OLAP-технологии: обзор решаемых задач и исследований Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Кудрявцев Ю.
Рассматриваются технологии OLAP (OnLine Analytical Processing), вклюбчающие в себя дефиницию, исторический обзор исследований, обзор бизнес-приложений и существующих проблем при реализации решений подобного класса.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Кудрявцев Ю.
Определение эффективной частоты обновления данных в OLAP системах
Оценка объемов многомерного куба в OLAP-системах
Формальное описание расчета многомерных аналитических показателей в виде последовательности операций над OLAP-кубом
Интерактивная аналитическая обработка данных в современных OLAP-системах
Алгоритмы динамической генерации MDX-запросов к многомерным OLAP-кубам
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Текст научной работы на тему «OLAP-технологии: обзор решаемых задач и исследований»
0LAP-ТЕХН0Л0ГИИ: ОБЗОР РЕШАЕМЫХ ЗАДАЧ И ИССЛЕДОВАНИЙ
аспирант факультета Вычислительной математики и кибернетики Московского государственного университета
Рассматриваются технологии OLAP (OnLine Analytical Processing), вклюбчающие в себя дефиницию, исторический обзор исследований, обзор бизнес-приложений и существующих проблем при реализации решений подобного класса. J
ОПРЕДЕЛЕНИЕ ТЕРМИНА OLAP
Термин OLAP введён в 1993 г. Эдгаром Коддом [Cod93]. Цель OLAP-систем — облегчение решения задач анализа данных. Кодд сформулировал 12 признаков OLAP-данных, и большинство современных OLAP-средств отвечают этим постулатам. Перечислим их:
12 ПРИЗНАКОВ OLAP-ДАННЫХ
Многомерная концепция данных. OLAP оперирует CUBE-данными (см. далее описание работ Грея [GBLP95]), которые являются многомерными массивами. Число измерений OLAP-кубов не ограничено.
Прозрачность. OLAP-системы должны опираться на открытые системы, поддерживающие гетерогенные источники данных.
Доступность. OLAP-системы должны представлять пользователю единую логическую схему данных.
Постоянная скорость выполнения запросов. Производительность не должна падать при росте числа измерений.
Клиент/сервер архитектура. Системы должны базироваться на открытых интерфейсах и иметь модульную структуру.
Различное число измерений. Системы не должны ограничиваться трехмерной моделью представления данных. Измерения должны быть эквивалентны по применению любых функций.
Динамическое представление разреженных матриц. Под разреженной матрицей понимается матрица, не каждая ячейка которой содержит данные. OLAP-
системы должны содержать средства хранении и обработки разреженных матриц больших объёмов.
Многопользовательская поддержка. OLAP-системы должны поддерживать многопользовательский режим работы.
Неограниченные многомерные операции. Аналогично требованию о различном числе измерений: все измерения считаются равными, и многомерные операции не должны накладывать ограничения на отношения между ячейками.
Интуитивно понятные инструменты манипулирования данными. Для формулирования многомерными запросами пользователи не должны работать в усложнённых меню.
Гибкая настройка конечных отчётов. Пользователи должны иметь возможность видеть только необходимые им данные, причём все их изменения должны немедленно отображаться в отчётах.
Отсутствие ограничений. Отсутствие ограничений на количество измерений и уровней агрегации данных.
В дальнейшем Найджел Пендс переформулировал 12 правил Кодда в более ёмкий тест FASMI (Fast Shared Multidimensional Information). По его определению, OLAP-система должна быть:
^ Fast — быстрой, обеспечивать почти мгновенный отклик на большинство запросов;
^ Shared — многопользовательской, должен существовать механизм контроля доступа к данным и возможность одновременной работы многих пользователей;
^ Multidimensional — многомерной. Данные должны представляться в виде многомерных кубов;
Information — данные должны быть полны с точки зрения аналитика, т.е. содержать всю необходимую информацию.
Большинство из существующих OLAP-средств удовлетворяют всем этим признакам. Однако в реализации подобных приложений возникает ряд проблем, прежде всего связанных с увеличением объёма данных, которые необходимо хранить.
В 1995 г. группа исследователей во главе с Джеймсом Греем [GBLP95], проанализировав создаваемые пользовательские приложения баз данных, предложили расширение языка SQL — оператор CUBE. Данный оператор отвечает за создание OLAP-кубов в SQL. Концепция многомерного представления данных намного облегчила жизнь разработчикам и пользователям. В той же работе исследователи указали ряд эвристических рекомендаций по реализации новой структуры данных. CUBE представляет собой обобщение GROUP BY операторов по всем возможным комбинациям измерений с разными уровнями агрегации данных. Оператор, расширяющий SQL, называется CUBE BY (синтаксис такой же, как и у GROUP BY). В стандарт SQL’99 включён набор операторов для работы с OLAP-данными.
Расширения стандартов SQL-1999 и SQL-2003, восполняющие OLAP-функциональность языка SQL:
^ Grouping Set запросы;
^ Cube By запросы;
^ Rollup By запросы;
^ Window By запросы;
^ Model By запросы в Oracle 10g и выше.
Исследования в области многомерных массивов данных велись задолго до работ Грея, но его работа стала основополагающей в создании промышленных продуктов и расширении языка SQL.
БИЗНЕС-ПРИЛОЖЕНИЯ НА ОСНОВЕ OLAP-ТЕХНОЛОГИЙ, примеры продуктов
Наиболее часто встречаются следующие применения OLAP-технологий:
Анализ данных. Задача, для которой изначально использовались и до сих пор остаются самыми популярными OLAP-средства. Многомерная модель данных, возможность анализировать значительные объёмы данных и быстрый отклик на запросы делают подобные системы незаменимыми для анализа продаж, маркетинговых мероприятий, дистрибуции и других задач с большим объёмом исходных данных.
Примеры продуктов: Microsoft Excel Pivot Tables, Microsoft Analysis Services, SAP BW, Oracle Essbase, Oracle OLAP, Cognos PowerPlay, MicroStrategy, Business Objects.
Многомерная модель позволяет одновременно вводить данные и легко анализировать их (например, план-факт анализ). Поэтому ряд современных продуктов класса CPM (Corporate Performance Management) используют OLAP-модели. Важная задача — многомерный обратный расчёт (back-solve, breakback, writeback), позволяющий рассчитать требуемые изменения детальных ячеек при изменении агрегированного значения. Это инструмент для анализа «что-если» (what-if), т.е. для проигрывания различных вариантов событий при планировании.
Примеры продуктов: Microsoft PerformancePint, Oracle EPB, Oracle OFA, Oracle Hyperion Planning, SAP SEM, Cognos Enterprise Planning, Geac.
Финансовая консолидация. Консолидация данных согласно международным стандартам учёта, принимая во внимание доли владения, различные валюты и внутренние обороты — актуальная задача в связи с ужесточающимися требованиями проверяющих органов (SOX, Basel II) и выходом компаний на IPO. OLAP-технологии позволяют ускорить расчёт консолидированных отчётов и повысить прозрачность всего процесса.
Примеры продуктов: Oracle FCH, Oracle Hyperion FM, Cognos Controller.
МНОГОМЕРНЫЕ КУБЫ, ОПРЕДЕЛЕНИЕ И СВОЙСТВА
Рассмотрим базовую (фактическую) таблицу, на основе которой мы будем строить OLAP-куб. Множество атрибутов условно делят на 2 группы:
1. Набор измерений (категорий, локаторов), служащие критериями для анализа и определяющие многомерное пространство OlAP-куба. За счёт фиксации значений измерений получаются срезы (гиперплоскости) куба. Каждый срез представляет собой некий запрос к данным, включающий агрегации.
2. Набор мер — функции, ставящие данные в соответствие каждой точке пространства.
Из атрибутов создаются измерения, содержащие проекцию по атрибуту, с введённой иерархией (например, для таблицы, содержащей фактические данные по продажам магазина, возможно измерение «Время», содержащее иерархию вида «Год-Месяц-Неделя-День»). Куб представляет собой декартово произведение измерений, где для каждого элемента произведения проставлен набор мер.
В кубе существуют отношения обобщения и специализации (roll-up/drill-down) по иерархиям измерений. Ячейка высокого уровня иерархии может «спускаться» (drill-down) к ячейке низкого уровня. Например, (R1, ALL, весна) может «спуститься» к ячейке (R1, книги, весна) и наоборот, «подниматься» (roll-up) от (R1, книги, весна) к (R1, ALL, весна) по измерению «продукты».
Измерения. Измерения куба — набор доменов, по которым создаётся многомерное пространство. Важная особенность OLAP-моделей — разделение измерений на локаторы (задающие точки) и меры (задающие значение). Как отмечено в [Tho02], данное разделение может носить как условный, так и жесткий характер. В случае условного разделения возможно «разворачивать» измерения как данные и как аналитики, создавая новое значение куба по продажам — «количество продаж». Таким образом, чрезвычайно возрастает гибкость моделей и уровень абстракции. Однако данный подход, несмотря на свою привлекательность, чрезвычайно сложен в реализации (в частности, необходимость создания оптимальных алгоритмов хранения абстрактных типов данных) и, насколько известно, нигде промышленно не реализован. Теоретически, вкупе с моделированием структур логикой предикатов первого порядка, абстрагирование понятия «измерение» даёт очень интересные результаты.
Локаторы куба отличаются иерархической структурой, и для получения значений мер на каждом уровне агрегирования вводятся агрегирующие функции.
Иерархии и агрегирование. Иерархичность данных — одно из важнейших свойств многомерных кубов. Иерархии призваны добавлять новые уровни в аналитическое пространство пользователя. Самый распространённый пример иерархии — «месяц—неделя—год». Соответственно, для уровней иерархии работают отношения обобщения и специализации (rollup/drilldown). Как правило, в работах рассматриваются простые примеры иерархий «детальное значение — ALL», однако подобного уровня детализации может быть недостаточно.
Все иерархии можно разбить на 2 типа. Основой разбиения будет служить расстояние от корня до листов. Если расстояние одинаково до всех листов — иерархии уровневые (leveled), в другом случае — несбалансированные (ragged).
Примеры типов иерархий:
^ уровневые: день—месяц—год; улица — город — страна;
^ несбалансированные: Организационная диаграмма, различная группировка продуктов.
Важное свойство уровневых иерархий — возможное наличие частичного порядка внутри каждого уровня иерархии. Например, возможность сравнения месяцев по старшинству или городов по географическому положению. Большинство современных средств (алгоритмов) пренебрегают данным свойством, удаляя тем самым потенциально полезные связи модели.
Агрегирующие функции, меры и формулы. Неотъемлемая часть OLAP-модели — задание функций агрегирования. Поскольку цель OLAP — создание многоуровневой модели анализа, данные на уровнях, отличных от фактического, должны быть соответствующим образом агрегированы. По каждому измерению возможно задавать собственную (и не одну) функцию агрегации.
В [GC97] приведена следующая классификация агрегирующих функций с точки зрения сложности распараллеливания:
^ дистрибутивные функции позволяют разбивать входные данные и вычислять отдельные итоги, которые потом возможно объединять; ^ алгебраические функции возможно представить комбинацией из дистрибутивных функций (например, Average() можно представить как сумму, разделённую на count);
^ холистические функции невозможно вычислять на частичных данных или представлять каким-либо образом.
ХРАНЕНИЕ И ЭФФЕКТИВНЫЙ РАСЧЁТ OLAP-КУБОВ Материализация представлений. Главным свойством OLAP-систем считается возможность эффективно отвечать на запросы. Одна из мер повышения этой эффективности — материализация кубов, а не вычисление их «на лету» (вычисление агрегаций непосредственно во время обработки запроса).
Считается стандартным представление куба в виде т.н. решетки — графа, в котором узлы определяют представления (view) для ответа на запрос. Для каждого узла пометка обозначает измерения, по которым есть фактические данные в представлении; по пропущенным измерениям производится агрегация. Для трехмерного куба (регионы, продукты, время года) структура будет выглядеть следующим образом (рис. 1):
Таким образом, в получившейся структуре куба материализуется набор представлений, содержащий агрегированные данные. Подобные представления называются подкубами (англ cuboids). Ячейки базового подкуба называются базовыми ячейками,
Рис. 1. Структура куба в виде набора представлений для агрегации
ячейки других подкубов называются агрегированными ячейками.
Выбор материализованных элементов этого набора определяет будущую производительность системы. Мы можем получить набор представлений, при использовании которого для выполнения запросов не будет производиться более 1—2 агрегаций (по одному измерению), что означает очень быстрый ответ на запрос. И наоборот, возможна ситуация, в которой для ответа на запрос необходимо будет создавать все агрегации от фактических данных (базового куба). Однако количество подкубов экспоненциально зависит от количества измерений, поэтому полная материализация может требовать огромного объёма памяти и места на жестком диске.
Изучение алгоритмов полной материализации помогает в расчётах индивидуальных подкубов. В дальнейшем их можно хранить на второстепенных носителях, или же создавать полные кубы на основе подмножества измерений и осуществлять детализацию (drill-down) в исходные данные. Подобные алгоритмы должны быть масштабируемыми, принимать во внимание ограниченное количество оперативной памяти, время вычисления и общий размер рассчитанных данных.
Многие ячейки кубов могут не представлять интереса для аналитиков, так как данные в них пренебрежимо малы. Подобная ситуация возникает часто, так как данные разреженно распределены в многомерном пространстве куба. Например, клиент покупает каждый раз лишь несколько товаров в одном магазине. Подобное событие будет отражено в виде набора ячеек с малыми показателями мер (объём покупки, количество предметов). В таких случаях полезно вычислять лишь ячейки со значением меры, большим определённой границы.
Например, нас будут интересовать лишь покупки на сумму свыше 500 рублей. Такой подход позволяет точнее сфокусировать анализ, сократить время вычисления и отклика. Подобные частично вычисленные кубы называются кубами-айсбергами (англ. iceberg cubes), так большая часть их данных «скрыта под водой». Простой подход к вычислению кубов-айсбергов заключается в следующем: сначала вычислить весь куб, затем применить условие и отрезать неудовлетворяющие ячейки. Но это слишком расточительно. Нужно вычислять куб-айсберг, не вычисляя полный куб. Использование ограничений на значение меры может приводить к ситуациям, требующим бессмысленных повторных вычислений. Например, в стомерном кубе существуют всего 2 ячейки, отличающиеся по значениям одного измерения. Если меры в этих ячейках больше заданной границы, появится множество дублирующих эти суммы ячеек (по всем 99 измерениям), а на деле в кубе разнятся всего три из них.
Множество работ посвящено выбору комплекса представлений (подкубов) для материализации. Из них необходимо выделить [HRU96], где впервые приведена модель оценки стоимости материализации представлений и создания агрегаций. На базе подобных оценок создан алгоритм материализации представлений, оптимизирующий запросы по стоимости. Но применимость алгоритма [HRU96] и многих последующих сильно ограничена типами запросов, распределением данных, структурой куба и пр. Ограничения накладываются самими авторами, поэтому часто создаются эффективные алгоритмы. Доказано, что общая проблема выбора представлений для материализации NP-полна [KM99], поэтому интересной темой представляется создание алгоритмов полной материализации (materialize-all) куба, поскольку их применение не имеет подобных ограничений и не зависит от выбора начальных параметров. Необходимо заметить, что большинство промышленных OLAP-систем строятся на фактических данных, хранимых в реляционных таблицах, поэтому обоснованный выбор и последующая настройка набора материализованных представлений даёт результаты выше, чем существующие промышленные алгоритмы полной материализации.
Главная проблема подхода полной материализации (materialize-all) — это «взрыв данных», при котором объём данных и время вычисления куба растут экспоненциально. Например, десятимерный куб без иерархии внутри измерений, с размерностью 100 для каждого измерения, приводит к структуре с ячейками. Даже если мы положим разреженность 1 (только одна из миллиона ячеек содержит данные), куб всё
равно будет иметь 1,1А14 непустых ячеек. Таким образом, сокращение размера куба — насущная задача создателей OLAP-приложений.
Еще одно важное ограничение — требование сохранения семантики отношений обобщения/специализации (roll-up/drill-down). Отбрасывая это требование, многие алгоритмы достигают хороших результатов, но восстановление этих отношений в дальнейшем либо невозможно, либо трудно вычисляется, что ограничивает возможность применения подобных алгоритмов.
ROLAP (Relational OLAP) — данные, включающие в себя все возможные агрегации, хранятся в реляционных таблицах. Все запросы пользователя транслируются в SQL-операторы выборки из данной таблицы.
Плюсы данного подхода: все данные хранятся внутри одной СУБД в одном формате.
Минусы данного подхода: чрезмерное увеличение объёма таблицы данных для куба и сложности пересчёта агрегированных значений при изменениях начальных данных.
MOLAP (Multidimensional OLAP) — все данные хранятся в многомерной базе данных.
Все запросы пользователя транслируются в запросы многомерной выборки (MDX, Express 4GL и др).
Плюсы данного подхода: все данные хранятся в многомерных структурах, что существенно повышает скорость обработки запросов.
Минусы данного подхода: данные куба «оторваны» от базовой таблицы, необходимы специальные инструменты для формирования кубов и их пересчёта в случае изменения базовых значений.
HOLAP (Hybrid OLAP) — базовые данные хранятся в реляционной таблице, агрегированные — в многомерной структуре.
Данный метод пытается совмещать достоинства предыдущих, не имея их недостатков, но по скорости он проигрывает MOLAP. Кроме того, с его помощью невозможно целостное хранение данных и возрастают затраты на поддержку и определение типа хранения для подкубов.
OLAP-технологии — актуальная и востребованная тема исследований, её практические результаты имеют широкое применение.
Несмотря на достаточно долгую историю исследований, до сих не существует единых терминологических стандартов, стандартов передачи данных, языка запросов и формирования кубов. Растущие объёмы корпоративных данных повышают значимость средств анализа, большая часть которых построена на OLAP-принципах, в связи с чем актуальны проблемы выбора оптимальных схем хранения и обработки OLAP-кубов. Интеграция различных источников информации для анализа порождает новые применения аналитических технологий, например, для анализа данных геопозиционирования (GPS) в привязке к финансовой информации используются spatioOLAP-технологии. Задачи бюджетирования, требующие совмещения скорости ввода транзакционных систем и аналитических возможностей OLAP, представляют собой особый класс систем, алгоритмическая база которых только создается. ■
[AS94] Rakesh Agrawal and Ramakrishnan Srikant. Fast algorithms for mining association rules. In Jorge B. Bocca, Matthias Jarke, and Carlo Zaniolo, editors, Proc. 20th Int. Conf. Very Large Data Bases, VLDB, pages 487-499. Morgan Kaufmann, 12-15 1994.
[BR99] Kevin Beyer and Raghu Ramakrishnan. Bottom-up computation of sparse and iceberg cubes. In SIGMOD, 1999.
[Cod93] E.F. Codd. Providing OLAP for end-user analysys: An IT mandate. 1993.
[GBLP95] Jim Gray, Adam Bosworth, Andrew Layman, and Hamid Pirahesh. Data cube: A relational aggregation operator generalizing group-by, cross-tab, and sub-totals. Microsoft Lab, 1995.
[GC97] Sanjay Goil and Alok Choudhary. High performance olap and data mining on parallel computers. Center of Parallel and Distributed Computing Technical Report TR-97-05, 1997.
[HRU96] Venky Harinarayan, Anand Rajaraman, and Jeffrey Ulman. Implementing data cubes efficiently. SIGMOD, 1996.
[KM99] H.J. Karloff and M. Mihail. On the complexity of view-selection problem. In PODS, 1999.
[SG99] Gerd Stumme and Bernhard Ganter. Formal Concept Analysis — Mathematical Foundations. Springer, 1999.
[SR04] Yannis Sismanis and Nick Roussopoulos. The polynomial complexity of fully materialized coalesced cubes. In VLDB, 2004.
[SS01] Sunita Sarawagi and Gayatri Sathe. Intelligent rollups in multidimensional olap data. In VLDB, 2001.
[Tho02] Erik Thomsen. OLAP Solutions: Building Multidimensional Information Systems Second Edition. Wiley Computer Publishing John Wiley & Sons, Inc., 2002.
Описание куба «ESC-OLAP»
OLAP (Online Analytical Processing) — это технология комплексного многомерного анализа деловой информации с помощью многомерных кубов. Осями в системе координат кубов служат основные атрибуты анализируемого бизнес-процесса (измерения). Например, для продаж измерения — это Товар, Регион, Тип покупателя и Время. На пересечениях осей-измерений находятся данные, количественно характеризующие процесс (объемы продаж в упаковках или в денежном выражении, остатки на складе, заработанные бонусы и тому подобные), их называют меры. Для анализа информации необходимо «разрезать» куб по разным направлениям и получать сводные (например, по годам) или, наоборот, детальные (по неделям) сведения и осуществлять любые другие манипуляции.
Проблема в том, что даже трехмерный куб сложно отобразить на экране компьютера так, чтобы были видны значения интересующих мер — чего уж говорить о кубах с количеством измерений больше трех. Да и мер требуется больше одной. Поэтому для визуализации данных, хранящихся в кубе, применяются привычные двумерные (табличные) представления, имеющие иерархические заголовки строк и столбцов.
В качестве примера рассмотрим трехмерный куб, в котором существуют Продажи в упаковках как меры, а Товар, Аптеки и Время — как измерения.
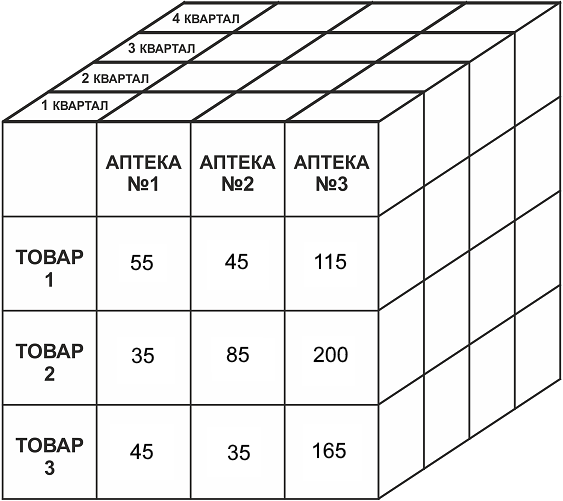
Двумерные представления куба можно получить, «разрезав» его поперек одной или нескольких осей (измерений): фиксируем значения всех измерений, кроме двух — и получаем обычную двумерную таблицу. В горизонтальной оси таблицы (заголовки столбцов) будет одно измерение, в вертикальной (заголовки строк) — другое, а в ячейках таблицы — значения мер.
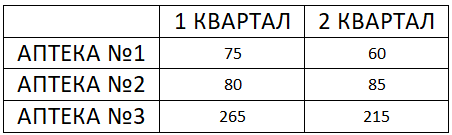
На рисунке изображен двумерный срез куба для одной меры — Продажи в упаковках и двух измерений — Аптека и Время:
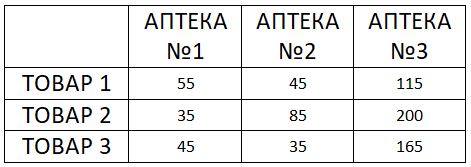
Или для измерений Товар и Аптека:
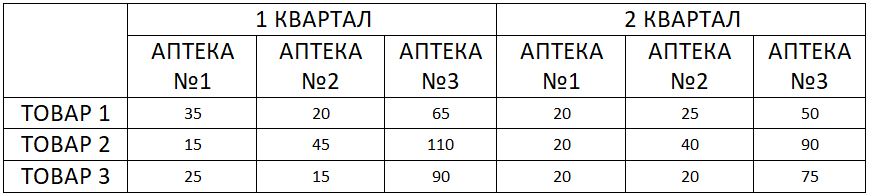
Различные измерения могут «комбинироваться»:
Кроме того, измерения могут иметь группировки, например товары по категориям, аптеки — по регионам, а данные о времени совершения операций — по годам.
Можно все требуемые меры и измерения разместить в одном многомерном кубе, но пользоваться им будет слишком сложно. Оптимальнее «собрать» несколько специализированных кубов для анализа ограниченного количества взаимосвязанных мер в присущем им количестве измерений.
В случае разрыва соединения система выдаёт сообщение Связь с сервером потеряна. При нажатии на кнопку ОК происходит переход на главную страницу portal.esc.ru.
Описание куба «ESC-OLAP»¶
Окно программы состоит из следующих элементов:

- Панель управления — содержит кнопки, позволяющие выбирать куб, запускать построение отчёт, сохранять и загружать шаблоны отчётов, выгружать отчёты в MS Excel, а также управлять аккаунтом пользователя.
- Панель мер — содержит список мер. Мнемоническое правило «меры — что показываем». Подробнее см. Описание мер.
- Панель измерений — содержит список измерений. Мнемоническое правило «измерения — для чего показываем».
- Шаблон отчёта — содержит набор данных и фильтров, по которым строится отчёт.
- Отчёт — собственно, сам отчёт. Занимает всю правую часть окна.
1. Панель управления¶

Панель управления имеет следующие кнопки и выпадающие списки:

- — позволяет выбрать тип куба, по которому будет строиться отчёт. При нажатии на стрелочку открывается выпадающий список со всеми доступными кубами:
- Трансформация
- Бонусы для аптек
- Закупка
- Закупка план
- Закупка групповая
- Обязательная матрица
- Выкладка
- Товар дня
- Компенсация скидки
- Доп бонус за продажу
- УСТМ
- Общий отчёт по бонусам
- Бонусы по промотоварам
- Рекомендованный товар
- Недопустимые поставщики
- Детализация бонусов
- Потенциальная аптека
- Данные
- Контроль качества данных
- Получение данных
- Сравнение данных
- Остатки
- Контракты
- Контракты
- Союз
- Отчёты по аптекам
- Ассортимент аптек
- Что с чем продаётся
- Розничные продажи
- Замена номенклатур

 (Очистить запрос) — сбрасывает все настройки Шаблона отчёта.
(Очистить запрос) — сбрасывает все настройки Шаблона отчёта. — запускает построение отчёта в соответствии с выбранными мерами, измерениями и фильтрами в Шаблоне отчёта.
— запускает построение отчёта в соответствии с выбранными мерами, измерениями и фильтрами в Шаблоне отчёта. — позволяет вернуться к предыдущему запросу.
— позволяет вернуться к предыдущему запросу. — позволяет не выводить построенный отчёт на экран (сокращает время на получение отчёта) и предоставляет ссылку для выгрузки отчёта напрямую в Excel:
— позволяет не выводить построенный отчёт на экран (сокращает время на получение отчёта) и предоставляет ссылку для выгрузки отчёта напрямую в Excel: 
 — сохраняет отчёт в файл формата .XLSX.
— сохраняет отчёт в файл формата .XLSX. — позволяет сохранить набор мер, измерений и фильтров из текущего Шаблона отчёта в файл формата .yml.
— позволяет сохранить набор мер, измерений и фильтров из текущего Шаблона отчёта в файл формата .yml. — позволяет загрузить сохранённый ранее набор мер, измерений и фильтров в Шаблон отчёта из файла формата .yml.
— позволяет загрузить сохранённый ранее набор мер, измерений и фильтров в Шаблон отчёта из файла формата .yml. — позволяет выбрать встроенный шаблон отчёта. При нажатии на стрелочку открывается выпадающий список со всеми доступными отчётами:
— позволяет выбрать встроенный шаблон отчёта. При нажатии на стрелочку открывается выпадающий список со всеми доступными отчётами:
- Бонусы
- Обязательная матрица, стандартный отчёт
- Товар дня, стандартный отчёт
- УСТМ, стандартный отчёт
- Общий отчёт, стандартный
- Рекомендованный товар, стандартный отчёт
- Компенсация скидки, стандартный отчёт
- Недопустимые поставщики, стандартный отчёт
- Данные
- Получение данных, стандартный отчёт
 — позволяет создать отчёт с возможностью детализировать каждое значение в максимально возможном количестве измерений («провалиться», «развернуть» — drilldown). Для этого необходимо щелкнуть по выключателю Детализация (он переключится в положение вкл
— позволяет создать отчёт с возможностью детализировать каждое значение в максимально возможном количестве измерений («провалиться», «развернуть» — drilldown). Для этого необходимо щелкнуть по выключателю Детализация (он переключится в положение вкл ) и построить отчёт кнопкой :
) и построить отчёт кнопкой : 
Примечание При включённой детализации время формирования отчёта может увеличится в несколько раз.
2. Панель мер¶
Меры будут отображаться в отчёте как данные в ячейках таблицы на пересечении различных измерений. Мнемоническое правило «что показываем».

- Кнопка позволяет добавить меры из Панели мер в Шаблон отчёта, на основании которого строится отчёт. Подробнее см. Шаблон отчёта ниже.
3. Панель измерений¶
Содержит измерения, на пересечении которых будут находиться меры (данные, количественно характеризующие процесс). Например, Регион, Юр.лицо, Аптека, Период. Мнемоническое правило «для чего показываем».

- Кнопки
 позволяют добавлять измерения в Шаблон отчёта, на основании которого строится отчёт:
позволяют добавлять измерения в Шаблон отчёта, на основании которого строится отчёт:
- Кнопка
 добавляет выбранную позицию в Колонки создаваемого шаблона отчёта.
добавляет выбранную позицию в Колонки создаваемого шаблона отчёта. - Кнопка
 добавляет выбранную позицию в Строки создаваемого шаблона отчёта.
добавляет выбранную позицию в Строки создаваемого шаблона отчёта. - Кнопка
 добавляет выбранную позицию в Фильтры создаваемого шаблона отчёта.
добавляет выбранную позицию в Фильтры создаваемого шаблона отчёта. - Значения измерения (Все) выводит в отчёт строку или столбец с просуммированными значениями мер для всех объектов в измерении.
- Кнопка
4. Шаблон отчёта¶
Шаблон отчёта состоит из четырёх окон:
- Меры — содержит список мер, которые будут выведены в отчёт.
- Колонки — содержит список измерений, по которым будут сформированы колонки в отчёте.
- Строки — содержит список измерений, по которым будут сформированы строки в отчёте.
- Фильтры — содержит список фильтров.
Списки во всех окошках управляются идентичными инструментами.
- Кнопка позволяет добавлять меры и фильтры из Панели мер в Шаблон отчёта.
- Кнопка
 позволяет удалить меры из Шаблона отчёта. Удалённая мера возвращается обратно в Панель мер.
позволяет удалить меры из Шаблона отчёта. Удалённая мера возвращается обратно в Панель мер. - Кнопки
 позволяют изменить порядок отображения мер или иерархию измерений.
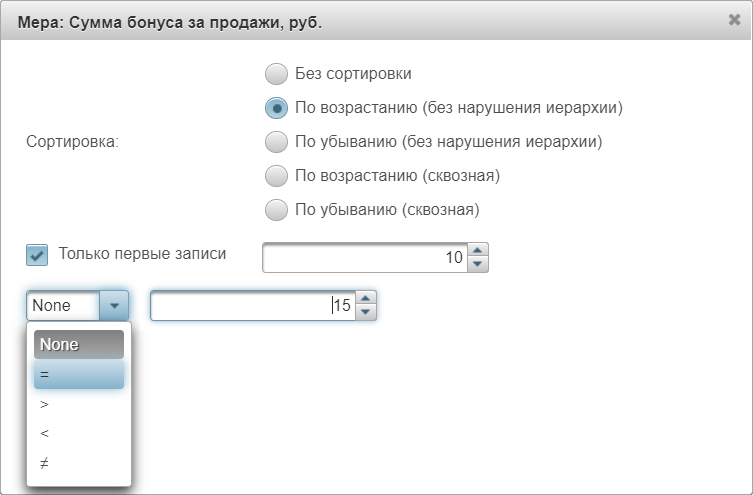
позволяют изменить порядок отображения мер или иерархию измерений. - Кнопка
 для Мер вызывает окно, в котором можно выбрать тип сортировки и фильтрации данных:
для Мер вызывает окно, в котором можно выбрать тип сортировки и фильтрации данных:
- Сортировка:
- Без сортировки — сортировки нет.
- По возрастанию (без нарушения иерархии) — сортировка от меньшего к большему, с учётом иерархии.
- По убыванию (без нарушения иерархии) — сортировка от большего к меньшему, с учётом иерархии.
- По возрастанию (сквозная) — сортировка от меньшего к большему, без учёта иерархии.
- По убыванию (сквозная) — сортировка от большего к меньшему, без учёта иерархии.
- Фильтрация:
- Только первые записи — при установке «галочки» позволяет отфильтровать выбранное количество первых записей.
- None — выпадающий список с полем для ввода числа, имеющий следующие возможные значения:
- None — значения нет, фильтрация не работает;
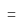 — равно, отображаются значения, равные введённому числу;
— равно, отображаются значения, равные введённому числу;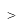 — меньше, отображаются значения, не превышающие введённое число;
— меньше, отображаются значения, не превышающие введённое число;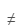 — не равно, отображаются значения, не равные введённому числу.
— не равно, отображаются значения, не равные введённому числу.
Единовременно может быть активна либо фильтрация только по первым записям, либо по значениям выпадающего списка.
- Кнопка для измерений вызывает окно с вкладками Фильтр и Свойства. Во вкладке Фильтр можно выбрать конкретные значения измерений для отчёта:
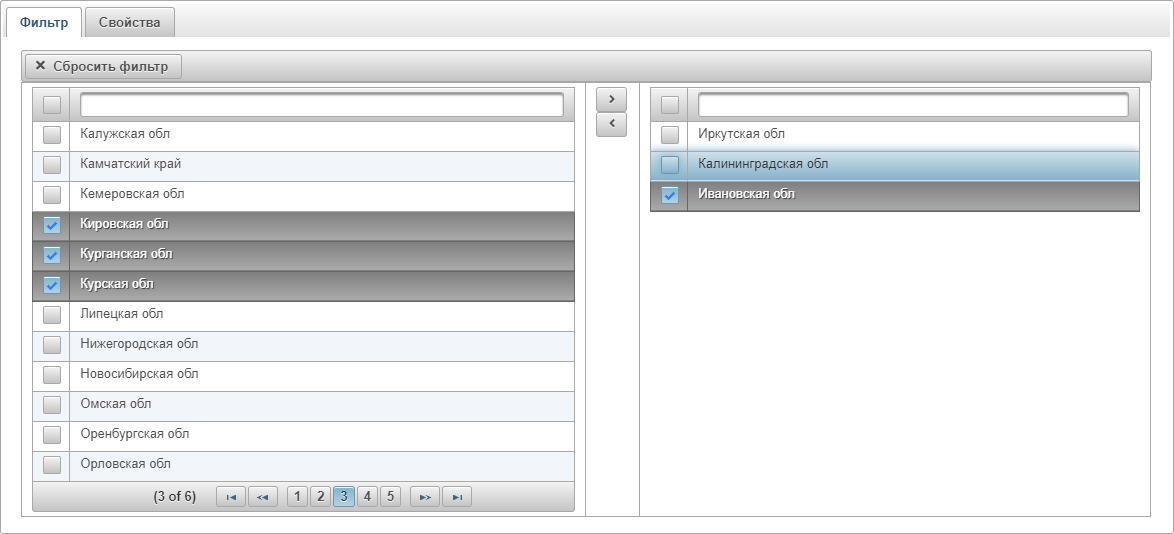
- Кнопка
 перемещает позицию из списка фильтров слева в активные фильтры справа.
перемещает позицию из списка фильтров слева в активные фильтры справа. - Кнопка
 перемещает позицию из активных фильтров справа в список фильтров слева.
перемещает позицию из активных фильтров справа в список фильтров слева.
Во вкладке Свойства можно выбрать конкретные значения свойств, которые будут отображены в отчёте, или указать, отображать ли значения этих свойств в отчёте:
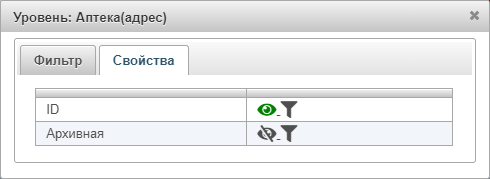
- ID — идентификационный номер аптеки.
- Архивная — отображать ли в отчёте архивные аптеки (по умолчанию значение «не отображать»)
- Кнопка
 позволяет указать, отображать или нет значения этих свойств в отчёте.
позволяет указать, отображать или нет значения этих свойств в отчёте. - Кнопка
 позволяет выбрать конкретные значения свойств, которые будут отображены в отчёте. Откроется окно Свойство:
позволяет выбрать конкретные значения свойств, которые будут отображены в отчёте. Откроется окно Свойство: 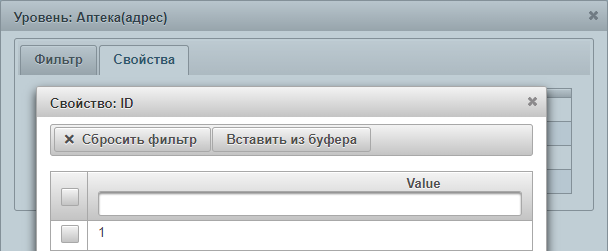
- Кнопка Сбросить фильтр позволяет очистить выбранные пользователем фильтры.
- Кнопка Вставить из буфера позволяет вставить информацию, скопированную в буфер обмена. При этом открывается окно Вставить из буфера:
- Кнопка
5. Отчёт¶
Вся правая часть окна отведена под отчёт, который можно построить на основании созданного набора параметров и фильтров из Шаблона отчёта нажатием на кнопку .
Какой из инструментов excel является olap технологией

Возможность быстрого построения сложной аналитики простыми средствами позволяет экономить самый ценный и невосполнимый ресурс – время. Поэтому OLAP для бизнес-пользователей – не просто инструмент, а необходимая часть финансовой и управленческой культуры компании, ее конкурентное преимущество. Эксперты прогнозируют технологическую эволюцию в сегменте OLAP, делая при этом ставку на ключевые тренды развития всего ИТ-рынка: мобильность, персонификацию, социализацию.
Хорошо структурированные базы данных – это первое, но не единственное условие успешной работы современного аналитика. Для надежной визуализации и оперативного сравнения при изучении различных «срезов» хранящихся массивов информации специалисту нужен гибкий инструмент. В качестве такого инструмента давно и хорошо зарекомендовал себя OLAP – (online analytical processing, аналитическая обработка в реальном времени) — технология обработки информации, включающая составление и динамическую публикацию отчетов и документов.
Главный мотив использования OLAP – его скорость. Он позволяет сделать «снимок» реляционной базы данных и структурирует ее в пространственную модель. Обработка запросов в OLAP происходит примерно в тысячу раз быстрее, чем при запросах в реляционную БД. В настоящее время на рынке представлен достаточно широкий выбор инструментов. Наиболее известные OLAP-продукты выпускают SAP, Microsoft, IBM, Oracle, SAS. Среди пользователей распространены два подхода к выбору BI-инструментария: предпочтение на основе подхода best of breeds и использование интегрированной платформы. Кроме того, OLAP со временем превратился в некую концепцию, объединяющую методологию, инструментарий и ставшую относительно независимой от вендоров.
Вместе с бизнесом
Значение OLAP для пользователей состоит в возможности обеспечить высокую скорость создания отчетов в рамках специализированного хранилища данных, получить данные для выполнения различных видов анализа, разграничить возможности работы для разных групп пользователей в соответствии с политиками безопасности, реализовать многомерные модели данных, то есть строить отчеты в различных разрезах, но на едином источнике информации.
Основная группа пользователей OLAP — акционеры, руководители предприятий и владельцы бизнес-процессов, руководители подразделений, бизнес-аналитики. «Ключевое преимущество использования OLAP, в идеале трансформирующееся в прямую выгоду, — это оперативный доступ к информации, представленной в том объеме и в той аналитической «нарезке», которая нужна управленцу для принятия решения, а исполнителю – для выполнения поставленной задачи», — отмечает заместитель руководителя практики ВРМ-решений NaviCon Group Алексей Куницын.
Впрочем, некоторые специалисты советуют не переоценивать значения OLAP — для бизнеса это всего лишь один из способов получения данных для анализа. Директор департамента аналитических систем компании «Микротест» Сергей Борисов признает, что у OLAP-технологии есть свои преимущества перед OLTP (Online Transaction Processing, обработка транзакций в реальном времени. При таком способе организации БД система работает с транзакциями, небольшими по размерам, но идущими большим потоком). Однако, по его мнению, хорошо спроектированное хранилище данных для аналитической отчетности может легко свести на нет все преимущества OLAP.
«Семья» OLAP: 3+1
По способу хранения данных OLAP можно разделить на три основных типа.
ROLAP (реляционный OLAP) – классический тип. К его несомненным достоинствам относится интуитивно-понятный интерфейс, простота в реализации. В ряде случаев он позволяет обходиться без прослойки в виде хранилища данных, обращаясь непосредственно к данным исходных систем. Существует масса программных продуктов ROLAP на любой вкус и бюджет, в том числе — open source. «Наиболее серьезным недостатком этого типа является невысокая скорость формирования отчетов, — предупреждает г-н Куницын. — А увеличение быстродействия обойдется дорого. Или очень дорого».
«ROLAP не несет никаких агрегированных значений, при получении данных все расчеты проводятся «на лету», здесь маленькие размеры кубов, он очень хорошо подходит для мер, рассчитываемых по агрегатной функции distinct count, — считает г-н Борисов. — Однако при недостаточных вычислительных мощностях сервера период отклика при первичном обращении к кубу будет очень длительным. Ведь на эффективность использования кубов, построенных по ROLAP технологии, очень большое влияние оказывает кэш OLAP-сервера».
MOLAP (многомерный OLAP) был придуман для того, чтобы победить недостатки ROLAP. В отличие от «ближайшего родственника» он работает быстро, предоставляет массу возможностей оптимизации для разработчика модели. Но и он не лишен недостатков. «Главный минус – низкая оперативность обновления данных, — считает г-н Куницын. — С этим можно бороться, но необходимы дополнительные трудозатраты и, следовательно, финансы». Г-н Борисов отмечает, что MOLAP, безусловно, является технологией, позволяющей ощутить все преимущества использования OLAP: время отклика от полностью рассчитанного куба MOLAP будет минимальным. Однако при использовании MOLAP есть существенный риск, что куб превысит все разумные размеры. Особенно это относится к хранению предрассчитанных агрегатов по полуаддитивным мерам.
Эксперты по-разному оценивают преимущества и недостатки двух перечисленных типов систем. Но, если резюмировать, то «плюсы» и «минусы» буду выглядеть так. MOLAP, наиболее «быстрый» тип систем, ценен возможностями для расчета и хранения всех необходимых наборов данных, в том числе — агрегатов. Его недостатки заключаются в ограничениях на количество измерений из-за производительности и в высокой потребности в объемах мест для хранения. ROLAP, проигрывая с точки зрения быстродействия за счет работы с агрегатами и другой специфики, выигрывает в покрытии данных и экономии места.
HOLAP(гибридный OLAP) занимает промежуточную позицию между ROLAP и MOLAP. По словам г-на Борисова, гибридная технология HOLAP наиболее интересна с практической точки зрения. «При наличии на OLAP-сервере возможностей для ручного управления агрегатами эта технология предоставляет разработчику возможность найти баланс между преимуществами и недостатками первых двух», — объясняет он.
Существует еще один современный быстроразвивающийся метод — In-memory OLAP («аналитика в оперативной памяти»). Он очень быстро позволяет не только читать данные из куба, но и добавлять свои данные (например, фактические к плановым) и производить быстрое моделирование «что — если». К недостаткам можно отнести тот факт, что размер куба ограничен размером доступной RAM. В корпоративных системах эта проблема решается разделением кубов на разделы, хранящиеся на разных серверах. Как правило, в In-memory закрытая архитектура. В некоторых системах производительность напрямую зависит от того, какого производителя CPU используется на сервере.
Классификация по локализации
OLAP также можно классифицировать «по локализации». Персональный или настольный OLAP (локальные кубы Excel, PowerPivot, ряд других систем) – характеризуется удобством, быстротой, яркой и наглядной итоговой диаграммой. Персональный OLAP позволяет решить многие проблемы конкретного пользователя благодаря возможности задействовать все доступные ему источники информации и аналитические разрезы. «Но при этом велик риск возникновения «множественных версий правды» в масштабах предприятия, поскольку каждый формирует отчет на основании собственных данных, хранящихся, к примеру, в Excel, — высказывает опасения г-н Куницын. — Поэтому зачастую у каждого в результате получается своя «версия истины». Соответственно, сколько сотрудников формируют отчет – столько версий на выходе и получаем».
Корпоративный OLAP (централизованный), как правило, характеризуется использованием очень мощных инструментов. Кроме собственно средств анализа он предоставляет массу дополнительной функциональности. «Версионность правды» здесь побеждена или сведена к минимуму. Главный его недостаток: если какого-либо аналитического справочника или показателя нет в корпоративном хранилище данных – то можно считать, что его нет в природе, и, следовательно, он не будет учитываться в отчетах. По крайней мере, до тех пор, пока до просьб пользователя не снизойдут ИТ-специалисты.
Векторы развития OLAP
Пожалуй, самой яркой современной тенденцией развития OLAP с точки зрения бизнес-пользователей стало обеспечение доступа к OLAP-отчетам с мобильных устройств. «Появляются новые интересные технологические возможности для интеграции с различными внешними источниками, расширяются возможности для анализа данных, поступающих из потоковых источников с выполнением основных вычислений «на лету»», — перечисляет наиболее значимые тренды руководитель практики Microsoft BI компании «Микротест» Альберт Хайдаров.
Г-н Куницын, в свою очередь, выделяет в числе основных такую тенденцию, как персонализация: в корпоративные системы OLAP добавляются возможности работы одновременно с локальными данными пользователя и информацией из корпоративного хранилища данных. Еще одним ярким трендом стал оффлайн-анализ: в корпоративные системы добавляется функциональность, позволяющая пользователю извлекать определенный набор данных из централизованного хранилища в виде интерактивного отчета для работы без подключения к сети. Эксперты также обращают внимание на все более тесную интеграцию OLAP и социальных сетей. Это неудивительно: бизнес получает все больше полезной информации посредством web 2.0, поэтому ему необходим гибкий инструмент для анализа.
В ближайшей перспективе, по прогнозам г-на Хайдарова, основными направлениями развития технологий OLAP станут гибкость по отношению к набору данных, скорость добавления новых наборов данных, скорость добавления новых источников исходной информации, расширение ad-hoc возможностей, удешевление стоимости продуктов и поддержки. «В функциональном плане OLAP, скорее всего, будет развиваться исходя из вышеописанных трендов – в сторону «мобильно-персонализированного-социально-ориентированного» real-time анализа», — добавляет г-н Куницын.
Наиболее интересным с технологической точки зрения трендом обещает стать развитие In-memory OLAP и ее схватка с технологией In-memory DataBase. В техническом плане, по мнению BI-экспертов, наиболее вероятной выглядит эволюция OLAP в сторону расширения применения высокопроизводительных in-memory OLAP и ROLAP на базе параллельных и/или column-oriented СУБД.
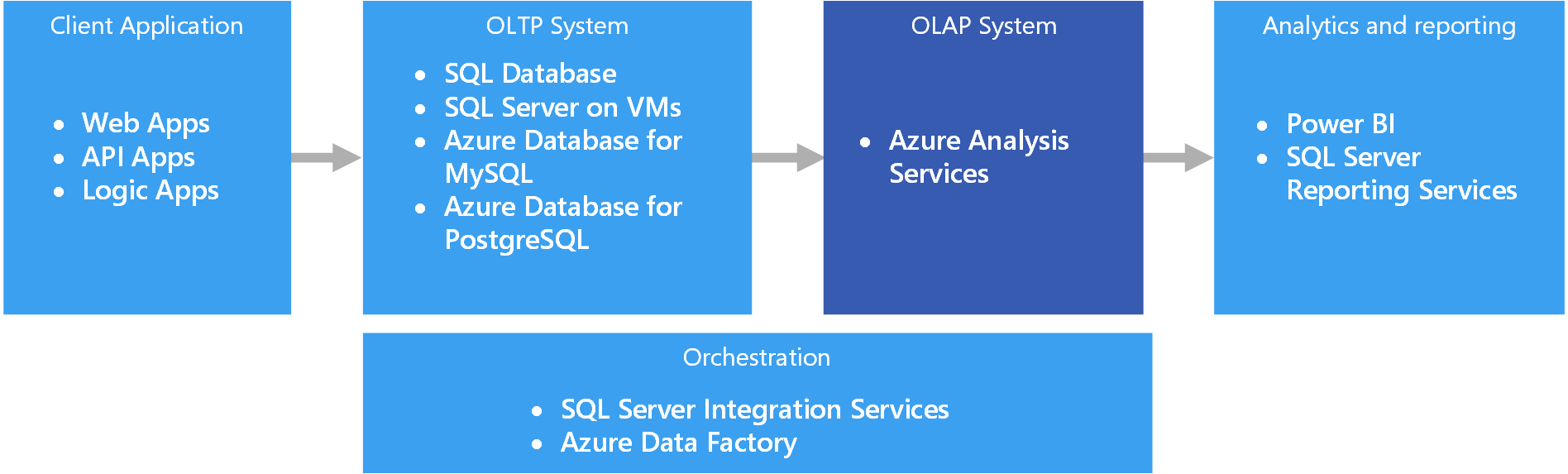
Оперативная аналитическая обработка (OLAP)
Оперативная аналитическая обработка (OLAP) — это технология, которая упорядочивает большие коммерческие базы данных и поддерживает сложный анализ. Ее можно использовать для выполнения сложных аналитических запросов без негативного воздействия на системы транзакций.
Базы данных, в которых компании хранят свои транзакции и записи, называются базами данных оперативной обработки транзакций (OLTP). Такие базы данных обычно содержат записи, которые вводятся поочередно. Часто они содержат много ценных для организации сведений. Но базы данных, используемые для OLTP, не предназначены для анализа. Поэтому извлечение ответов из этих баз данных требует много времени и усилий. Системы OLAP предназначены для извлечения этих сведений бизнес-аналитики из данных максимально оптимальным способом. Это достигается благодаря тому, что базы данных OLAP оптимизированы для рабочих нагрузок с большим числом операций чтения и малым числом операций записи.
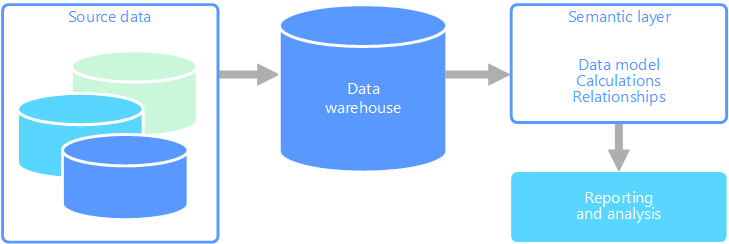
Семантическое моделирование
Семантическая модель данных — это концептуальная модель, в которой описаны значения содержащихся в ней элементов данных. Организации часто используют собственные термины, иногда синонимы или даже разные значения одного и того же термина. Например, база данных инвентаризации может отслеживать компонент оборудования с ИД ресурса и серийным номером. Но база данных по продажам может ссылаться на серийный номер как на идентификатор ресурса. Эти значения сложно связать без модели, в которой бы описывалась связь.
Семантическое моделирование обеспечивает абстракцию на уровне схемы базы данных. В этом случае пользователям не требуются знания о базовых структурах данных. Семантическое моделирование также упрощает подачу запросов данных для пользователей: им не нужно выполнять вычисления и соединения в базовой схеме. Кроме того, обычно имена столбцов преобразуются в понятные пользователям названия, чтобы контекст и значение данных были очевидными.
Семантическое моделирование преимущественно используется для сценариев с большим числом операций чтения, например для аналитики и бизнес-аналитики (OLAP), которые отличаются от обработки данных о транзакциях с большим числом операций записи (OLTP). В основном это связано с особенностями типичного семантического слоя:
- поведение агрегатов задано так, чтобы в средствах создания отчетов правильно отображались соответствующие данные;
- определены бизнес-логика и вычисления;
- включены ориентированные на время вычисления;
- данные часто интегрируются из нескольких источников.
По этим причинам семантический слой обычно размещается над хранилищем данных.
Есть два основных типа семантических моделей:
- Табличная. Используются реляционные конструкции моделирования (модели, таблицы, столбцы). На внутреннем уровне метаданные наследуются из конструкций моделирования OLAP (кубы, измерения, меры). В коде и скрипте используются метаданные OLAP.
- Многомерная. Используются традиционные конструкции моделирования OLAP (кубы, измерения, меры).
Соответствующие службы Azure:
Примеры использования
Данные организации хранятся в большой базе данных. Доступ к ним нужно предоставить бизнес-пользователям и клиентам, чтобы они могли создавать собственные отчеты и проводить анализ. Одно из решений — просто предоставить пользователям прямой доступ к базе данных. Но это решение имеет недостатки, например проблемы с безопасностью и управлением доступом. Кроме того, структура базы данных, в том числе имена таблиц и столбцов, может быть сложной для пользователя. Пользователям потребуется понять, к каким таблицам выполнять запросы, как эти таблицы должны объединяться, а также другие факторы бизнес-логики, которые следует учитывать для получения правильных результатов. Чтобы приступить к работе, пользователи также должны знать язык запросов, например SQL. Обычно это приводит к тому, что несколько пользователей предоставляют в отчете одни и те же метрики, но с разными результатами.
Второй вариант решения — инкапсулировать всю информацию, необходимую пользователям, в семантическую модель. Пользователям будет проще отправлять запросы к семантической модели с помощью любого удобного средства создания отчетов. Данные, предоставленные семантической моделью, извлекаются из хранилища данных. Благодаря этому все пользователи получают единую версию данных. Семантическая модель также предоставляет понятные имена таблиц и столбцов, связи между таблицами, описания, удобные функции вычисления и безопасность на уровне строк.
Типичные признаки семантического моделирования
Семантическое моделирование и аналитическая обработка обычно имеют следующие признаки:
Требование Description Схема Схема при записи (строгое соблюдение) Использование транзакций No Стратегия блокировки нет Возможность обновления Нет (обычно требуется повторное вычисление куба) Возможность добавления Нет (обычно требуется повторное вычисление куба) Рабочая нагрузка Большое число операций чтения, только для чтения Индексирование Многомерное индексирование Размер данных Небольшой и средний размер Модель Многомерная Форма представления данных Схема типа «снежинка», куб или звезда Гибкость запросов Высокая гибкость Scale (Масштаб): Большой (от десятков до сотен ГБ) Когда следует использовать это решение:
Рекомендуем использовать OLAP в следующих сценариях:
- если нужно выполнять сложные аналитические и нерегламентированные запросы быстро и без негативного воздействия на системы OLTP;
- если нужно предоставить бизнес-пользователям компании простой способ создания отчетов на основе ваших данных;
- если нужно предоставить много агрегатов, с помощью которых пользователи смогут оперативно получать согласованные результаты.
Технология OLAP особенно полезна при выполнении статистических вычислений для больших объемов данных. Системы OLAP оптимизированы для сценариев с большим числом операций чтения, например для анализа и бизнес-аналитики. OLAP позволяет пользователям сегментировать многомерные данные на срезы, которые можно просматривать в двух измерениях (например, в сводной таблице), или фильтровать данные по определенным значениям. Этот процесс иногда называется «сегментирование и фрагментирование» данных. Его можно выполнять, даже если данные секционированы по нескольким источникам. Такой процесс помогает пользователям определять тенденции, выделять шаблоны и просматривать данные без специальных знаний о традиционном анализе.
Семантические модели помогают бизнес-пользователям абстрагировать сложности связей и быстро анализировать данные.
Сложности
При всех преимуществах систем OLAP они создают и некоторые проблемы:
- Данные в системах OLTP постоянно обновляются за счет транзакций, передаваемых в из разных источников, а хранилища данных OLAP обычно обновляются гораздо реже, в зависимости от потребностей компании. Это означает, что системы OLAP скорее подходят для стратегических бизнес-решений, чем для немедленной реакции на изменения. Кроме того, для поддержки хранилищ данных OLAP в актуальном состоянии необходимо запланировать определенный уровень очистки данных и оркестрации.
- В отличие от традиционных нормализованных реляционных таблиц в системах OLTP, модели данных OLAP обычно являются многомерными. Из-за этого бывает сложно или невозможно непосредственно сопоставить отношения сущностей или объектно-ориентированные модели, где каждый атрибут сопоставляется с одним столбцом. Поэтому вместо традиционной нормализации в системах OLAP обычно используются схемы типа «снежинка» или «звезда».
OLAP в Azure
В Azure данные, хранящиеся в системах OLTP, например в службе «База данных SQL», копируются в систему OLAP, например в Azure Analysis Services. Средства просмотра и визуализации данных, в том числе Power BI, Excel и решения сторонних производителей, подключаются к серверам Analysis Services и предоставляют пользователям интерактивные визуальные представления моделей данных для анализа. Поток данных из системы OLTP в OLAP обычно оркестрируется с помощью SQL Server Integration Services и службы Фабрика данных Azure.
Все следующие хранилища данных в Azure будут соответствовать основным требованиям для OLAP:
- SQL Server с индексами columnstore;
- Azure Analysis Services;
- Службы SQL Server Analysis Services (SSAS)
В службах SQL Server Analysis Services (SSAS) предлагаются возможности OLAP и интеллектуального анализа данных для приложений бизнес-аналитики. Вы можете установить службы SSAS на локальных серверах или разместить их на виртуальной машине в Azure. Azure Analysis Services — это полностью управляемая служба, которая предоставляет те же основные функции, что и SSAS. Службы Azure Analysis Services поддерживают подключение к различным облачным и локальным корпоративным источникам данных.
Кластеризованные индексы columnstore доступны в SQL Server 2014 и более поздних версий, а также в Базе данных SQL Azure и отлично подходят для рабочих нагрузок OLAP. Но начиная с версии SQL Server 2016 (включая Базу данных SQL Azure) вы можете воспользоваться гибридной транзакционно-аналитической обработкой (HTAP) благодаря обновляемым некластеризованным индексам columnstore. HTAP позволяет выполнять задачи обработки OLTP и OLAP на одной платформе, что избавляет от необходимости хранить несколько копий данных и использовать отдельные системы OLTP и OLAP. Дополнительные сведения см. в статье Начало работы с Columnstore для получения операционной аналитики в реальном времени.
Основные критерии выбора
Чтобы ограничить количество вариантов, сначала ответьте на следующие вопросы:
- Вы хотите использовать управляемую службу, а не управлять собственными серверами?
- Требуется ли безопасная проверка подлинности с помощью идентификатора Microsoft Entra?
- Вам нужно проводить анализ в реальном времени? Если да, оставьте только те варианты, которые поддерживают аналитику в реальном времени. Аналитика в реальном времени в этом контексте применяется к одному источнику данных, например к приложению для управления ресурсами предприятия (ERP), в котором будут выполняться операционная и аналитическая рабочие нагрузки. Если требуется интегрировать данные из нескольких источников или обеспечить максимальную производительность для анализа с помощью предварительно вычисленных данных, таких как кубы, вам может потребоваться отдельное хранилище данных.
- Вам нужно использовать предварительно вычисленные данные, например, чтобы предоставлять семантические модели, которые делают анализ более удобным для организаций? Если да, выберите вариант, который поддерживает многомерные кубы или табличные семантические модели. Благодаря статистическим выражениям пользователи могут последовательно выполнять статистическое вычисление данных. Предварительно вычисленные данные также позволяют значительно повысить производительность при работе с несколькими столбцами с множеством строк. Предварительно вычисленные данные могут быть представлены в виде многомерного куба или табличной семантической модели.
- Нужно ли интегрировать данные из нескольких источников за пределами хранилища данных OLTP? Если да, рассмотрите варианты, которые позволяют легко интегрировать несколько источников данных.
Матрица возможностей
В следующих таблицах перечислены основные различия в возможностях.
Общие возможности
Возможность Azure Analysis Services SQL Server Analysis Services SQL Server с индексами columnstore База данных SQL Azure с индексами columnstore Является управляемой службой Да No No Да Поддержка многомерных кубов No Да No No Поддержка табличных семантических моделей Да Да No No Простая интеграция нескольких источников данных Да Да Нет 1 Нет 1 Поддержка аналитики в режиме реального времени No No Да Да Необходимость обработки данных для их копирования из источников Да Да No No Интеграция с Microsoft Entra Да Нет Нет 2 Да [1] Хотя SQL Server и Базу данных SQL Azure нельзя использовать для отправки запросов и интеграции нескольких внешних источников данных, можно создать конвейер для этих задач с помощью SSIS или фабрики данных Azure. Сервер SQL Server, размещенный на виртуальной машине Azure, предоставляет дополнительные варианты, например связанные серверы и PolyBase. Дополнительные сведения см. в статье Choosing a data pipeline orchestration technology in Azure (Выбор технологии оркестрации конвейера данных в Azure).
[2] Подключение на SQL Server, работающем на виртуальной машине Azure, не поддерживается с помощью учетной записи Microsoft Entra. Вместо этого используйте учетную запись Active Directory домена.
Масштабируемость
Возможность Azure Analysis Services SQL Server Analysis Services SQL Server с индексами columnstore База данных SQL Azure с индексами columnstore Избыточные региональные серверы для высокого уровня доступности Да No Да Да Поддержка горизонтального увеличения масштаба запросов Да No Да Да Динамическая масштабируемость (увеличение масштаба) Да No Да Да Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
- Зойнер Теджада | Генеральный директор и архитектор
Следующие шаги
- Общие сведения об индексах columnstore
- Создание сервера служб Analysis Services
- Что такое Фабрика данных Azure?
- Что такое Power BI?
Связанные ресурсы
- Стиль архитектуры больших данных
- Оперативная аналитическая обработка (OLAP)
- Сортировка:
- Бонусы