Распознавание текста с помощью pytesseract

Не так давно я озадачился вопросом распознавания печатного текста в своём приложении. Мне стало интересно, какие на данный момент существуют OCR-библиотеки и насколько они удобны в использовании. А главное — будет ли приемлемый результат распознавания текста и можно ли такой текст потом озвучить? Озвучка текста это тема для отдельной статьи, а сегодня мы напишем приложение на Python, которое сможет распознавать тексты на русском языке благодаря OCR-библиотеке Tesseract.
Если вы столкнулись с задачей распознавания текста, то в первую очередь необходимо обратить внимание на так называемые OCR-библиотеки. Вообще OCR (Optical Character Recognition) — это оптическое распознавание текста, то есть механический или электронный перевод изображений с текстом в текстовые данные. То есть формально, когда вы перепечатываете какой-либо текст, то реализуете один из механизмов OCR 🙂
Нас конечно же интересует чтобы программа сама смогла прочитать текст с картинки и предоставить текстовые данные в строковой переменной. Для этого существуют различные готовые библиотеки и одна из них — Tesseract. Сама библиотека Tesseract не имеет ничего общего с Python, по сути она содержит OCR-движок и программу командной строки. Поэтому для разработки на Pyhton нам потребуется специальный модуль pytesseract.
Подготовка
Перед тем как я начну использовать pytesseract, необходимо провести подготовительную работу. Так как у меня на компьютере Linux, мне нужно загрузить ряд пакетов чтобы начать разработку распознавалки текста. Для этого в командной строке необходимо выполнить:
$ sudo apt update $ sudo apt install tesseract-ocr $ sudo apt install libtesseract-devЭтого достаточно чтобы распознать текст на английском языке, но моя цель — распознавание текстов на русском языке, поэтому потребуется поставить ещё один пакет:
$ sudo apt install tesseract-ocr-rusУ библиотеки Tesseract много языковых пакетов, поэтому если вам требуется возможность распознавать какой-либо другой язык, то выполняете комманду:
$ sudo apt install tesseract-ocr-[lang]А можно просто выполнить команду:
$ sudo apt install tesseract-ocr-allи у вас будет поддержка всех языков, которые умеет распознавать Tesseract.
Я правда не разбирался как всё тоже самое провернуть в Windows, но если вам это интересно, напишите пожалуйста к статье комментарий или мне в личные сообщения — я дополню статью. А пока продолжаем работу в Linux 🙂
Создание проекта
Теперь нужно создать новый проект в IDE и настроить виртуальное окружение. Для распознавания текста необходимо поставить библиотеку pytesseract, как я уже писал выше, а так же потребуется pillow для загрузки изображений. Поэтому выполняем следующие команды:
pip3 install pytesseract pip3 install pillowТеперь у нас есть всё необходимое чтобы приступить к разработке приложения, которое будет распознавать текст.
Разработка
Само приложение будет максимально простым, ведь вся работа ложится на установленные библиотеки. Мне остаётся только написать несколько строчек чтобы всё заработало:
import pytesseract from PIL import Image # Загрузка изображения с текстом image = Image.open("test.jpg") # Распознавание текста string = pytesseract.image_to_string(image, lang='rus') # Вывод распознанного текста в консоль print(string) Вот и весь код! Единственный важный момент — нужно явно указывать язык при вызове метода image_to_string, так как библиотека не умеет самостоятельно определять язык, на котором написан текст.
Теперь попробуем распознать вот такую сложную по своей структуре страницу:

Запускаем программу и получаем следующий результат:
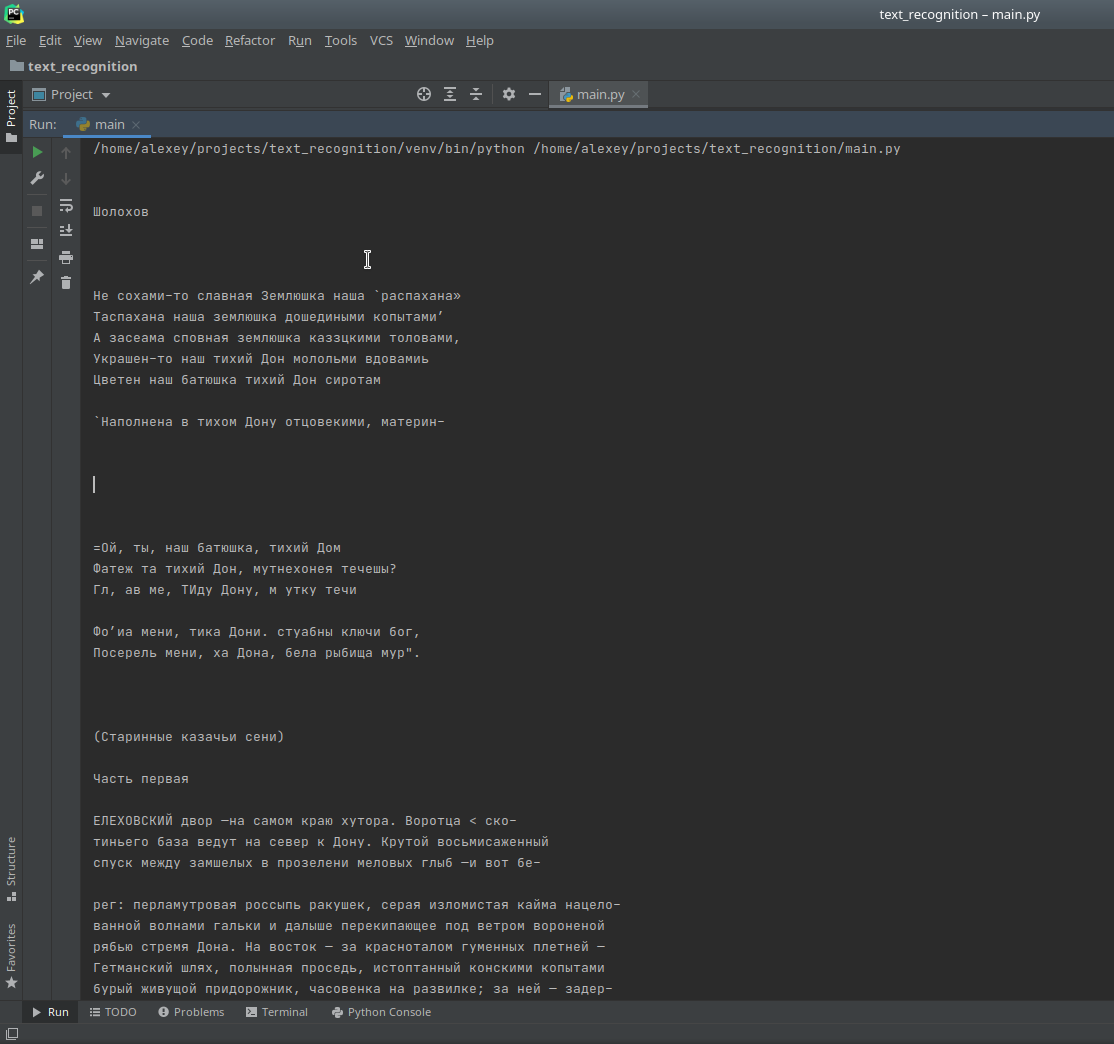
Не идеально конечно, но с учётом того что структура страницы сложная, качество изображения плохое и часть букв смазаны, то результат вполне себе хороший! Тут стоит вспомнить что даже старый добрый FineReader так же допускает ошибки при распознавании текста.
Современным разработчикам очень повезло — уже существуют множество готовых библиотек с очень серьёзными возможностями. Ещё лет 15-20 назад для решения подобной задачи пришлось бы потратить гораздо больше времени и скорее всего пришлось бы писать свой OCR-движок. Теперь достаточно написать несколько строчек кода чтобы получить на выходе достойный результат!
Не мойму как установить pytesseract
Установил Tesseract OCR по этому гайду https://www.youtube.com/watch?v=Rb93uLXiTwA&ab_channel=AllroundZone и на ввод в консоль tesseract он отзывается.
Установил opencv-python c помощью pip install opencv-python
Установил pytesseract pip install pytesseract
from cv2 import cv2 import pytesseract img=cv2.imread("test.png") im=cv2.resize(img,None,fx=9,fy=9) like=pytesseract.image_to_string(img,config='outputbase digits') print(like) Выводит такое Traceback (most recent call last): File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\site-packages\pytesseract\pytesseract.py", line 255, in run_tesseract proc = subprocess.Popen(cmd_args, **subprocess_args()) File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\subprocess.py", line 947, in __init__ self._execute_child(args, executable, preexec_fn, close_fds, File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\subprocess.py", line 1416, in _execute_child hp, ht, pid, tid = _winapi.CreateProcess(executable, args, FileNotFoundError: [WinError 2] Не удается найти указанный файл During handling of the above exception, another exception occurred: Traceback (most recent call last): File "e:\py projects\content\img_to_str.py", line 10, in like=pytesseract.image_to_string(img,config='outputbase digits') File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\site-packages\pytesseract\pytesseract.py", line 409, in image_to_string return < File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\site-packages\pytesseract\pytesseract.py", line 412, in Output.STRING: lambda: run_and_get_output(*args), File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\site-packages\pytesseract\pytesseract.py", line 287, in run_and_get_output run_tesseract(**kwargs) File "C:\Users\dkati\AppData\Local\Programs\Python\Python39\lib\site-packages\pytesseract\pytesseract.py", line 259, in run_tesseract raise TesseractNotFoundError() pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
Распознаем текст на изображении с Python Tesseract

Из этого руководства вы узнаете как распознать текст на изображении с помощью трех строк Python кода.
Шаг 1. Установим оболочку для Tesseract-OCR Engine
pip install pytesseractШаг 2. Загрузим и установить Tesseract на Windows по следующей ссылке: https://digi.bib.uni-mannheim.de/tesseract/

Поставим галочку для загрузки дополнительного языка, в нашем случае "Russian".
Шаг 3. Запустим код, и посмотрим результат. Для примера попробуем распознать текст с картинки ниже.

import pytesseract config = r'--tessdata-dir "C:\Program Files\Tesseract-OCR\tessdata" -l rus --oem 1 --psm 3' result = pytesseract.image_to_string('1.jpg', config=config) print(result)Таким образом реализация намеченных плановых заданий позволяет оценить значение новых предложений.Следующее изображение

ДЕРЖИСЬ ПОДАЛЬШЕ ОТ СЕРВЕРНОЙОткуда устанавливать Tesseract OCR для Python?
Посмотрел много гайдов по установке Tesseract OCR с разными ссылками.
Кто-то говорит что нужно скачать файл с первого сайта.
Другой говорит: со второго.
Откуда скачивать? Может это одна и та же версия программы, просто выставлена на разных сайтах.
Просто названия у файлов разные:
На сайте pypi: pytesseract-0.3.8.tar.gz (Архив 14.6 kB).
Открываю файл setup.py в архиве. Открывается cmd и сразу же закрывается.
На гитхабе: tesseract-ocr-w64-setup-v5.0.0-rc1.20211030.exe (51мб).
Может вопрос немного тупой, но лучше спросить, чем потом мучиться.
- Вопрос задан более двух лет назад
- 3143 просмотра
Комментировать
Решения вопроса 1

soremix @SoreMix Куратор тега Python
Это два абсолютно разных файла.
Версия с pypi - это сама библиотека pytesseract.
Pytesseract - обертка для инструмента Tesseract. Бинарники Tesseract лежат на втором сайте, который вы указали.
Вам нужен как сам tesseract, так и библиотека для работы с ним в python.
Так что устанавливаем pytesseract
pip install pytesseract
Ответ написан более двух лет назад
Нравится 1 3 комментария
Ростислав Иванов @Slavik28 Автор вопроса
В гайде говорилось, что нужно выполнить 2 действия.
1. Установить саму программу PyTesseract OCR
2. Установить библиотеку в cmd: pip install pytesseract.
Получается, что программу Tesseract нужно скачать со второго сайта?