Как создать круговую диаграмму в Seaborn
В библиотеке визуализации данных Python Seaborn нет функции по умолчанию для создания круговых диаграмм, но вы можете использовать следующий синтаксис в Matplotlib для создания круговой диаграммы и добавления цветовой палитры Seaborn:
import matplotlib.pyplot as plt import seaborn as sns #define data data = [value1, value2, value3, . ] labels = ['label1', 'label2', 'label3', . ] #define Seaborn color palette to use colors = sns.color_palette('pastel')[ 0:5 ] #create pie chart plt.pie(data, labels = labels, colors = colors, autopct='%.0f%%') plt.show() Полный список цветовых палитр см. в документации Seaborn.
В следующих примерах показано, как использовать этот синтаксис на практике.
Пример 1. Круговая диаграмма с цветовой палитрой Pastel Seaborn
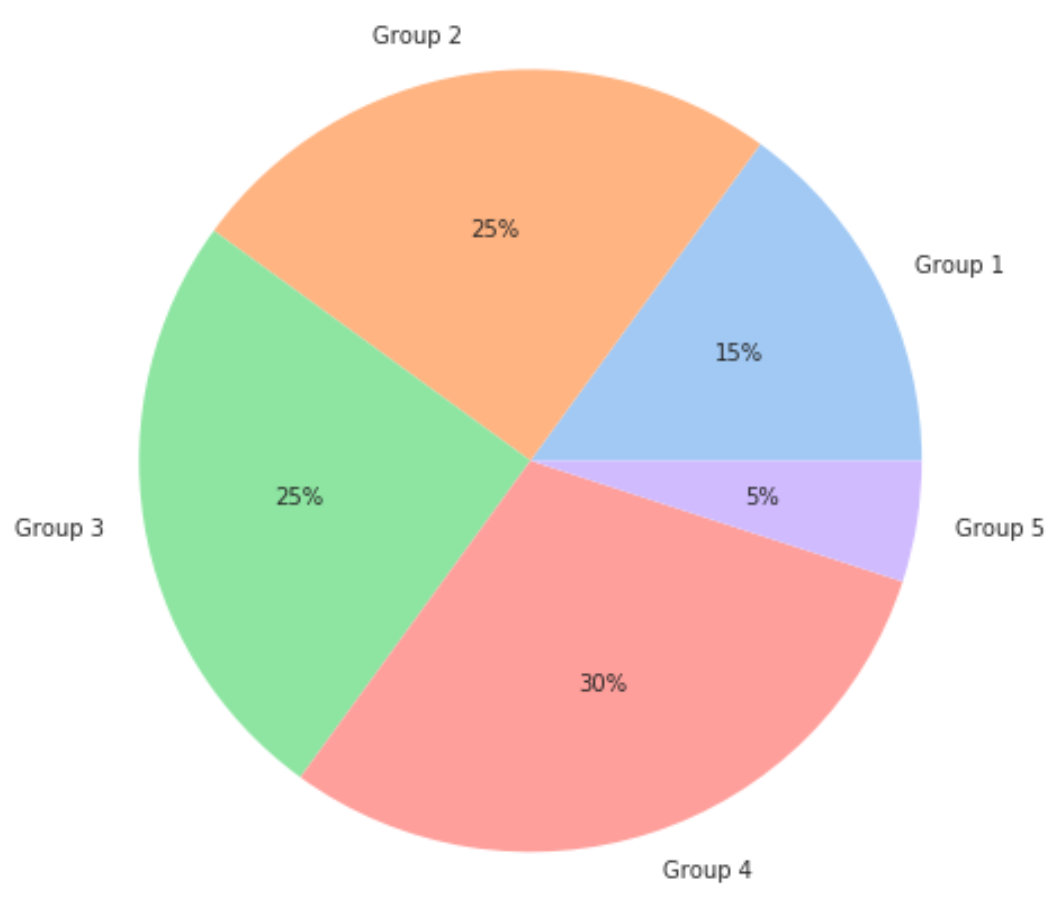
В следующем коде показано, как создать круговую диаграмму с использованием « пастельной » цветовой палитры Seaborn:
import matplotlib.pyplot as plt import seaborn as sns #define data data = [15, 25, 25, 30, 5] labels = ['Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'] #define Seaborn color palette to use colors = sns.color_palette('pastel')[ 0:5 ] #create pie chart plt.pie(data, labels = labels, colors = colors, autopct='%.0f%%') plt.show() 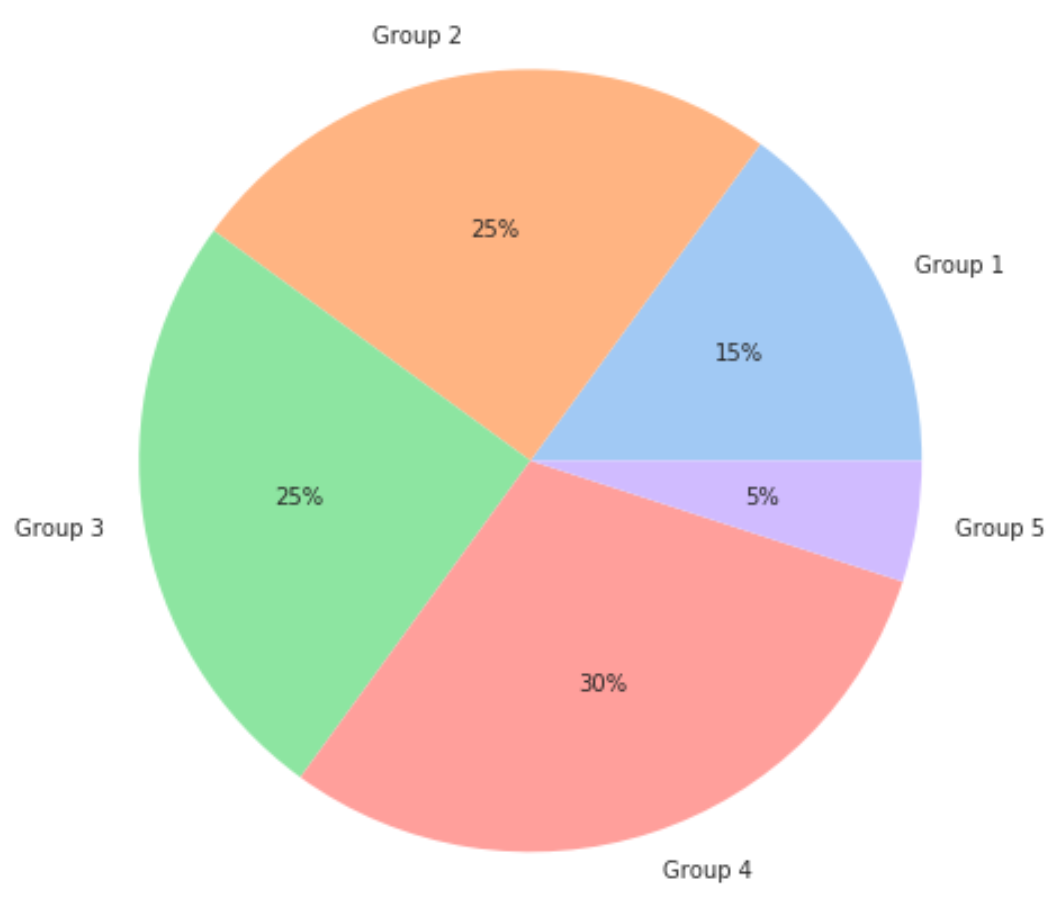
Пример 2. Круговая диаграмма с цветовой палитрой Bright Seaborn
В следующем коде показано, как создать круговую диаграмму с использованием « яркой » цветовой палитры Seaborn:
import matplotlib.pyplot as plt import seaborn as sns #define data data = [15, 25, 25, 30, 5] labels = ['Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'] #define Seaborn color palette to use colors = sns.color_palette('bright')[ 0:5 ] #create pie chart plt.pie(data, labels = labels, colors = colors, autopct='%.0f%%') plt.show() 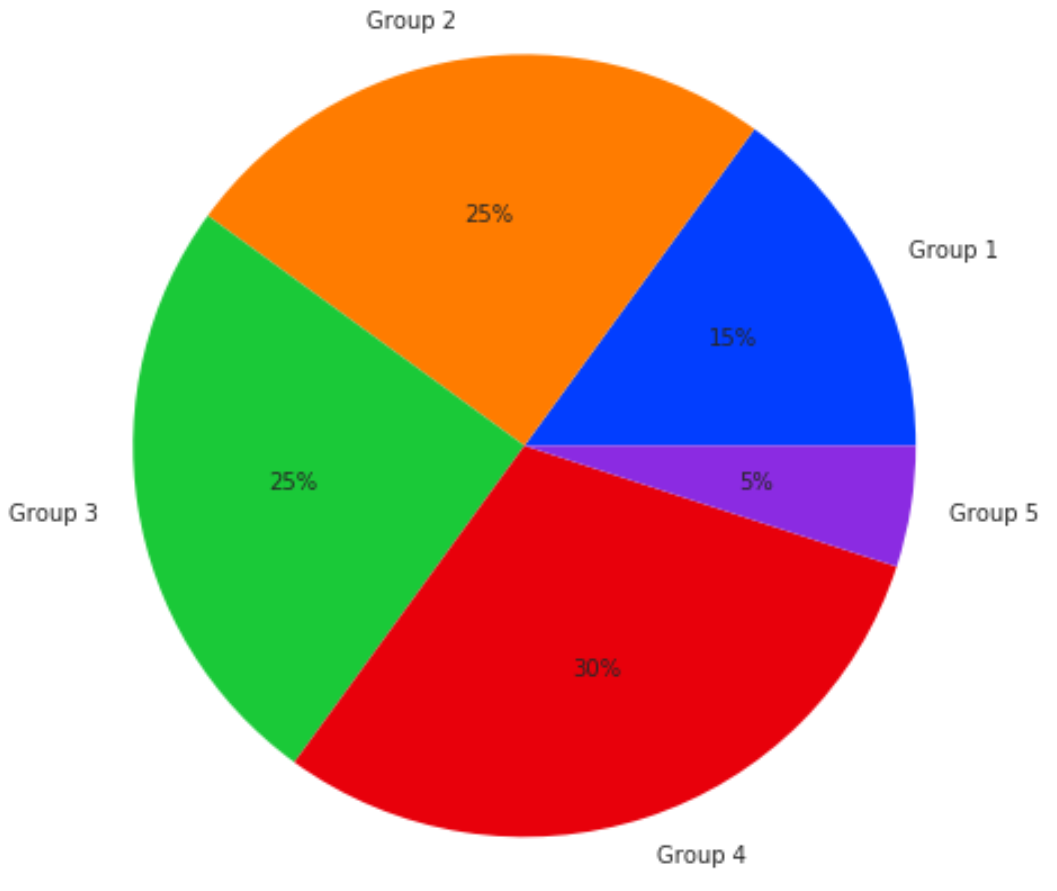
Эти два примера иллюстрируют, как создать круговую диаграмму с двумя разными цветовыми палитрами Seaborn.
Тем не менее, есть еще много стилей, которые вы могли бы использовать. Полный список цветовых палитр см. в онлайн-документации .
Как создать круговую диаграмму из Pandas DataFrame
Вы можете использовать следующий базовый синтаксис для создания круговой диаграммы из кадра данных pandas:
df.groupby(['group_column']). sum ().plot(kind='pie', y='value_column') В следующих примерах показано, как использовать этот синтаксис на практике.
Пример 1: создание базовой круговой диаграммы
Предположим, у нас есть следующие две Pandas DataFrame:
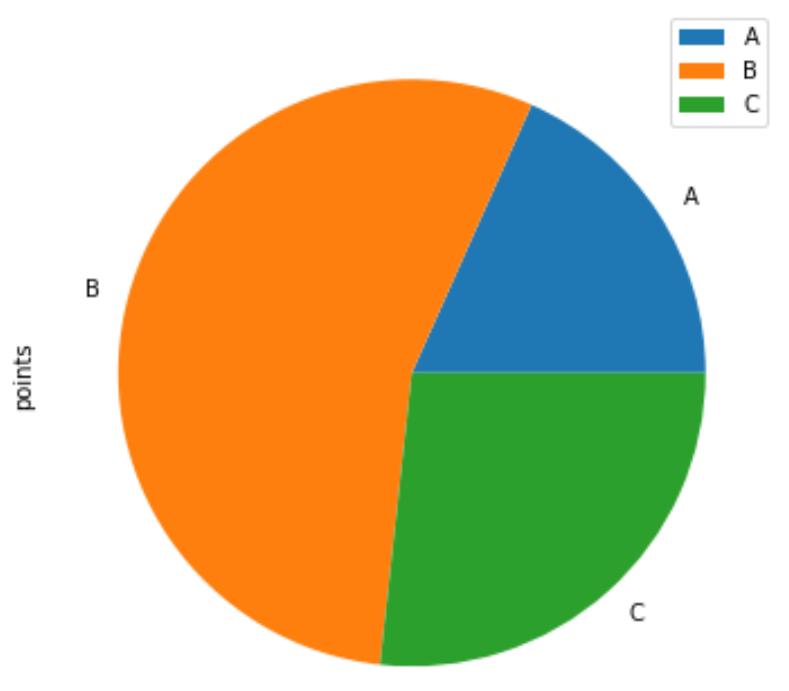
import pandas as pd #create DataFrame df = pd.DataFrame() #view DataFrame print(df) team points 0 A 25 1 A 12 2 B 25 3 B 14 4 B 19 5 B 53 6 C 25 7 C 29 Мы можем использовать следующий синтаксис, чтобы создать круговую диаграмму, которая отображает часть общего количества очков, набранных каждой командой:
df.groupby(['team']). sum ().plot(kind='pie', y='points') 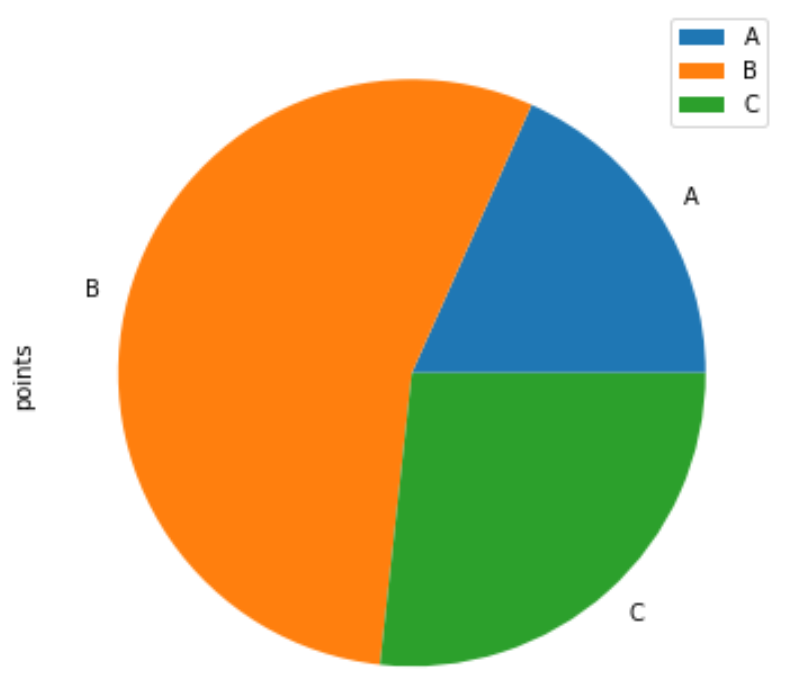
Пример 2. Создание пользовательской круговой диаграммы
Мы можем использовать следующие аргументы для настройки внешнего вида круговой диаграммы:
- autopct : Отображать проценты на круговой диаграмме.
- цвета : Укажите цвета для использования в круговой диаграмме.
- title : добавить заголовок к круговой диаграмме
Следующий код показывает, как использовать эти аргументы на практике:
df.groupby(['team']). sum ().plot(kind='pie', y='points', autopct='%1.0f%%', colors = ['red', 'pink', 'steelblue'], title='Points Scored by Team')) 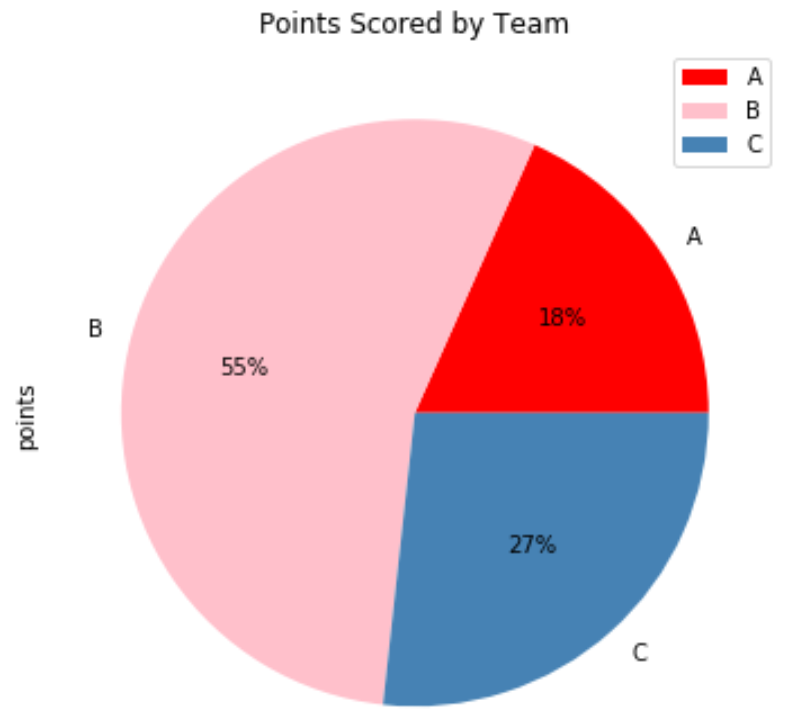
Обратите внимание, что цвета будут назначены категориям, как они отображаются в DataFrame.
Например, команда «А» появляется первой в DataFrame, поэтому она получила «красный» цвет на круговой диаграмме.
Дополнительные ресурсы
В следующих руководствах объясняется, как создавать другие распространенные графики с использованием кадра данных pandas:
Как объединить части круговой диаграммы (matplotlib.pie)

 Есть набор данных (70 значений) типа Float надо создать круговую диаграмму где значения большие 2,6 будут отображены отдельными частями(долями) а те значения которые меньше 2,6 надо объединить в одну большую часть одного цвета и без деления. Ссылка на DF https://github.com/Raduga-maker/Pandas
Есть набор данных (70 значений) типа Float надо создать круговую диаграмму где значения большие 2,6 будут отображены отдельными частями(долями) а те значения которые меньше 2,6 надо объединить в одну большую часть одного цвета и без деления. Ссылка на DF https://github.com/Raduga-maker/Pandas
Отслеживать
задан 11 окт 2023 в 8:36
5 3 3 бронзовых знака
если честно, вопрос вообще не понятен что надо сделать, так же приложите код со своими попытками реализации. ru.stackoverflow.com/help/how-to-ask
11 окт 2023 в 8:57
Постарался исправить чтобы стало понятнее, заранее простите второй раз задаю здесь вопрос
11 окт 2023 в 9:09
Может стоит обработать датафрейм определённым образом?
11 окт 2023 в 9:11
вы данные (таблицу) в текстовом виде приведите. зачем нам их фотография?
11 окт 2023 в 9:13
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Перед тем как выводить данные, вы можете прогнать их через пороговую лямбду, так как вашего исходного датафрейма я не вижу, поэтому я реализую собственный образовательный пример.
import matplotlib.pyplot as plt import pandas as pd # Ваш исходный список x x = [10, 10, 10, 10, 10, 10, 10, 100, 200, 500] # Создаем DataFrame из списка x data = pd.DataFrame() # Объединяем значения меньше 100 в один кусок пирога threshold = 100 data['values'] = data['values'].apply(lambda val: val if val >= threshold else f'меньше чем ') # Группируем данные по значениям и суммируем их grouped_data = data.groupby('values').size() # Создаем круговую диаграмму на основе сгруппированных данных plt.figure(figsize=(6, 6), dpi=72) plt.pie(grouped_data, labels=grouped_data.index, autopct='%1.1f%%') # Отображаем диаграмму (опционально) plt.show() Мои values в вашем случае будут отражать ваши проценты, а где threshold укажите ваше пороговое значение
Выглядеть будет это следующим образом:
Как настроить визуализацию в Python: Matplotlib и Plotly
Data Scientist работает с огромным объемом данных, который необходимо проанализировать и обработать. Одним из подходов к анализу данных является их визуализация с использованием графического представления.
Сегодня существует множество библиотек для визуализации данных в Python. Одной из самых популярных является Matplotlib, однако этот инструмент создавался задолго до бурного развития Data Science, и в большей мере ориентирован на отображение массивов NumPy и параметрических функций SciPy. В то же время в Data Science распространен обобщенный тип объектов – датасеты, крупные таблицы с разнородными данными. Для визуализации подобных данных разрабатываются новые библиотеки визуализации, например, Plotly.
Далее предложим вашему вниманию сравнительный анализ библиотек Matplotlib и Plotly.
Сравнение проведем на данных, полученных при решении задачи оптимизации электронно-лучевого процесса. Подробней задача описана в отчете о научно-исследовательской работе «математическое и алгоритмическое обеспечение процесса электронно-лучевой сварки тонкостенных конструкций аэрокосмического назначения». Результаты работы модели сильно зависят от начальных параметров, которые варьируются в широком диапазоне, поэтому для экспресс-анализа полученных данных целесообразно использовать графическое представление переменных и целевой функции.
Программная реализация описанной задачи разбита на два модуля:
- module_1 содержит функции T_1, T_2, ψ (описание функций приведено ниже);
- module_2 выполняет расчет распределения температур (T_1 + T_2) по заданным параметрам с последующим графическим выводом в отдельном окне с возможностью сохранения графика в файл.
Для визуализации математического моделирования тепловых процессов необходимо установить библиотеки Plotly и Matplotlib. Plotly не входит ни в Anaconda, ни в стандартный пакет, поэтому устанавливаем через командную строку:
pip install plotly
Устанавливаем Matplotlib в Jupyter notebook с помощью кода:
!pip install matplotlib
Также для работы понадобятся библиотеки NumPy, SciPy, Pandas, Math и Csv для работы с сырыми данными:
import plotly import plotly.graph_objs as go import plotly.express as px from plotly.subplots import make_subplots import numpy as np import pandas as pd import os,sys,inspect import random import math import scipy.integrate import matplotlib.pyplot as plt import math import scipy.integrate import csv import svs
Ниже представлена функция для импортирования настроек из конфигурационного csv файла, принимает 1 аргумент — число — номер модуля, сам csv файл размещен в репозитории.
def import_csv_cofigs(module_num): try: # Начальная температура изделия T_n = 0 # Время t_ = 0 # Мощность q_ = 0 # Теплоемкость материала cp_ = 0 # Коэффициент температуропроводности alpha_ = 0 # Скорость сварки v_ = 0 # Коэффициент теплопроводности lambda_ = 0 # Толщина delta_ = 0 mainDialect = csv.Dialect mainDialect.doublequote = True mainDialect.quoting = csv.QUOTE_ALL mainDialect.delimiter = ‘;’ mainDialect.lineterminator = ‘\n’ mainDialect.quotechar = ‘»‘ module_dir = ‘/’.join(sys.path[0].split(‘\\’)) with open(f’
Ниже представлено описание и код этих двух модулей, начнем с module_1:
import sys # Формула для состояния температурного поля при воздействии быстро движущегося точечного источника def T_1(T_n, V_, t_, q_, cp_, a_, v_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки R_ — длина радиус-вектора «»» R_ = math.sqrt(V_.x_**2 + V_.y_**2 + V_.z_**2) # Функция — подинтегральное выражение def f_(t_1): tau_ = t_1 return math.exp((-v_**2 * tau_)/(4*a_) — (R_**2)/(4*a_*tau_))*(1/(tau_**(3/2))) i_ = scipy.integrate.quad(f_, 0, t_, limit=1) return T_n + ((2*q_)/(cp_*math.sqrt((4*math.pi*a_)**3))) * math.exp((-v_*V_.x_)/(2*a_)) * i_[0] # Формула для состояния температурного поля при воздействии быстро движущегося линейного источника def T_2(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки lambda_ — коэффициент теплопроводности delta_ — толщина «»» # Функция — подинтегральное выражение def f_(t_1): tau_ = t_1 return math.exp( (-v_**2 * tau_)/(4*a_) — (2*lambda_*tau_)/(cp_*delta_) — (V_.x_**2+V_.y_**2)/(4*a_*tau_) ) * (1/tau_) i_ = scipy.integrate.quad(f_, 0, t_, limit=1) return T_n + ((q_)/(4*math.pi*lambda_*delta_)) * math.exp((-v_*V_.x_)/(2*a_)) * i_[0] # Функция ψ(x, y, z, v, t, q) def PSI_xyzvtq(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_): «»» T_n — начальная температура изделия x_ — координата x t_ — время q_ — мощность cp_ — теплоемкость материала a_ — коэффициент температуропроводности v_ — скорость сварки lambda_ — коэффициент теплопроводности delta_ — толщина T_t — температура в стадии теплонасыщения «»» T_1_result = T_1(T_n, V_, t_, q_, cp_, a_, v_) T_2_result = T_2(T_n, V_, t_, q_, cp_, a_, v_, lambda_, delta_) T_t = (T_1_result + T_2_result) * 0.9 return (T_t — T_n)/(T_1_result+T_2_result-T_n)
Дальше рассмотрим module_2:
from module_1.module_1 import T_1, T_2, PSI_xyzvtq, V_xyz, import_csv_cofigs work_configs = import_csv_cofigs(2) # Начальная температура изделия T_n = work_configs[0] # Время t_ = work_configs[1] # Мощность q_ = work_configs[2] # Теплоемкость материала cp_ = work_configs[3] # Коэффициент температуропроводности alpha_ = work_configs[4] # Скорость сварки v_ = work_configs[5] # Коэффициент теплопроводности lambda_ = work_configs[6] # Толщина delta_ = work_configs[7] def main(): show_matrix = [[], [], []] for i in range(-50,100,5): for j in range(-50,100,5): V_ = V_xyz(i/100,j/100,0) tmp_ = T_2(T_n, V_, t_, q_, cp_, alpha_, v_, lambda_, delta_) + T_1(T_n, V_, t_, q_, cp_, alpha_, v_) show_matrix[0].append(V_.x_) show_matrix[1].append(V_.y_) show_matrix[2].append(tmp_) if __name__ == «__main__»: main()
Данный код и соответствующий ему конфигурационные файлы размещены в репозитории (https://github.com/Saverona/codes.git).
Выполним визуализацию тепловых процессов. Получаем распределение температуры при сварке титанового сплава с учетом геометрических размеров изделия, заданных технологических параметров и заданном режиме ввода электронного луча.
Для визуализации данных с помощью Plotly используем код:
fig = go.Figure(data=[go.Mesh3d( x=show_matrix[0], y=(show_matrix[1]), z=(show_matrix[2]), opacity=0.5, color=’rgba(244,22,100,0.6)’ )]) fig.show()
Для визуализации данных с помощью Matplotlib используем код:
fig = plt.figure() ax = fig.add_subplot(111, projection=’3d’) ax.plot_trisurf(np.array(show_matrix[0]), np.array(show_matrix[1]), np.array(show_matrix[2]), cmap=’plasma’, linewidth=0, antialiased=False) plt.show()
В результате получаем графики распределения температуры на поверхности изделия, построенные с помощью Matplotlib (3D график изображен слева) и Plotly (графики изображены справа). В Plotly можем наблюдать распределение с разных осей, а также имеется возможность посмотреть значение в конкретной точке, в Matplotlib таких возможностей нет.
Simple plot – это график, который показывает динамику по одному или нескольким показателям. Его удобно применять, когда нужно сравнить, как меняются с течением времени разные наборы данных. Данные на таком графике отображаются в виде точек, которые соединены линиями. Выполним визуализацию Simple plot в Matplotlib и Plotply. График показывает равномерность нагрева изделия в процессе электронно-лучевой сварки.
fig, ax = plt.subplots() ax.plot(show_matrix[1], show_matrix[2]) ax.set(xlabel=’x’, ylabel=’y’, title=’Temp’) ax.grid() plt.show()
fig = px.line(x=show_matrix[1],y=show_matrix[2]) fig.show
При работе с Plotly есть возможность сохранять результат сразу в png (к сожалению, у анимационных графиков нет возможности сохранения в gif, что очень неудобно):
Scatter plots – математическая диаграмма, изображающая значения двух переменных в виде точек на декартовой плоскости. На Scatter plots каждому наблюдению соответствует точка, координаты которой равны значениям двух какого-то параметра этого наблюдения. Эти диаграммы используются для визуализации наличия или отсутствия корреляции между двумя переменными. Выполним визуализацию Scatter plots в Matplotlib и Plotply.
Код в Matplotlib:
fig, ax = plt.subplots() sizes = np.random.uniform(15, 80, len(show_matrix[1])) colors = np.random.uniform(15, 80, len(show_matrix[2])) ax.scatter(x=show_matrix[1], y=show_matrix[2], s=sizes, c=colors) plt.show()
fig = px.scatter(x=show_matrix[1],y=show_matrix[2]) fig.show()
В Plotly, есть возможность выделения конкретной области с помощью Lasso и Box select. В Matplotlib график изображен более красочно, по сравнению с Plotly:
Pie chart – это секторная диаграмма, которая предназначена для визуализации структуры статических совокупностей. Относительная величина каждого значения изображается в виде сектора круга, площадь которого соответствует вкладу этого значения в сумме значений. Этот вид визуализации очень удобно использовать, когда нужно показать долю каждой величины в общем объеме. Сектора могут отображаться как в общем круге, так и отдельно, расположенными на небольшом удалении друг от друга. Pie chart сохраняет наглядность только в том случае, если количество частей совокупности диаграммы небольшое. Если частей диаграммы много, то применение такой визуализации данных неэффективно по причине несущественного различия сравниваемых структур. Недостаток Pie chart – малая емкость, невозможно отразить более широкий объем полезной информации. Выполним визуализацию Pie chart в Matplotlib и Plotply.
Код в Matplotlib:
fig = plt.pie(np.array(show_matrix[2]), explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1, startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=(0, 0), frame=False, rotatelabels=False, normalize=True, data=None)
fig = px.pie(show_matrix[2]) fig.update_layout(uniformtext_minsize=12, uniformtext_mode=’hide’) fig.show()
Сравним результаты. в Plotly есть возможность выбрать конкретное количество значений, которые нам можно или нужно посмотреть, а в Matplotlib невозможно проанализировать данный график.
Styling Markers – это особый способ обработки маркеров, он используется как функцией разброса, так и для построения точечных диаграмм. Выполним визуализацию Styling Markers в Matplotlib и Plotply.
Код в Matplotlib:
fig = plt.figure() plt.plot(np.array(show_matrix[2]), marker = ‘o’, ms = 20, mec = ‘hotpink’, mfc = ‘hotpink’)
fig = px.scatter(x = show_matrix[1], y = show_matrix[2]) fig.update_traces(marker=dict(size=7, line=dict(width=6, color=’hotpink’)), selector=dict(mode=’markers’)) fig.show()
У Plotly есть функционал выделения области разными вариантами, удобен просмотр расположения маркера, а также есть возможность посмотреть конкретное значение маркера. В свою очередь у Matlotlib очень приятная визуализация.
А еще в Plotly можем более точно рассмотреть значения распределения температурного поля, как видим в самой верхней точке происходит нагрев при температуре 1914,4. Так же можем выбирать, какой график нам отображать первым или же можем совсем наложить их друг на друга для более точного анализа, ниже представлен код и визуализация:
fig = go.Figure() fig.add_trace(go.Scatter(x=show_matrix[1], y=show_matrix[2], mode=’lines+markers’, name=’Нагрев’, marker=dict(color=show_matrix[2], colorbar=dict(title=»Температура»), colorscale=’Inferno’, size=50))) fig.add_trace(go.Scatter(visible=’legendonly’, x=show_matrix[1], y=show_matrix[2], name=’T1+T2′)) fig.update_layout(legend_orientation=»h», legend=dict(x=.5, xanchor=»center»), margin=dict(l=0, r=0, t=0, b=0)) fig.update_traces(hoverinfo=»all», hovertemplate=»Температура») fig.show()
Так же в Plotly есть возможность реализовать анимационный график с express. Функции express принимают на вход датафреймы, вам лишь нужно указать колонки, по которым производится агрегация данных. И можно сразу строить и тепловые карты, и анимации очень небольшим количеством кода, как в этом примере:
import plotly.express as px df = px.data.gapminder() fig = px.scatter(df, x=»gdpPercap», y=»lifeExp», animation_frame=»year», animation_group=»country», size=»pop», color=»continent», hover_name=»country», log_x=True, size_max=55, range_x=[100,100000], range_y=[25,90]) fig.show()
Также хочется отметить, что у Plotly очень удобная и понятная документация, можно легко найти какой вариант визуализации нужен для работы, но к сожалению, нет описания параметров, которые используются для построения. В документации Matplotlib имеется описание каждого параметра, что очень упрощает реализацию.
По сравнению с Matplotlib, Plotly предлагает обширный список вариантов построения графиков, начиная с обычных и заканчивая анимационными или графическими картами.
На наш взгляд, Plotly является более информативной и удобной библиотекой для визуализации данных. Библиотека имеет однострочный код для красочной визуализации датасетов, интерактивные элементы для выделения и исследования данных, возможность существенной детализации отображаемой информации.
Желаем приятной работы при визуализации данных!