С помощью какого метода можно получить файл из Интернета? [закрыт]
Закрыт. Этот вопрос необходимо уточнить или дополнить подробностями. Ответы на него в данный момент не принимаются.
Хотите улучшить этот вопрос? Добавьте больше подробностей и уточните проблему, отредактировав это сообщение.
Закрыт 1 год назад .
С помощью какого метода можно получить файл из Интернета?
Отслеживать
задан 16 янв 2023 в 12:50
7 2 2 бронзовых знака
16 янв 2023 в 12:54
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
import requests # импорт библиотеки req = requests.get('https://ru.stackoverflow.com/questions') # делаем запрос используя метод GET with open('ru-stackoverflow-questions.html', 'wb') as file: # открытие файла file.write(req.content) # запись в файл print('Файл успешно записан') Отслеживать
ответ дан 16 янв 2023 в 13:12
762 1 1 золотой знак 3 3 серебряных знака 12 12 бронзовых знаков
- python
- request
-
Важное на Мете
Похожие
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.30.4069
Читаем текстовый файл с сайта
Чрезвычайно актуальной задачей является получение файла не с текущего компьютера, а с внешнего сайта, например. И это возможно при условии использования модуля (библиотеки)
urllib.request
которую следует подключить, используя import. Кроме того, учитывая, что нужный нам файл может быть удален, следует обязательно предусматривать исключительную ситуацию и ее обработку. Следующий (онлайн) пример показывает, как можно прочитать внешний файл и вывести его содержимое на печать.
import urllib.request def GetURL(url): s = ‘error’ try: f = urllib.request.urlopen(url) s = f.read().decode(‘utf-8’) except urllib.error.HTTPError: s = «connect error» except urllib.error.URLError: s = ‘url error’ return s text=GetURL(‘https://qaweb.dev/files/doc/qaweb.txt’) print (text)
Just press ‘Run’.
Обратите внимание, что в приведенном выше коде было выполнено декодирование с помощью .decode(‘utf-8’). Вы можете, например, прочесть здесь ваш личный тестовый файл, расположенный на github. Записывать таким образом во внешний файл мы не сможем.
Функция open. Чтение и запись текстовых файлов в Python
Большие объемы данных хранят не в списках или словарях, а в файлах и базах данных. В этом уроке изучим особенности работы с текстовыми файлами в Python. Такие файлы рассматриваются как содержащие символы и строки.
Бывают еще байтовые (бинарные) файлы, которые рассматриваются как потоки байтов. Побайтово считываются, например, файлы изображений. Работа с бинарными файлами несколько сложнее. Нередко их обрабатывают с помощью специальных модулей Python (pickle, struct).
Функция open
Связь с файлом на жестком диске выполняется с помощью встроенной в Python функции open() . Обычно ей передают один или два аргумента. Первый – имя файла или имя с адресом, если файл находится не в том каталоге, где находится сама программа. Второй аргумент – режим, в котором открывается файл.
Обычно используются режимы чтения ( ‘r’ ) и записи ( ‘w’ ). Если файл открыт в режиме чтения, то запись в него невозможна. Можно только считывать данные. Если файл открыт в режиме записи, то в него можно только записывать данные, считывать нельзя.
Если файл открывается в режиме ‘w’ , то все данные, которые в нем были до этого, стираются. Файл становится пустым. Если не надо удалять существующие в файле данные, тогда следует использовать вместо режима записи, режим дозаписи ( ‘a’ ).
Если файл отсутствует, то открытие его в режиме ‘w’ создаст новый файл. Бывают ситуации, когда надо гарантировано создать новый файл, избежав случайной перезаписи данных существующего. В этом случае вместо режима ‘w’ используется режим ‘x’ . В нем всегда создается новый файл для записи. Если указано имя существующего файла, то будет выброшено исключение. Потери данных в уже имеющемся файле не произойдет.
Если при вызове open() второй аргумент не указан, то файл открывается в режиме чтения как текстовый файл. Чтобы открыть файл как байтовый, дополнительно к букве режима чтения/записи добавляется символ ‘b’ . Буква ‘t’ обозначает текстовый файл. Поскольку это тип файла по умолчанию, то обычно ее не указывают.
Нельзя указывать только тип файла, то есть open(«имя_файла», ‘b’) есть ошибка, даже если файл открывается на чтение. Правильно – open(«имя_файла», ‘rb’) . Только текстовые файлы мы можем открыть командой open(«имя_файла») , потому что и ‘r’ и ‘t’ подразумеваются по-умолчанию.
Функция open() возвращает объект файлового типа. Его надо либо сразу связать с переменной, чтобы не потерять, либо сразу прочитать.
Чтение файла
С помощью файлового метода read() можно прочитать файл целиком или только определенное количество байт. Пусть у нас имеется файл data.txt с таким содержимым:
one - 1 - I two - 2 - II three - 3 - III four - 4 - IV five - 5 - V
Откроем его и почитаем:
>>> f1 = open(‘data.txt’) >>> f1.read(10) ‘one — 1 — ‘ >>> f1.read() ‘I\ntwo — 2 — II\nthree — 3 — III\nfour — 4 — IV\nfive — 5 — V\n’ >>> f1.read() » >>> type(f1.read())
Сначала считываются первые десять символов. Последующий вызов read() считывает весь оставшийся текст. После этого объект файлового типа f1 становится пустым.
Заметим, что метод read() возвращает строку, и что конец строки считывается как ‘\n’ .
Для того, чтобы читать файл построчно существует метод readline() :
>>> f1 = open('data.txt') >>> f1.readline() 'one - 1 - I\n' >>> f1.readline() 'two - 2 - II\n' >>> f1.readline() 'three - 3 — III\n'
Метод readlines() считывает сразу все строки и создает список:
>>> f1 = open('data.txt') >>> f1.readlines() ['one - 1 - I\n', 'two - 2 - II\n', 'three - 3 - III\n', 'four - 4 - IV\n', 'five - 5 - V\n']
Объект файлового типа относится к итераторам. Из таких объектов происходит последовательное извлечение элементов. Элементами в данном случае являются строки-линии файла. Поэтому считывать данные из файла можно сразу в цикле без использования методов чтения:
>>> for i in open('data.txt'): . print(i) . one - 1 - I two - 2 - II three - 3 - III four - 4 - IV five - 5 - V >>>
Здесь выводятся лишние пустые строки, потому что функция print() преобразует ‘\n’ в переход на новую строку. К этому добавляет свой переход на новую строку. Создадим список строк файла без ‘\n’ :
>>> nums = [] >>> for i in open('data.txt'): . nums.append(i[:-1]) . >>> nums ['one - 1 - I', 'two - 2 - II', 'three - 3 - III', 'four - 4 - IV', 'five - 5 - V']
Переменной i присваивается очередная строка файла. Мы берем ее срез от начала до последнего символа, не включая его. Следует иметь в виду, что ‘\n’ это один символ, а не два.
Запись в файл
Запись в файл выполняется с помощью методов write() и writelines() . Во второй можно передать структуру данных:
>>> l = ['tree', 'four'] >>> f2 = open('newdata.txt', 'w') >>> f2.write('one') 3 >>> f2.write(' two') 4 >>> f2.writelines(l)
Метод write() возвращает количество записанных символов.
Закрытие файла
После того как работа с файлом закончена, важно не забывать его закрыть, чтобы освободить место в памяти. Делается это с помощью файлового метода close() . Свойство файлового объекта closed позволяет проверить закрыт ли файл.
>>> f1.close() >>> f1.closed True >>> f2.closed False
Если файл открывается в заголовке цикла ( for i in open(‘fname’) ), то видимо интерпретатор его закрывает при завершении работы цикла или через какое-то время.
Практическая работа
- Создайте файл data.txt по образцу урока. Напишите программу, которая открывает этот файл на чтение, построчно считывает из него данные и записывает строки в другой файл ( dataRu.txt ), заменяя английские числительные русскими, которые содержатся в списке ( [«один», «два», «три», «четыре», «пять»] ), определенном до открытия файлов.
- Создайте файл nums.txt , содержащий несколько чисел, записанных через пробел. Напишите программу, которая подсчитывает и выводит на экран общую сумму чисел, хранящихся в этом файле.
Примеры решения и дополнительные уроки в pdf-версии курса
X Скрыть Наверх
Python. Введение в программирование
Функция open. Чтение данных из файла
На этом занятии мы с вами научимся читать данные из файлов. Думаю, вы все прекрасно понимаете, что такое файлы и что они хранятся, как правило, на внешних носителях. (Часто – это жесткий диск устройства или флеш-память или SSD-диск. Бывают и другие носители). Главная особенность файлов – сохранение информации после отключения устройства от питания.
Начнем со знакомства с функцией:
open(file [, mode=’r’, encoding=None, …])
которая открывает указанный файл на чтение или запись данных (по умолчанию – на чтение). Основные ее параметры, следующие:
- file – путь к файлу (вместе с его именем);
- mode – режим доступа к файлу (чтение/запись);
- encoding – кодировка файла.
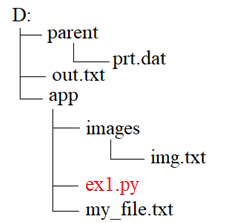
Чтобы воспользоваться этой функцией, нужно правильно записать первый аргумент – путь к файлу. Давайте, посмотрим различные варианты его определения. Представим, что наш файл ex1.py находится в рабочем каталоге app: Тогда, чтобы обратиться к файлу my_file.txt путь можно записать просто, как: «my_file.txt» или «d:\\app\\my_file.txt» или так: «d:/app/my_file.txt» Последние два варианта представляют собой абсолютный путь к файлу, то есть, полный путь, начиная с указания диска. Причем, обычно используют обратный слеш в качестве разделителя: так короче писать и такой путь будет корректно восприниматься как под ОС Windows, так и Linux. Первый же вариант – это относительный путь (относительно каталога с исполняемым файлом). Теперь, предположим, что мы хотим обратиться к файлу img.txt. Это можно сделать так: «images/img.txt» или так: «d:/app/images/img.txt» Для доступа к out.txt пути будут записаны так: «../out.txt»
«d:/out.txt» Обратите внимание, здесь две точки означают переход к родительскому каталогу, то есть, выход из каталога app на один уровень вверх. И, наконец, для доступа к файлу prt.dat пути запишутся так: «../parent/prt.dat»
«d:/ parent/prt.dat» Вот принцип, по которому прописываются пути к файлам. В нашем случае мы имеем текстовый файл «my_file.txt», который находится в том же каталоге, что и программа ex1.py, поэтому путь можно записать, просто указав имя файла:
file = open("my_file.txt")
В результате переменная file будет ссылаться на файловый объект, через который и происходит работа с файлами. Если указать неверный путь, например, так:
file = open("my_file2.txt")
то возникнет ошибка FileNotFoundError. Поэтому пути нужно прописывать аккуратно. Позже мы увидим, как можно избежать такой ошибки, чтобы программа не прерывалась при неверно указанном файле. Итак, функция open() по умолчанию открывает файл на чтение. Это значит, что в этом режиме мы можем только считывать информацию из файла, но не записывать. Как прочитать данные из файла? Для этого существует несколько методов у файлового объекта. Например, если выполнить метод:
print( file.read() )
то будет прочитан весь файл целиком и результат представлен в виде строки. Но сейчас мы видим с вами в консоли отображаются какие-то кракозябры. Почему? Все дело в несовпадении кодировок. В моем случае метод read() читает данные в кодировке windows-1251, а кодировка файла с текстом – UTF-8. Чтобы это поправить, в функции open() нужно явно указать кодировку файла через именованный аргумент encoding:
file = open("myfile.txt", encoding="utf-8" )
Теперь все работает корректно. Но, что если нам нужно прочитать из файла всего несколько символов? Для этого достаточно вызвать метод read() и первым аргументом указать максимальное количество читаемых символов, например:
print( file.read(4) )

Из файла будут считаны первые четыре символа. Правда, в консоли мы видим только три символа. Дело в том, что при кодировке UTF-8 в файл автоматически добавляется первый (невидимый) символ с шестнадцатиричным кодом: #FEFF Если мы снова вызовем метод:
print( file.read(4) )
то будут прочитаны следующие четыре символа. Вот эта стрелка (на рисунке) называется файловой позицией (file position), которая указывает, с какого места производить последующее считывание информации. Благодаря ей мы можем последовательно читать данные, просто вызывая метод read(). Когда доходим до конца файла, то здесь находится специальный символ EOF, означающий конец файла. При необходимости, мы можем управлять положением файловой позиции. Для этого существует специальный метод: file.seek(offset[, from_what]) Например, вот такая запись:
file.seek(0)
будет означать, что мы устанавливаем позицию в начало и тогда такие строчки:
print( file.read(4) ) file.seek(0) print( file.read(4) )
будут считывать одни и те же первые символы. Если же мы хотим узнать текущую позицию в файле, то следует вызвать метод tell:
pos = file.tell() print( pos )
Следующий полезный метод readline() позволяет построчно считывать информацию из текстового файла:
s = file.readline() print( s )
Здесь концом строки считается символ переноса ‘\n’, либо конец файла. Причем, этот спецсимвол переноса будет также присутствовать в строке. Мы в этом можем убедиться, вызвав дважды функцию:
print( file.readline() ) print( file.readline() )
Здесь в консоли строчки будут разделены пустой строкой. Это как раз из-за того, что один перенос идет из прочитанной строки, а второй добавляется самой функцией print(). Поэтому, если их записать вот так:
print( file.readline(), end="" ) print( file.readline(), end="" )
то вывод будет построчным с одним переносом. Если нам нужно последовательно прочитать все строчки из файла, то для этого обычно используют цикл for следующим образом:
for line in file: print( line, end="" )
Этот пример показывает, что объект файл является итерируемым и на каждой итерации возвращает очередную строку. Или же, все строчки можно прочитать методом:
s = file.readlines()
и тогда переменная s будет ссылаться на список с этими строками:
print( s )
Однако этот метод следует использовать с осторожностью, т.к. для больших файлов может возникнуть ошибка нехватки памяти для хранения полученного списка. По сути это все методы для считывания информации из файла. Осталось только добавить, что как только мы завершаем работу с файлом, его следует закрыть. Для этого используется метод close:
file.close()