUN', 'мочь_VERB', 'год_NOUN', 'сказать_VERB', 'время_NOUN', 'говорить_VERB', 'становиться_VERB', 'знать_VERB', 'самый_DET']
# Поиск наиболее близких по смыслу слов. russian_model.most_similar('кошка_NOUN') # [('кот_NOUN', 0.7570087909698486), ('котенок_NOUN', 0.7261239290237427), ('собака_NOUN', 0.6963180303573608), # ('мяукать_VERB', 0.6411399841308594), ('крыса_NOUN', 0.6355636119842529), ('собачка_NOUN', 0.6092042922973633), # ('щенок_NOUN', 0.6028496026992798), ('мышь_NOUN', 0.5975362062454224), ('пес_NOUN', 0.5956044793128967), # ('кошечка_NOUN', 0.5920293927192688)]
# Вычисление сходства слов russian_model.similarity('мужчина_NOUN', 'женщина_NOUN') # 0.85228276
# Поиск лишнего слова russian_model.doesnt_match('завтрак_NOUN хлопья_NOUN обед_NOUN ужин_NOUN'.split()) # хлопья_NOUN
# Аналогия: Женщина + (Король - Мужчина) = Королева russian_model.most_similar(positive=['король_NOUN','женщина_NOUN'], negative=['мужчина_NOUN'], topn=1) # [('королева_NOUN', 0.7313904762268066)]
# Аналогия: Франция = Париж + (Германия - Берлин) russian_model.most_similar(positive=['париж_NOUN','германия_NOUN'], negative=['берлин_NOUN'], topn=1) # [('франция_NOUN', 0.8673800230026245)]
Обучение модели word2vec и fastText на текстовом корпусе
from gensim.models.word2vec import Word2Vec from gensim.models.fasttext import FastText import gensim.downloader as download_api
# Скачаем небольшой текстовый корпус (32 Мб) и откроем его как итерируемый набор предложений: iterable(list(string)) # В этом текстовом корпусе часть речи для слов не указывается corpus = download_api.load('text8')
# Обучим модели word2vec и fastText word2vec_model = Word2Vec(corpus, size=100, workers=4) fastText_model = FastText(corpus, size=100, workers=4)
word2vec_model.most_similar('car')[:3] # [('driver', 0.8033335208892822), ('motorcycle', 0.7368553876876831), ('cars', 0.7001584768295288)]
fastText_model.most_similar('car')[:3] # [('lcar', 0.8733218908309937), ('boxcar', 0.8559106588363647), ('ccar', 0.8268736004829407)]
ELMO

ELMO — это многослойная двунаправленная рекуррентная нейронная сеть c LSTM (рис. 5). При использовании word2vec или fastText не учитывается семантическая неоднозначность слов. Так, word2vec назначает слову один вектор независимо от контекста. ELMO решает эту проблему. В основе стоит идея использовать скрытые состояния языковой модели многослойной LSTM.
Было замечено, что нижние слои сети отвечают за синтаксис и грамматику, а верхние — за смысл слов. Пусть даны токены [math]t_, . t_[/math] , на которые поделено предложение. Будем считать логарифм правдоподобия метки слова в обоих направлениях, учитывая контекст слева и контекст справа, то есть на основании данных от начала строки до текущего символа и данных от текущего символа и до конца строки. Таким образом, модель предсказывает вероятность следующего токена с учетом истории.
Пусть есть [math]L[/math] слоев сети. Входные и выходные данные будем представлять в виде векторов, кодируя слова. Тогда каждый результирующий вектор будем считать на основании множества:
[math]\left \< ^>, \overrightarrow^>, \overleftarrow^> | j = 1, . L \right \> = \left \< h_^ | j = 1, . L \right \>[/math] .
Здесь [math]x_^[/math] — входящий токен, а [math]\overrightarrow^>[/math] и [math]\overleftarrow^>[/math] — скрытые слои в одном и в другом направлении.
Тогда результат работы ELMO будет представлять из себя выражение: [math]ELMO_^ = \gamma^\sum_^ s_^h_^[/math] .
Обучаемый общий масштабирующий коэффициент [math]\gamma^[/math] регулирует то, как могут отличаться друг от друга по норме векторные представления слов.
Коэффициенты [math]s_^[/math] — это обучаемые параметры, нормализованные функцией [math]Softmax[/math] .
Модель применяют дообучая ее: изначально берут предобученную ELMO, а затем корректируют [math]\gamma[/math] и [math]s_[/math] под конкретную задачу. Тогда вектор, который подается в используемую модель для обучения, будет представлять собой взвешенную сумму значений этого векторах на всех скрытых слоях ELMO.
На данный момент предобученную модель ELMO можно загрузить и использовать в языке программирования Python.
BERT
Основная статья: BERT (языковая модель)

BERT — это многослойный двунаправленный кодировщик Transformer. В данной архитектуре (рис. 6) используется двунаправленное самовнимание (англ. self-attention). Модель используется в совокупности с некоторым классификатором, на вход которого подается результат работы BERT — векторное представление входных данных. В основе обучения модели лежат две идеи.
Первая заключается в том, чтобы заменить [math]15\%[/math] слов масками и обучить сеть предсказывать эти слова.
Второй трюк состоит в том, чтобы дополнительно научить BERT определять, может ли одно предложение идти после другого.
Точно так же, как и в обычном трансформере, BERT принимает на вход последовательность слов, которая затем продвигается вверх по стеку энкодеров. Каждый слой энкодера применяет самовнимание и передает результаты в сеть прямого распространения, после чего направляет его следующему энкодеру.
Для каждой позиции на выход подается вектор размерностью [math]hiddenSize[/math] ( [math]768[/math] в базовой модели). Этот вектор может быть использован как входной вектор для классификатора.
Bert поддерживается в качестве модели в языке Python, которую можно загрузить.
См. также
Источники информации
- Word embedding — статья о векторных представлениях в английской Википедии
- (YouTube) Обработка естественного языка — лекция на русском Даниила Полыковского в курсе Техносферы
- (YouTube) Word Vector Representations: word2vec — лекция на английском в Стэнфордском Университете
- word2vec article — оригинальная статья по word2vec от Томаса Миколова
- word2vec code — исходный код word2vec на Google Code
- Gensim tutorial on word2vec — небольшое руководство по работе с word2vec в библиотеке Gensim
- Gensim documentation on fastText — документация по fastText в библиотеке Gensim
- Gensim Datasets — репозиторий предобученных моделей для библиотеки Gensim
- fastText — NLP библиотека от Facebook
- fastText article — оригинальная статья по fastText от Piotr Bojanowski
- RusVectōrēs — онлайн сервис для работы с семантическими отношениями русского языка
- Cornell univerity arxiv — оригинальная статья про Bert
- Cornell univerity arxiv — оригинальная статья с описанием ELMO
- Машинное обучение
- Обработка естественного языка