SQL-Ex blog

Освоение Oracle PL/SQL: продвинутые концепции и методы
Добавил Sergey Moiseenko on Суббота, 6 января. 2024
Oracle PL/SQL, универсальный инструмент для управления базами данных, который совершенно сливается с SQL. В нашей предыдущей статье мы рассматривали его основы и промежуточные аспекты, закладывающие прочную основу для понимания этого сложного языка.
Теперь мы готовы погрузиться в продвинутый Oracle PL/SQL. В этой статье рассматривается развитое использование курсоров, сложная обработка исключений, естественная компиляция, динамический SQL и поставляемые Oracle пакеты. Мы также исследуем методы настройки производительности, взаимодействие с SQL*PLUS и триггеры уровня базы данных.
С помощью практических примеров мы стремимся раскрыть расширенные возможности Oracle PL/SQL как для опытных разработчиков, так и развивающихся новичков. Давайте вместе раскроем потенциал продвинутых возможностей PL/SQL.
Использование расширенных курсоров
Введение в расширенные курсоры
В Oracle PL/SQL курсор — это объект базы данных, который позволяет извлекать множество строк данных и манипулировать ими, как и в операции, основанной на множествах. Помимо простых явных курсоров, мы имеем понятие расширенных курсоров типа параметризованных курсоров, REF курсоров и переменных курсоров, которые привносят больше гибкости и динамизма в ваши операции.
Параметризованные курсоры
Параметризованные курсоры, известные также как курсоры с параметрами, позволяют передавать параметры в курсоры, чтобы сделать их более гибкими. Вы можете использовать эти параметры в предложении WHERE для фильтрации результатов курсора.
Вот простой пример параметризованного курсора:
DECLARE
CURSOR c_emp (p_deptno NUMBER)
IS
SELECT ename, job FROM emp WHERE deptno = p_deptno;
v_ename emp.ename%TYPE;
v_job emp.job%TYPE;
BEGIN
OPEN c_emp(20);
LOOP
FETCH c_emp INTO v_ename, v_job;
EXIT WHEN c_emp%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_ename || ' - ' || v_job);
END LOOP;
CLOSE c_emp;
END;
/
В этом примере курсор c_emp принимает параметр p_deptno. Когда мы открываем курсор, то передаем значение этого параметра для получения сотрудников из конкретного отделения с номером 20.
Курсоры REF
REF курсоры или переменные типа курсора являются более гибкими, чем статичные курсоры. В отличие от статичных курсоров, которые фиксируются во время компиляции, REF курсоры могут открываться для любого запроса во время выполнения, что делает их весьма гибкими для программ, которым необходимо компилировать запросы динамически.
Вот простой пример REF курсора:
DECLARE
TYPE emp_ref IS REF CURSOR;
c_emp emp_ref;
v_ename emp.ename%TYPE;
v_job emp.job%TYPE;
BEGIN
OPEN c_emp FOR SELECT ename, job FROM emp WHERE deptno = 20;
LOOP
FETCH c_emp INTO v_ename, v_job;
EXIT WHEN c_emp%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_ename || ' - ' || v_job);
END LOOP;
CLOSE c_emp;
END;
/
В этом примере мы определяем тип курсора REF emp_ref и объявляем переменную курсора c_emp этого типа. Затем мы открываем переменную курсора для запроса, который извлекает сотрудников из отдела номер 20.
Владение этими продвинутыми концепциями курсоров может значительно улучшить ваши возможности по обработке и манипуляции данными в Oracle PL/SQL.
Продвинутая обработка исключений
Обработка исключений является ключевой частью любой программы PL/SQL. Она позволяет разработчикам предвидеть и устранять ошибки или исключения, которые могут возникнуть при выполнении программы. Хотя вы уже видели базовую обработку ошибок, продвинутые методы обработки исключений обеспечивают больший контроль и гибкость в неожиданных ситуациях.
Исключения, определяемые пользователем
Помимо предопределенных исключений в Oracle, PL/SQL позволяет разработчикам определять и вызывать свои собственные исключения. Это особенно полезно, когда вы хотите проверить конкретное условие и вызываете ошибку, если это условие выполняется.
Вот пример определяемых пользователем исключений:
DECLARE
emp_count INTEGER;
too_many_employees EXCEPTION;
BEGIN
SELECT COUNT(*) INTO emp_count FROM emp WHERE deptno = 20;
IF emp_count > 50 THEN
RAISE too_many_employees;
END IF;
EXCEPTION
WHEN too_many_employees THEN
DBMS_OUTPUT.PUT_LINE('Error: Too many employees in department 20.');
END;
/
В этом примере определяемое пользователем исключение too_many_employees вызывается, когда в отделении 20 оказывается более 50 сотрудников.
Распространение исключений
Иногда вам может потребоваться обработать исключение не в том блоке, где оно возникло. В таких случаях вы можете использовать распространение исключения.
Когда исключение возникает и не обрабатывается в текущем блоке, оно распространяется на включающий (или вызывающий) блок. Это продолжается до тех пор, пока исключение либо обрабатывается, либо достигается самый внешний блок. Если исключение нигде не обрабатывается, программа завершается с ошибкой необработанного исключения.
DECLARE
value_null EXCEPTION;
PRAGMA EXCEPTION_INIT(value_null, -1476);
BEGIN
-- Это вызывает исключение
DECLARE
a number := 0;
b number := 1/a;
EXCEPTION
WHEN value_null THEN
dbms_output.put_line('A value is null!');
END;
В этом примере исключение распространяется от внутреннего блока во внешний блок, где оно обрабатывается.
Информационные функции исключений
Oracle предоставляет такие функции, как SQLCODE и SQLERRM, которые возвращают полезную информацию об исключениях. SQLCODE возвращает числовой код исключения, а SQLERRM возвращает сообщение, связанное с этим исключением.
Вот пример использования этих функций:
DECLARE
a number := 0;
b number := 1/a;
EXCEPTION
WHEN OTHERS THEN
dbms_output.put_line('Error code ' || SQLCODE || ': ' || SQLERRM);
END;
/
В этом примере, когда возникает исключение, выводятся код ошибки и сообщение об ошибке при использовании функций SQLCODE и SQLERRM соответственно.
Расширенная обработка исключений в PL/SQL предлагает больше контроля над процессом обработки ошибок, делая ваши программы более понятными и надежными.
Работа с пакетами Oracle
Введение в пакеты Oracle
Oracle предоставляет набор предварительно скомпилированных объектных модулей PL/SQL, известных как пакеты Oracle. Эти пакеты встроены в базу данных Oracle и значительно расширяют ее функциональность от выдачи сообщений на экран, ввода/вывода в файл и выполнения заданий по расписанию до отправки электронных писем и много другого.
Давайте рассмотрим несколько ключевых пакетов Oracle:
Пакет DBMS_OUTPUT
Пакет DBMS_OUTPUT позволяет отображать вывод, отладочную информацию или посылать сообщения из блоков, подпрограмм, пакетов и триггеров PL/SQL.
Вот базовый пример:
BEGIN
DBMS_OUTPUT.PUT_LINE('Hello, World!');
END;
/
В этом примере на экране отображается ‘Hello, World!’, используя процедуру PUT_LINE из пакета DBMS_OUTPUT.
Пакет UTL_FILE
Пакет UTL_FILE позволяет программам PL/SQL читать и записывать текстовые файлы операционной системы. Он предоставляет ограниченную версию ввода-вывода в стандартный поток файлов операционной системы.
Вот простой пример записи в файл:
DECLARE
file_handle UTL_FILE.FILE_TYPE;
BEGIN
file_handle := UTL_FILE.FOPEN('MY_DIR', 'my_file.txt', 'W');
UTL_FILE.PUT_LINE(file_handle, 'Hello, World!');
UTL_FILE.FCLOSE(file_handle);
EXCEPTION
WHEN OTHERS THEN
IF UTL_FILE.IS_OPEN(file_handle) THEN
UTL_FILE.FCLOSE(file_handle);
END IF;
RAISE;
END;
/
В этом примере мы используем пакет UTL_FILE для записи ‘Hello, World!’ в текстовый файл с именем ‘my_file.txt’, находящийся в каталоге ‘MY_DIR’.
Пакет DBMS_SCHEDULER
Пакет DBMS_SCHEDULER — более продвинутый и гибкий пакет выполнения заданий по расписанию, чем DBMS_JOB. Он позволяет планировать выполнение заданий (т.е. анонимных блоков PL/SQL, хранимых процедур PL/SQL и хранимых процедур Java) в заданное время/дату или через заданные интервалы.
Вот базовый пример планирования задания:
BEGIN
DBMS_SCHEDULER.CREATE_JOB(
job_name => 'my_test_job',
job_type => 'PLSQL_BLOCK',
job_action => 'BEGIN DBMS_OUTPUT.PUT_LINE(''Hello, World!''); END;',
start_date => SYSTIMESTAMP,
repeat_interval => 'FREQ=MINUTELY;INTERVAL=5',
enabled => TRUE);
END;
/
В этом примере мы создаем задание с именем ‘my_test_job’, которое выводит ‘Hello, World!’ каждые 5 минут от момента создания.
Работа с пакетами Oracle может в значительной мере улучшить вашу производительность, предоставляя предварительно встроенные решения для распространенных требований от посылки электронного сообщения с помощью UTL_MAIL до обработки больших объектов с помощью DBMS_LOB и многое еще. Их использование может сделать программирование на PL/SQL более эффектным и эффективным.
Настройка производительности в PL/SQL
Введение в настройку производительности
Настройка производительности является жизненно важным аспектом программирования в PL/SQL. Она гарантирует, что ваши приложения эффективно работают при высоких рабочих нагрузках. Существуют различные методы оптимизации, но мы сфокусируемся на некоторых практических стратегиях, которые могут оказать существенное влияние на производительность ваших приложений.
Оптимизация операторов SQL
SQL является языком интерактивного взаимодействия с базой данных в Oracle и, раз это так, важно, чтобы ваш SQL выполнялся хорошо. Инструмент Explain Plan в Oracle позволяет взглянуть изнутри, как выполняются ваши операторы SQL, что может направить ваши усилия по настройке в нужном направлении. Правильное индексирование, выбор корректных хинтов SQL и использование секционирования, где это уместно, могут значительно улучшить производительность вашего SQL.
Массовая обработка с BULK COLLECT и FORALL
Эти функции PL/SQL позволяют выполнять «массовые» операции, которые значительно ускоряют обработку большого количества данных. Сокращая переключение контекста между движками PL/SQL и SQL, эти функции могут значительно повысить производительность.
DECLARE
TYPE t_emp_tab IS TABLE OF employees%ROWTYPE;
emp_tab t_emp_tab;
BEGIN
SELECT *
BULK COLLECT INTO emp_tab
FROM employees;
FOR i IN emp_tab.FIRST .. emp_tab.LAST LOOP
emp_tab(i).salary := emp_tab(i).salary * 1.05; -- Увеличить на 5%
END LOOP;
FORALL i IN emp_tab.FIRST .. emp_tab.LAST
UPDATE employees SET row = emp_tab(i) WHERE employee_id = emp_tab(i).employee_id;
COMMIT;
END;
/
Использование переменных связывания
Переменные связывания могут помочь повторному использованию планов выполнения базы данных, улучшая производительность операторов SQL в коде PL/SQL. Без переменных связывания даже простые запросы с различными литеральными значениями будут рассматриваться базой данных как разные, погрождая многочисленные планы выполнения и снижая эффективность.
DECLARE
v_employee_id employees.employee_id%TYPE := 100;
v_first_name employees.first_name%TYPE;
BEGIN
SELECT first_name INTO v_first_name FROM employees WHERE employee_id = v_employee_id;
DBMS_OUTPUT.PUT_LINE('First name: ' || v_first_name);
END;
/
Оптимизатор PL/SQL
Введенный в Oracle 10g, оптимизатор PL/SQL автоматически пытается улучшить производительность кода PL/SQL. Эта возможность может быть задействована установкой уровня оптимизации на более высокий:
ALTER SESSION SET PLSQL_OPTIMIZE_LEVEL = 3;
Избегать необязательных вычислений
Одна простая, но эффективная стратегия состоит в том, чтобы избегать необязательных вычислений. Если вы обнаружите, что ваш код выполняет одни и те же вычисления в нескольких местах, рассмотрите возможность выполнить вычисления один раз, сохранения результата, а затем использовать этот результат при необходимости.
DECLARE
v_base_salary employees.salary%TYPE := 5000;
v_bonus employees.salary%TYPE := v_base_salary * 0.1; -- Вычисляем один раз
BEGIN
-- Используем предварительно вычисленное значение
INSERT INTO bonuses (employee_id, bonus) VALUES (100, v_bonus);
INSERT INTO bonuses (employee_id, bonus) VALUES (101, v_bonus);
INSERT INTO bonuses (employee_id, bonus) VALUES (102, v_bonus);
END;
/
Использование инструментов для анализа производительности
Oracle предоставляет такие инструменты, как TKPROF и AUTOTRACE, которые могут использоваться для анализа производительности ваших запросов SQL и обнаружения проблемных мест. Эти инструменты дают подробные отчеты о выполнении кода SQL и PL/SQL, облегчая идентификацию тех мест, настройка производительности которых может дать выигрыш.
Настройка производительности — процесс итерационный. После устранения одних узких мест могут проявиться другие. Однако понимание этих методов и их правильное применение может значительно ускорить и сделать более эффективным ваш код PL/SQL. Важно продолжать исследование и изучение настройки производительности, поскольку это может существенно повысить эффективность ваших приложений базы данных Oracle.
Взаимодействие PL/SQL и SQL*PLUS
Введение в SQL*Plus
SQL*Plus — это инструмент интерактивных и пакетных запросов, который устанавливается с каждой инсталляцией базы данных Oracle и обеспечивает функциональность SQL, PL/SQL и скриптов. Это важный инструмент для взаимодействия с базой данных Oracle, и понимание того, как он взаимодействует с PL/SQL, может быть полезным.
Выполнение блоков PL/SQL
Анонимные блоки PLSQL могут непосредственно выполняться в SQL*Plus. Вот пример с объявлением переменной, присвоением ей значения с его последующим выводом:
DECLARE
v_message VARCHAR2(50) := 'Hello, SQL*Plus!';
BEGIN
DBMS_OUTPUT.PUT_LINE(v_message);
END;
/
Не забывайте использовать прямой слэш (/) для выполнения блоков PL/SQL в SQL*Plus.
Использование переменных SQL*Plus в блоках PL/SQL
Вы можете определять переменные в SQL*Plus, а затем ссылаться на них в блоках PL/SQL:
DEFINE v_message = 'Hello, SQL*Plus!'
DECLARE
v_local_message VARCHAR2(50) := '&v_message';
BEGIN
DBMS_OUTPUT.PUT_LINE(v_local_message);
END;
/
В этом примере &v_message в блоке PL/SQL является переменная подстановки, которая заменяется значением v_message, определенной в SQL*Plus.
Использование команды SET SERVEROUTPUT
По умолчанию вывод пакета DBMS_OUTPUT не отображается в SQL*Plus. Для вывода вам необходимо использовать команду SET SERVEROUTPUT ON:
SET SERVEROUTPUT ON
DECLARE
v_message VARCHAR2(50) := 'Hello, SQL*Plus!';
BEGIN
DBMS_OUTPUT.PUT_LINE(v_message);
END;
/
Выполнение хранимых процедур и функций
Хранимые процедуры и функции также могут непосредственно быть выполнены из SQL*Plus. Для процедур вы можете просто сделать вызов:
EXECUTE procedure_name(аргументы);
Для функций, которые возвращают значение, вы можете использовать оператор SELECT:
SELECT function_name(аргументы) FROM dual;
Сценарии в SQL*Plus
SQL*Plus может также выполнять скрипты, которые являются просто текстовыми файлами со списком команд SQL*Plus, SQL и PL/SQL. Вы можете использовать эту функцию для выполнения последовательности команд всех сразу.
Например, вы можете создать файл сценария с именем script.sql и следующим содержимым:
SET SERVEROUTPUT ON
DECLARE
v_message VARCHAR2(50) := 'Hello, SQL*Plus!';
BEGIN
DBMS_OUTPUT.PUT_LINE(v_message);
END;
/
Затем вы можете выполнить этот скрипт в SQL*Plus с помощью следующей команды:
@script.sql
Владение взаимодействием между SQL*Plus and PL/SQL позволит вам получить максимальную отдачу от базы данных Oracle и упростит процесс разработки базы данных.
Естественная компиляция PL/SQL
Oracle предоставляет возможность естественной компиляции кода PL/SQL в машинный код, который может значительно улучшить производительность выполнения программ PL/SQL. Естественная компиляция — это процесс, при котором исходный код PL/SQL компилируется в разделяемую библиотеку в форме DLL на Windows или SO (Shared Object — разделяемый объект) в системах Unix/Linux.
Вот как вы можете включить и использовать естественную компиляцию PL/SQL:
Включение естественной компиляции
Для использования естественной компиляции вам необходимо включить ее на системном уровне. Вы можете использовать следующую команду:
ALTER SYSTEM SET PLSQL_CODE_TYPE = 'NATIVE';
Эта команда заставит Oracle естественным образом компилировать весь новый код PL/SQL.
Компилирование существующего кода
Если вы хотите откомпилировать существующий код PL/SQL, вы можете использовать следующую команду:
ALTER PROCEDURE имя_процедуры COMPILE PLSQL_CODE_TYPE = NATIVE;
Замените имя_процедуры на имя процедуры, функции, пакета или триггера, который вы хотите откомпилировать.
Проверка компиляции
Вы можете проверить, откомпилирован ли ваш код PL/SQL естественным образом или интерпретируется, с помощью следующего запроса:
SELECT name, type, plsql_code_type
FROM user_code
WHERE name = 'PROCEDURE_NAME';
Замените PROCEDURE_NAME на имя процелуры, функции, пакета или триггера. Столбец PLSQL_CODE_TYPE будет содержать NATIVE, если код откомпилирован, и INTERPRETED в противном случае.
Имейте в виду, что хотя естественная компиляция може улучшить скорость выполнения кода PL/SQL, она не влияет на производительность операторов SQL внутри кода PL/SQL. Производительность операторов SQL определяется оптимизатором Oracle SQL.
Понимание и правильное использовнаие естественной компиляции PL/SQL может помочь вам оптимизировать производительность приложений базы данных Oracle.
Продвинутые триггеры базы данных
Триггерами базы данных являются именованные блоки PL/SQL, которые хранятся в базе данных и автоматически выполняются (срабатывают), когда наступают определенные события. В предыдущей статье мы обсудили простые триггеры, которые связаны с событиями DML (вставка, обновление, удаление) для конкретной таблицы. Однако есть еще более продвинутые типы триггеров, которые вы можете использовать для применения сложных бизнес правил или расширения функциональности вашей базы данных.
Триггеры Instead of
Эти триггеры определяются на представлениях, и они срабатывают вместо события, которое их вызвало. Они могут использоваться для модификации данных в базовой таблице, когда операция DML выполняется на представлении.
Вот пример триггера instead of:
CREATE OR REPLACE TRIGGER io_emp_view
INSTEAD OF INSERT ON emp_view
FOR EACH ROW
BEGIN
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (:NEW.employee_id, :NEW.first_name, :NEW.last_name);
END;
/
Этот триггер должен вставить данные в таблицу employees, в то время как вставка выполняется для представления emp_view.
Триггеры системных событий
Эти триггеры срабатывают, когда возникают системные события. Наиболее общими типами системных событий являются события входа и выхода, ошибки сервера, запуск или выключение базы данных и т.п.
Вот пример триггера на вход:
CREATE OR REPLACE TRIGGER logon_audit
AFTER LOGON ON DATABASE
BEGIN
INSERT INTO logon_audit (username, logon_time)
VALUES (USER, SYSDATE);
END;
/
Этот триггер будет вставлять запись в таблицу logon_audit всякий раз, когда пользователь подключается к базе данных.
Триггеры DDL
Эти триггеры срабатывают в ответ на операторы DDL (языка определения данных) типа CREATE, ALTER, DROP и т.д. Они могут оказаться полезными для отслеживания изменений схемы базы данных.
Вот пример триггера DDL:
CREATE OR REPLACE TRIGGER ddl_audit
AFTER DDL ON DATABASE
BEGIN
INSERT INTO ddl_audit (username, timestamp, operation)
VALUES (USER, SYSDATE, ora_sysevent);
END;
/
Этот триггер будет вставлять запись в таблицу ddl_audit всякий раз, когда пользователь выполняет операцию DDL.
Продвинутые триггеры базы данных позволяют применять сложную логику в ответ на различные события базы данных, делая ваши приложения базы данных Oracle более мощными и гибкими. Понимание подобных триггеров может помочь вам более эффективно управлять и обслуживать базы данных.
Динамический SQL в PL/SQL
Введение в динамический SQL
Динамический SQL — это технология, используемая для построения операторов SQL динамически во время исполнения. Это особенно полезно, когда вам нужно выполнять операцию, но вы заранее не знаете, с какой таблицей или какими столбцами вы будет работать. Динамический SQL применяется в PL/SQL посредством оператора EXECUTE IMMEDIATE и пакета DBMS_SQL.
EXECUTE IMMEDIATE
Оператор EXECUTE IMMEDIATE позволяет выполнить оператор динамического SQL или анонимный блок PL/SQL.
Вот пример того, как вы можете использовать EXECUTE IMMEDIATE для вставки данных в таблицу:
DECLARE
v_table_name VARCHAR2(30) := 'employees';
v_sql VARCHAR2(1000);
BEGIN
v_sql := 'INSERT INTO ' || v_table_name || ' VALUES (100, ''John'', ''Doe'')';
EXECUTE IMMEDIATE v_sql;
END;
/
В этом примере оператор SQL конструируется динамически, используя переменную v_table_name, а затем выполняется с помощью EXECUTE IMMEDIATE.
Пакет DBMS_SQL
Пакет DBMS_SQL предоставляет более продвинутый интерфейс для динамического SQL, позволяя выполнять анализ оператора SQL любого типа, а также связывание и определение заполнителей.
Вот пример того, как можно использовать пакет DBMS_SQL для динамического выполнения оператора SELECT:
DECLARE
v_cursor NUMBER;
v_count NUMBER;
v_sql VARCHAR2(1000);
BEGIN
v_sql := 'SELECT COUNT(*) FROM employees WHERE department_id = :dept_id';
v_cursor := DBMS_SQL.OPEN_CURSOR;
DBMS_SQL.PARSE(v_cursor, v_sql, DBMS_SQL.NATIVE);
DBMS_SQL.BIND_VARIABLE(v_cursor, ':dept_id', 10);
DBMS_SQL.DEFINE_COLUMN(v_cursor, 1, v_count);
DBMS_SQL.EXECUTE_AND_FETCH(v_cursor, v_count);
DBMS_OUTPUT.PUT_LINE('Count: ' || v_count);
DBMS_SQL.CLOSE_CURSOR(v_cursor);
END;
/
В этом примере пакет DBMS_SQL используется для анализа оператора SQL, связывания значения с заполнителем :dept_id, определения переменной для хранения результата оператора SELECT, выполнения оператора, получения результата и, наконец, закрытия курсора.
Динамический SQL может стать мощным инструментом в вашем арсенале прораммирования на PL/SQL, позволяя писать гибкий и адаптивный код, который может выполнять операции на базе условий, которые становятся известными только во время выполнения. Однако всегда следует заботиться о потенциальных рисках SQL-инъекции и принимать надлежащие меры предосторожности при построении динамических операторов SQL.
Заключение
В этой статье мы продвинулись глубже в возможности Oracle PL/SQL, фокусируясь на продвинутых средствах, таких как использование сложных курсоров, нетривиальная обработка исключений, пакеты Oracle, настройка производительности, взаимодействие с SQL*Plus, естественная компиляция PL/SQL, сложные триггеры базы данных и динамический SQL. Предлагаемые примеры и их объяснение должны расширить ваше понимание и навыки работы с Oracle PL/SQL, что позволит вам с легкостью справляться с более сложными сценариями.
Как обрабатывать конфликтные ситуации в оракл sql
Распределенные базы данных, в отличие от централизованных, призваны сократить объемы информации, передаваемые по телекоммуникационным линиям и повысить оперативность доступа к актуальным данным. Важной задачей является обеспечение оперативного устранения конфликтов репликации, синхронизации данных и обеспечении бесперебойного процесса репликации данных между узлами базы данных. Время, затраченное на решение данных задач, напрямую зависит от возможностей используемого программного обеспечения. Компания Oracle Corp. предлагает в составе СУБД Oracle решение, позволяющее управлять реплицированием данных в распределённых базах данных. На сегодняшний день это решение является недостаточно функциональным и эффективным в области разрешения конфликтных транзакций. В данной статье предложен альтернативный способ разрешения конфликтов репликации, который является более эффективным по сравнению с Oracle Enterprise Manager.

база данных
репликация данных
конфликты репликации
1. Базилевский Е.В. Автоматизация деятельности администратора баз данных при работе с конфликтами репликаций в системах управления баз данных ORACLE // Наука и инновации ХХI века : мат-лы Х Юбил. окр. конф. молодых учёных, Сургут, 26-27 нояб. 2009 г. : в 2 т. / Сургут. гос. ун-т ХМАО — Югры. — Сургут : ИЦ СурГУ, 2010. — Т. 1. — С. 21-23.
2. Гаршин И.К. Практика работы с Oracle: генерация, администрирование, репликация. — М. : ПОЛТЕКС, 2000. — 250 с. : ил.
3. Хорстманн К., Корнелл Г. Java 2. Библиотека профессионала, том 1. Основы. — 7-е изд. : Пер. с англ. — М. : Издательский дом «Вильямс», 2006. — 286 с. : ил. — Парал. тит. англ.
4. James Gosling, Henry McGilton. The Java Language Environment: Contents [Электронный ресурс] / A White Paper // May 1996. — URL: http://java.sun.com/docs/white/ langenv (дата обращения: 27.02.2012).
5. Oracle [Электронный ресурс] / Oracle Replication. — URL: http://www.oracle.com/global/ru/pdfs/tech/tg_oracle_replication.pdf (дата обращения: 29.02.2012).
Введение
В распределенной базе данных конфликт репликации возникает при одновременном (условно) изменении одной записи в результате выполнения транзакций разными серверами над локальными репликами. Однако конфликт будет обнаружен только при синхронизации данных. Все распределенные СУБД идентифицируют конфликты, но не всегда могут обеспечить автоматическое их устранение — отмену всех изменений или применение одного из них, т.к. эта задача требует вмешательства человека (администратора) из-за необходимости учета специфики назначения и структуры данных, конкретных значений, объектов и характера конфликта. Эффективность разрешения конфликтов, а с другой стороны — потери из-за отказов в выполнении запросов к заблокированным объектам базы данных зависят от функциональных и эксплуатационных характеристик предоставляемого администратору инструментария СУБД.
Обработка конфликтов репликации в СУБД Oracle
В СУБД Oracle при возникновении конфликтной транзакции соответствующие данные помещаются в системную таблицу system.def$_aqerror. Основными полями, описывающими конфликтные транзакции, являются [2]:
- ENQ_TID — порядковый номер конфликтной транзакции;
- STEP_NO — номер вызова в транзакции;
- USER_DATA — непосредственно информация об изменении объекта БД.
Значение поля USER_DATA представляет собой массив байт, для хранения которого в Oracle используется тип BLOB. Байты в массиве располагаются следующим образом (рис. 1). Первый байт определяет тип аргумента, над которым пользователем были произведены изменения. Каждому типу аргумента соответствует определенное количество байт. Следующий байт определяет количество байт, в соответствие с указанным типом аргумента, в которых закодированы изменения аргумента пользователями. Далее в указанном количестве байт содержится информация об исходном значении аргумента до внесения изменений пользователями. Следующая группа байт такого же размера содержит модифицированное значение аргумента. Таким образом, алгоритм сводится к последовательному разбору массива байт, хранящегося в поле USER_DATA по каждому вызову в конфликтной транзакции. Текущее значение изменяемого аргумента определяется непосредственно из БД по SQL-запросу.

Рис. 1. Массив байт поля USER_DATA.
Таким образом, каждая транзакция содержит в себе определённое количество вызовов, которые в свою очередь содержат набор аргументов. Количество аргументов зависит от определённой таблицы, над которой были произведены действия пользователем, и если количество полей в таблице велико, то соответственно количество аргументов также будет большим.
Разработчиками СУБД Oracle предлагается администратору баз данных использовать функционал приложения Oracle Enterprise Manager (OEM) для разрешения конфликтных транзакций [5]. ОЕМ последовательно извлекает конфликтные транзакции из очереди и выполняет их разбор при помощи системного (для СУБД Oracle) пакета dbms_defer_query. Полученная в результате разбора информация отображается для принятия решения администратором БД, после чего конфликтная транзакция удаляется из очереди. Общий алгоритм разбора конфликтной транзакции в ОЕМ показан на рис. 2.
Разбор конфликтных транзакций в OEM реализован при помощи пакета dbms_defer_query. Данный пакет содержит следующие функции, которые позволяют получать данные, необходимые для разбора вызовов в конфликтных транзакциях [5]:
- get_arg_form — возвращает набор символов для указанного аргумента в вызове конфликтной транзакции, который используется в последующей обработке;
- get_arg_type — определяет тип аргумента в вызове;
- get_datatype_arg — определяет значение аргумента в вызове в соответствии с одним из следующих типов: NUMBER, VARCHAR2, СHAR, DATE, RAW, ROWID, BLOB, CLOB, NCLOB, NCHAR, NVARCHAR2, TIMESTAMP.
Текущее значение данных изменяемой таблицы определяется непосредственно путём обращения к таблице и считывания необходимых данных по каждому аргументу вызова конфликтной транзакции.
Языком разработки OEM является Java. В отличие от многих языков программирования, Java — это еще и программная платформа, включающая большой объём кода мощной библиотеки и среду для выполнения программ (Java Virtual Machine), которая обеспечивает безопасность, независимость от операционной системы и автоматическую «сборку мусора».
В руководстве по языку Java декларируются такие его свойства, как: простой, объектно-ориентированный, распределённый, надёжный, безопасный, независимый от архитектуры компьютера, переносимый, интерпретируемый, высокопроизводительный, многопотоковый, динамичный [3]. Такие характеристики, как независимость от архитектуры компьютера и производительность, требуют более подробного рассмотрения.
Компилятор Java генерирует объектный файл, формат которого не зависит от архитектуры компьютера. Объектный файл содержит байтовый код, разработанный таким образом, чтобы его можно было легко интерпретировать с помощью виртуальной машины [4]. Интерпретация байтового кода всегда будет выполняться медленнее, чем выполнение эквивалентного машинного кода. Однако на многих платформах возможна так называемая синхронная компиляция (just-in-time compilers — JIT) байтового кода, но даже в этом случае в итоге не обеспечивается такая же производительность, как при компиляции, ориентированной на конкретный тип процессора [3].

Рис. 2. Блок-схема разбора вызовов в OEM.
Таким образом, независимость от архитектуры компьютера является в то же время и слабой стороной Java, обуславливающей снижение производительности программ, разработанных на этой платформе. Тот факт, что OEM разработан на Java, является одним из факторов, снижающих производительность этого ПО.
Выполнение различных операций в OEM сопровождается множеством фоновых задач, выполняемых JVM, что существенно увеличивает время получения результата. Взаимодействие OEM с базой данных осуществляется посредством JDBC (Java Database Connectivity — интерфейс взаимодействия Java-приложений с базами данных) [5].
Для разрешения конфликтных транзакций в распределённой БД необходимо получить список конфликтных транзакций и детальную информацию по каждому вызову транзакции. Это реализуется посредством вызова упомянутых выше функций, исполняемых JVM, которая формирует ряд SQL-запросов к конкретной БД и получает результат их выполнения. После выполнения обработки полученной информации по заложенным в OEM алгоритмам JVM выполняет преобразование информации в удобочитаемую форму.
При таком взаимодействии OEM и JVM наиболее критическими факторами с точки зрения производительности являются следующие:
- время обработки действий администратора в OEM, время формирования соответствующих SQL-запросов к интересующей БД, время преобразования полученного результата из БД, а также время предоставления обработанных данных непосредственно администратору определяется не только быстродействием платформы, но и эффективностью интерпретации байт-кода;
- в силу большого объема данных, полученных из БД, и ограниченности ресурсов рабочего места администратора их оперативная обработка в OEM посредством JVM и отображение результата в OEM иногда оказываются невозможными (приложение «зависает»). По причине постоянного роста промышленных БД подобные ситуации довольно часты, но являются крайне нежелательными, особенно при разборе конфликтных транзакций и синхронизации данных между различными узлами распределённой БД;
- получение «старых», «текущих» и «новых» значений изменяемых объектов БД при разборе вызовов в конфликтных транзакциях происходит посредством выполнения соответствующих функций и процедур из системного пакета dbms_defer_query: get_arg_form, get_datatype_arg и get_arg_type. При большом количестве конфликтных транзакций с большим количеством вызовов в каждой из них серверу БД необходимо больше времени на обработку данных, что не позволяет оперативно получить информацию, необходимую для анализа и принятия решения по разрешению конфликтных транзакций, тем самым синхронизировать данные между различными узлами распределенной БД.
Альтернативный способ разбора конфликтных транзакций
Описанные выше проблемы, свойственные OEM, устраняются при использовании утилиты ErrManager, разработанной автором в среде Embarcadero Delphi. ErrManager получает необходимые данные из БД путём SQL-запросов. Время получения данных ограничено только загруженностью БД и связью между клиентской машиной и сервером БД, а разбор конфликтной транзакции осуществляется на стороне клиента с существенно меньшим, в отличие от OEM, использованием ресурсов сервера БД [1]. Алгоритм разбора показан на рис. 3.

Рис. 3. Блок схема разбора вызовов в ErrManager.
ErrManager разбирает BLOB-значения без использования системного пакета dbms_defer_query, тем самым получая необходимые исходные значения изменяемых объектов БД. Это значительно снижает время получения старых, новых и текущих значений за счёт снижения количества и сокращения времени обращений к БД, тем самым значительно уменьшая время разрешения конфликта.
Таким образом, на основе анализа выше описанного алгоритма разбора вызовов в конфликтных транзакциях можно заключить, что время разбора значительно сокращается за счёт того, что для каждого вызова в транзакции анализируется фактически только однократно извлекаемое значение поля USER_DATA таблицы system.def$_aqerror. Разбор массива байт путём считывания и преобразования в число или текст является более эффективным и не требует использования ресурсов БД, по сравнению с повторяющимися многократно вызовами набора функций из системного пакета при разборе вызовов в OEM.
Разработанная утилита ErrManager имеет вид приложения пользователя (рис. 4).

Рис. 4. Общий вид приложения ErrManager.
Функции, реализованные в утилите ErrManager, позволяют [1]:
- получать информацию о конфликтной транзакции и отображать информацию о состоянии данных в БД-источнике перед внесением изменения, данные, измененные пользователем, и текущие данные на БД-приемнике;
- преобразовывать изменения в SQL-запрос для повтора этих действий на приемнике;
- приводить запись на приемнике к такому же виду, какой она была на источнике до внесения изменений, что позволяет разрешить конфликт путём простого повтора выполнения ошибочной транзакции;
- повторять выполнение конфликтных транзакций и удалять их группами;
- автоматически разрешать конфликтные транзакции указанным способом (из числа приведенных выше) и очищать очередь транзакций после выполненных действий;
- отфильтровывать очередь конфликтных транзакций с разных БД при отображении в рабочей области программы;
- автоматически выявлять конфликтный вызов в транзакции;
- отключать репликацию на другие узлы распределённой БД, при синхронизации данных;
- автоматически преобразовывать SQL-запросы на вставку в запросы на изменение при наличии уже существующей записи в БД-приемнике;
- автоматически получать SQL-скрипт разрешения конфликтной транзакции и выполнять его на БД-приемнике;
- формировать отчет в форме HTML по указанным конфликтным транзакциям как в форме OEM, так и в собственной форме;
- позволяет вести мониторинг наличия конфликтных транзакций на указанном узле распределённой БД.
Заключение
Проведенное тестирование утилиты ErrManager включало в себя временную оценку процесса разрешения конфликтных транзакций и синхронизации данных при реплицировании информации между различными узлами распределённой БД. Результаты тестирования показали, что использование ErrManager является более эффективным по сравнению с Oracle Enterprise Manager.
Рецензенты
- Бадулин Н.Н., д.т.н., профессор кафедры радиоэлектроники ГОУ ВПО «Сургутский государственный университет Ханты-Мансийского автономного округа — Югры», г. Сургут.
- Кожухов С.Ф., д.физ.-мат.н., профессор, заведующий кафедрой высшей математики факультета информационных технологий ГОУ ВПО «Сургутский государственный университет Ханты-Мансийского автономного округа — Югры», г. Сургут.
Минимизация проблем с SQL для миграций Oracle
Эта статья представляет собой пятую из семи статей, посвященных рекомендациям по миграции данных из Oracle в Azure Synapse Analytics. Эта статья посвящена рекомендациям по минимизации проблем с SQL.
Обзор
Характеристики сред Oracle
Первоначальная база данных Oracle, выпущенная в 1979 году, представляла собой коммерческую реляционную базу данных SQL для OLTP-приложений с гораздо более низкой скоростью транзакций, чем сегодня. С тех пор среда Oracle превратилась в гораздо более сложную и включает в себя множество функций. К ним относятся клиент-серверные архитектуры, распределенные базы данных, параллельная обработка, аналитика данных, высокая доступность, хранилища данных, технологии обработки данных в памяти и поддержка облачных экземпляров.
В начале 2000-х годов Oracle впервые разработала концепцию «устройства хранилища данных».
Из-за затратности и сложности обслуживания и обновления устаревших локальных сред Oracle многие существующие пользователи Oracle хотят воспользоваться преимуществами инноваций, предоставляемых облачными средами. Современные облачные среды, такие как облако, IaaS и PaaS, позволяют делегировать такие задачи, как обслуживание инфраструктуры и разработка платформы, поставщику облачных служб.
Многие хранилища данных, которые поддерживают сложные аналитические запросы SQL, адресованные большим объемам данных, используют технологии Oracle. В таких хранилищах данных обычно используется многомерная модель данных, например схемы типа «звезда» или «снежинка», а также киоски данных для разных отделов.
Многие существующие установки Oracle — это хранилища данных, использующие модель мерных данных.
Такое сочетание SQL и многомерных моделей данных в Oracle упрощает переход на Azure Synapse, так как основные концепции модели данных SQL можно перенести. Microsoft рекомендует переносить существующую модель данных в Azure как есть, чтобы сократить риски, усилия и время миграции. Несмотря на то что план миграции может включать изменение базовой модели данных, например переход от модели Инмона к хранилищу данных, имеет смысл изначально выполнить перенос как есть. После первоначальной миграции можно внести изменения в облачную среду Azure, чтобы воспользоваться ее преимуществами: производительностью, эластичной масштабируемостью, встроенными функциями и экономичностью.
Хотя язык SQL стандартизирован, отдельные поставщики иногда реализуют собственные расширения. В результате во время миграции можно обнаружить различия, требующие поиска обходных путей в Azure Synapse.
Использование ресурсов Azure для выполнения миграции на основе метаданных
Вы можете автоматизировать и оркестрировать процесс миграции, используя возможности среды Azure. Такой подход позволяет снизить влияние на существующую среду Oracle, нагрузка на которую уже может быть максимальной.
Фабрика данных Azure — это облачная служба интеграции данных, которая позволяет создавать управляемые данными рабочие процессы в облаке для оркестрации и автоматизации перемещения и преобразования данных. С помощью Фабрики данных можно создавать и включать в расписание управляемые данными рабочие процессы (конвейеры), которые принимают данные из разнородных хранилищ. Фабрика данных может обрабатывать и преобразовывать эти данные с помощью таких служб вычислений, как Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics и машинное обучение Azure.
Azure также включает Службы Azure Database Migration Services, которые помогут вам спланировать и выполнить миграцию из таких сред, как Oracle. Помощник по миграции SQL Server (SSMA) для Oracle может автоматизировать миграцию баз данных Oracle, в том числе в некоторых случаях функции и процедурный код.
Автоматизируйте процесс миграции с помощью возможностей Фабрики данных Azure.
Планируя использование средств Azure, таких как фабрики данных, для управления процессом миграции, сначала создайте метаданные со списком всех таблиц данных, которые необходимо перенести, и их расположений.
Различия SQL DDL между Oracle и Azure Synapse
Стандарт ANSI SQL определяет базовый синтаксис для команд языка описания данных (DDL). Некоторые команды DDL, такие как CREATE TABLE и CREATE VIEW , являются общими для Oracle и Azure Synapse, но были расширены для предоставления характерных для своей реализации возможностей, таких как индексирование, распределение таблиц и параметры секционирования.
Команды SQL DDL CREATE TABLE и CREATE VIEW содержат стандартные основные элементы, но также используются для определения вариантов, связанных с конкретной реализацией.
В следующих разделах рассматриваются параметры Oracle, которые необходимо учитывать при переходе на Azure Synapse.
Рекомендации по таблицам и представлениям
При переносе таблиц между разными средами обычно перемещаются только необработанные данные и метаданные, описывающие их физическую миграцию. Другие элементы базы данных из исходной системы, такие как индексы и файлы журнала, обычно не переносятся, так как они могут оказаться не нужны или реализованы по-другому в новой среде. Например, параметр TEMPORARY в синтаксисе Oracle CREATE TABLE эквивалентен префиксу имени таблицы с символом # в Azure Synapse.
Механизмы оптимизации производительности в исходной среде, например индексы, помогают понять, как именно можно оптимизировать производительность в новой целевой среде. Например, если индексы, сопоставленные с битами, часто используются в запросах в исходной среде Oracle, это предполагает необходимость создания некластеризованного индекса в Azure Synapse. Применение других нативных методов оптимизации производительности, например репликации таблиц, может быть более целесообразным, чем прямое создание аналогичных индексов. SSMA для Oracle может предоставлять рекомендации по миграции для распределения таблиц и индексирования.
Существующие индексы помогают найти кандидатов на индексирование в перенесенном хранилище.
Определения представлений SQL содержат инструкции языка обработки данных SQL (DML), которые определяют представление, как правило, с одной или несколькими инструкциями SELECT . При переносе инструкций CREATE VIEW учитывайте различия в DML между Oracle и Azure Synapse.
Неподдерживаемые типы объектов базы данных Oracle
Функции Oracle можно заменить функциями Azure Synapse. Однако Azure Synapse не поддерживает некоторые объекты базы данных Oracle напрямую. В следующем списке неподдерживаемых объектов базы данных Oracle описывается, как реализовать эквивалентные функциональные возможности в Azure Synapse:
- Параметры индексирования: в Oracle существует несколько вариантов индексирования, таких как индексы, сопоставленные с битами, индексы на основе функций и доменные индексы, которые не имеют прямого эквивалента в Azure Synapse. Несмотря на то что Azure Synapse не поддерживает эти типы индексов, можно добиться аналогичного сокращения количества дисковых операций ввода-вывода, используя определяемые пользователем типы индексов и (или) секционирование. Сокращение количества дисковых операций ввода-вывода повышает эффективность обработки запросов. Вы можете узнать, какие столбцы индексируются и их тип индекса, запрашивая таблицы и представления системного каталога, например ALL_INDEXES , DBA_INDEXES , USER_INDEXES и DBA_IND_COL . Кроме того, если включен мониторинг, можно запрашивать представления dba_index_usage или v$object_usage . Функции Azure Synapse, такие как параллельная обработка запросов и кэширование в памяти данных и результатов, обуславливают вероятность того, что для достижения высочайшей производительности приложениям хранилища данных потребуется меньше индексов.
- Кластеризованные таблицы: таблицы Oracle можно упорядочить так, чтобы строки таблиц, доступ к которым часто осуществляется совместно (на основе общего значения), хранились бы вместе физически. Эта стратегия сокращает число дисковых операций ввода-вывода при извлечении данных. Oracle также имеет параметр хэш-кластера для отдельных таблиц, который применяет хэш-значение к ключу кластера и физически хранит строки с одинаковым хэш-значением. В Azure Synapse такого же результата можно добиться путем секционирования и(или) использования других типов индексов.
- Материализованные представления. Oracle поддерживает материализованные представления и рекомендует использовать одно или несколько из них в больших таблицах с большим количеством столбцов, где в запросах регулярно используются только некоторые из этих столбцов. Материализованные представления автоматически обновляются системой при обновлении данных в базовой таблице. В 2019 году Microsoft объявила, что Azure Synapse будет поддерживать материализованные представления с теми же функциями, что и Oracle. Материализованные представления уже доступны в Azure Synapse в качестве предварительной версии функции.
- Триггеры в базе данных: в Oracle триггер можно настроить для автоматического запуска при возникновении события активации. Событиями активации могут быть следующие:
- Выполняется инструкция DML, такая как INSERT , UPDATE или DELETE . Если вы определили триггер, который срабатывает перед инструкцией INSERT в таблице клиента, триггер сработает один раз, прежде чем новая строка будет вставлена в таблицу клиента.
- Выполняется инструкция DML, такая как CREATE или ALTER . Это событие активации часто используется для записи изменений схемы в целях аудита.
- Системное событие, например запуск или завершение работы базы данных Oracle.
- Пользовательское событие, например вход или выход.
Azure Synapse не поддерживает триггеры базы данных Oracle. Однако вы можете реализовать эквивалентные функциональные возможности с помощью фабрики данных, хотя для этого потребуется выполнить рефакторинг процессов, использующих триггеры.
Создание DDL SQL
Для получения эквивалентных определений в Azure Synapse можно отредактировать существующие скрипты Oracle CREATE TABLE и CREATE VIEW . Для этого может потребоваться задействовать модифицированные типы данных и удалить или изменить характерные для Oracle предложения, например TABLESPACE .
Используйте существующие метаданные Oracle для автоматизации создания DDL CREATE TABLE и CREATE VIEW для Azure Synapse.
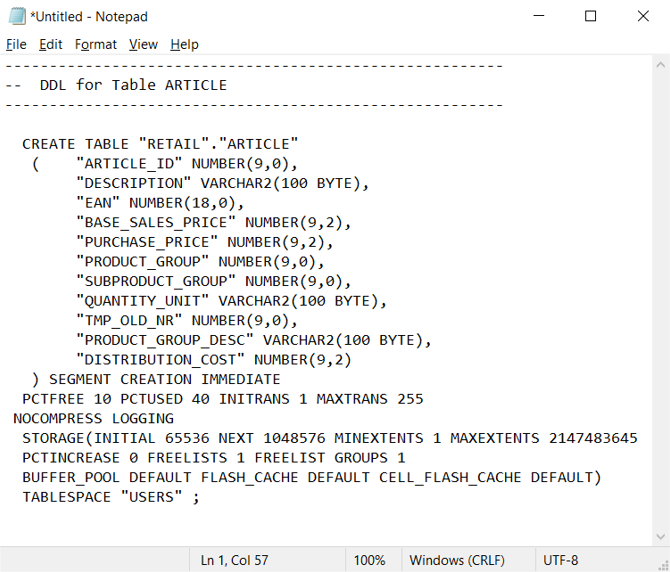
В среде Oracle определение текущей таблицы и представления задают таблицы системного каталога. В отличие от пользовательской документации сведения из системного каталога всегда являются полными и в точности соответствуют текущим определениям таблиц. Доступ к сведениям о системных каталогах можно получить с помощью таких служебных программ, как Oracle SQL Developer. Oracle SQL Developer может создавать инструкции DDL CREATE TABLE , которые можно изменить для применения к эквивалентным таблицам в Azure Synapse, как показано на следующем снимке экрана.
Oracle SQL Developer выводит следующую инструкцию CREATE TABLE , которая содержит предложения Oracle, которые следует удалить. Прежде чем выполнять измененную инструкцию CREATE TABLE в Azure Synapse, сопоставьте все неподдерживаемые типы данных.
Кроме того, можно автоматически создавать инструкции CREATE TABLE из сведений в таблицах каталога Oracle с помощью SQL-запросов, SSMA или сторонних средств миграции. Этот подход является самым быстрым и согласованным способом создания инструкций CREATE TABLE для многих таблиц.
Сторонние средства и службы могут автоматизировать задачи сопоставления данных.
Сторонние поставщики предлагают инструменты и сервисы для автоматизации миграции, в том числе для сопоставления типов данных. Если в среде Oracle уже используется сторонний инструмент для извлечения, преобразования и загрузки (ETL) данных, воспользуйтесь им для выполнения всех необходимых преобразований с данными.
Различия SQL DML между Oracle и Azure Synapse
Стандарт ANSI SQL определяет базовый синтаксис для таких команд DML, как SELECT , INSERT , UPDATE и DELETE . Несмотря на то что Oracle и Azure Synapse поддерживают команды DDL, в некоторых случаях они реализуют одну и ту же команду по-разному.
Стандартные команды SQL DML SELECT , INSERT и UPDATE могут иметь дополнительные параметры синтаксиса в разных средах баз данных.
В следующих разделах рассматриваются характерные для Oracle команды DML, которые необходимо учитывать при переходе на Azure Synapse.
Различия в синтаксисе SQL DML
Между Oracle SQL и Azure Synapse T-SQL существуют некоторые различия в синтаксисе SQL DML:
-
Таблица DUAL : в Oracle есть системная таблица с именем DUAL , которая состоит ровно из одного столбца с именем dummy и одной записи со значением X . Системная таблица DUAL используется, если запрос требует названия таблицы по причине синтаксиса, однако содержимое таблицы не требуется. Пример запроса Oracle, использующего таблицу DUAL , — SELECT sysdate from dual; . Эквивалент в Azure Synapse — SELECT GETDATE(); . Чтобы упростить миграцию DML, можно создать в Azure Synapse эквивалентную таблицу DUAL с помощью следующего DDL.
CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GOSELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;Эквивалентный стандартный синтаксис ANSI:
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;Функция Oracle Описание Эквивалент в Synapse ADD_MONTHS Добавление указанного числа месяцев DATEADD CAST Преобразование одного встроенного типа данных в другой CAST DECODE Оценка списка условий CASE, выражение EMPTY_BLOB Создание пустого значения BLOB-объекта Константа 0x (пустая двоичная строка) EMPTY_CLOB Создание пустого значения CLOB или NCLOB » (пустая строка) INITCAP Перевод первой буквы каждого слова в верхний регистр Определяемая пользователем функция INSTR Поиск позиции подстроки в строке CHARINDEX LAST_DAY Получение последней даты месяца EOMONTH LENGTH Получение длины строки в символах LEN LPAD Строка левой панели до указанной длины Выражение с использованием параметров REPLICATE, RIGHT и LEFT MOD Получение остатка в результате деления одного числа на другое Оператор % MONTHS_BETWEEN Получение количества месяцев между двумя датами DATEDIFF NVL Замена NULL выражением ISNULL SUBSTR Возврат подстроки из строки SUBSTRING TO_CHAR для даты и времени Преобразование даты и времени в строку CONVERT TO_DATE Преобразование строки в дату и время CONVERT TRANSLATE Замена одного символа по принципу один к одному Выражения с параметром REPLACE или пользовательской функцией TRIM Обрезка начальных или конечных символов LTRIM и RTRIM TRUNC для даты и времени Усечение даты и времени Выражения с параметром CONVERT UNISTR Преобразование кодовых точек Юникода в символы Выражения с NCHAR Функции, хранимые процедуры и последовательности
При переносе хранилища данных из развитой среды, например Oracle, часто приходится переносить не только простые таблицы и представления, но и другие элементы. Что касается функций, хранимых процедур и последовательностей, проверьте, могут ли средства среды Azure заменить их функциональные возможности. Как правило, гораздо эффективнее использовать встроенные средства Azure, чем переписывать код функций Oracle.
На этапе подготовки каталогизируйте объекты, которые необходимо перенести, определите метод их обработки и выделите соответствующие ресурсы в плане миграции.
Для автоматизации переноса функций, хранимых процедур и последовательностей можно использовать средства Microsoft, такие как SSMA для Oracle и Azure Database Migration Services, а также сторонние продукты и сервисы для миграции.
Сторонние продукты и службы могут автоматизировать миграцию элементов, отличных от данных.
В следующих разделах рассматривается перенос функций, хранимых процедур и последовательностей.
Функции
Как и большинство СУБД, Oracle поддерживает системные и пользовательские функции в реализации SQL. При переносе устаревшей платформы базы данных в Azure Synapse, как правило, удается перенести общие системные функции без изменений. У некоторых системных функций может быть немного другой синтаксис, однако необходимые изменения можно автоматизировать.
Системные функций Oracle и произвольные пользовательские функции, у которых нет эквивалента в Azure Synapse, можно переписать на языке целевой среды. Определяемые пользователем функции Oracle кодируются на языках PL/SQL, Java или C, а Azure Synapse использует для реализации определяемых пользователем функций язык Transact-SQL.
Хранимые процедуры
Большинство современных СУБД поддерживают хранимые процедуры в базе данных. Oracle предоставляет для этой цели язык PL/SQL. Как правило, хранимая процедура содержит инструкции SQL и процедурную логику, а также может возвращать данные или состояние.
Azure Synapse реализует хранимые процедуры с помощью T-SQL, поэтому потребуется переписать все перенесенные хранимые процедуры на этом языке.
Последовательности
В Oracle последовательность — это именованный объект базы данных, созданный с помощью CREATE SEQUENCE . Последовательность предоставляет уникальные числовые значения с помощью методов CURRVAL и NEXTVAL . Созданные уникальные числа можно использовать как значения суррогатных ключей для первичных ключей. Azure Synapse не реализует CREATE SEQUENCE , однако последовательности можно реализовать с помощью столбцов IDENTITY или кода SQL, который генерирует следующий порядковый номер в ряде.
Использование EXPLAIN для проверки устаревших SQL
Найдите потенциальные проблемы миграции с помощью реальных запросов из существующих системных журналов запросов.
Если в Azure Synapse переносится аналогичная модель данных с такими же названиями таблиц и столбцов, для тестирования совместимости устаревшего Oracle SQL с Azure Synapse можно поступить следующим образом:
- Зафиксировать некоторые наиболее характерные инструкции SQL из журналов запросов устаревшей системы.
- Добавить к этим запросам инструкцию EXPLAIN в качестве префикса.
- Выполнить инструкции EXPLAIN в Azure Synapse.
Любая несовместимость SQL вызовет ошибку, а сведения об ошибке могут использоваться, чтобы определить масштаб задачи перекодировки. Этот подход не требует загрузки данных в среду Azure, необходимо создать только соответствующие таблицы и представления.
Сводка
Существующие устаревшие установки Oracle обычно реализованы таким образом, что миграция в Azure Synapse является относительно несложной задачей. Обе среды используют SQL для аналитических запросов к большим объемам данных и, как правило, имеют некоторую форму многомерной модели данных. Благодаря этим факторам установки Oracle — хороший кандидат на перенос в Azure Synapse.
Ниже приведены рекомендации по минимизации сложностей при переносе кода SQL из Oracle в Azure Synapse:
- Перенесите существующую модель данных как есть, чтобы свести к минимуму риски, усилия и время миграции, даже если планируется использовать другую модель данных, например хранилище данных.
- Изучите различия между реализацией Oracle SQL и Azure Synapse.
- Используйте метаданные и журналы запросов из существующей реализации Oracle, чтобы оценить значение изменения среды. Спланируйте действия, которые позволят минимизировать различия.
- Автоматизируйте процесс миграции, чтобы свести к минимуму риск, усилия и время миграции. Можно использовать такие средства Microsoft, как Azure Database Migration Services и SSMA.
- Рассмотрите возможность использования специализированных сторонних инструментов и сервисов для оптимизации миграции.
Дальнейшие действия
Дополнительные сведения о средствах Microsoft и других поставщиков см. в следующей статье этой серии: Инструменты для переноса хранилища данных Oracle в Azure Synapse Analytics.
Регулярные выражения, усовершенствующие SQL-предложения
Новая возможность Oracle Database 10g значительно увеличивает способность поиска и манипулирования символьными данными. Эта возможность, регулярные выражения, это транскрипция для описания образца текста. Она давно имеется во многих языках программирования и множестве утилит для UNIX.
Регулярные выражения в Oracle реализованы в виде SQL-функций и оператора выражения WHERE. Тем, кто еще ничего не знает о регулярных выражениях, эта статья может дать общее понятие об этой новой и весьма мощной, но пока кажущейся непонятной, возможности. Читатели, которые уже познакомились с регулярными выражениями, могут пополнить знания о том, как применить эту функциональность в контексте языка Oracle SQL.
Что такое регулярное выражение?
Регулярное выражение содержит один и более символов и/или метасимволов. В самом простом виде регулярное выражение может состоять только из символов, например, регулярное выражение cat. Оно читается как буква c, за которой следует буква a и t, и этому шаблону соответствуют такие строки, как cat, location и catalog. Метасимволы обеспечивают алгоритмы обработки в Oracle символов, из которых состоит регулярное выражение. Когда значение различных метасимволов будет понятным, вы увидите, как удобны регулярные выражения для выделения и замены каких-либо текстовых данных.
Проверка данных, поиск дубликатов, обнаружение лишних пробелов или разбор строки — это некоторые из многих примеров использования регулярных выражений. Их можно применять для проверки формата телефонного номера, zip-кода, email-адресов, номеров социального обеспечения, IP-адресов, имен файлов и директорий и так далее. Кроме того, можно искать комбинации, например, HTML-тегов, чисел, дат, и другое, которые соответствуют какому-либо шаблону в тексте, и заменять их другим набором символов.
Использование регулярных выражений в Oracle Database 10g
Чтобы воспользоваться возможностями регулярных выражений, можно применить функции REGEXP_INSTR, REGEXP_SUBSTR и REGEXP_REPLACE и новый оператор Oracle SQL — REGEXP_LIKE. Вы увидите, как эта новая функциональность поддерживает существующий оператор LIKE и функции INSTR, SUBSTR и REPLACE. Они действительно похожи на существующие оператор и функции, однако теперь предоставляются мощные возможности сопоставления с шаблоном. Искомые данные могут быть простой строкой или текстом большого объема, хранимым в символьном столбце базы данных. Регулярные выражения позволяют искать, заменять и проверять данные способом, о котором ранее и не мечтали, с высокой степенью гибкости.
Примеры регулярных выражений
Перед использованием новой функциональности необходимо понять значение некоторых метасимволов. Период (.) в регулярном выражении соответствует любому символу (за исключением перехода на новую строку). Например, регулярное выражение a.b соответствует строке, содержащей букву a, за которой следует один любой символ (за исключением перехода на новую строку), за которым следует буква b. Строки axb, xaybx и abba подходят, так как содержат этот шаблон. Если требуется точное соответствие трехсимвольной строке, в которой строка начинается с a и заканчивается b, регулярное выражение необходимо привязать. Метасимвол вставки (^) обозначает начало строки, а доллар ($) – конец строки (см. Таблицу 1). Поэтому регулярному выражению ^a.b$ соответствуют строки aab, abb или axb. Чтобы сравнить этот метод со знакомым сопоставлением с шаблоном оператора LIKE, можно использовать такой шаблон как a_b, где подчеркивание (_) – это любой одиночный символ.
По умолчанию отдельный символ или список символов регулярного выражения сопоставляются один раз. Чтобы найти несколько вхождений символа регулярного выражения, применяется квантификатор, называемый также оператором повтора. Если требуется соответствие строке, которая начинается с буквы a и заканчивается буквой b, регулярное выражение выглядит следующим образом: ^a.*b$. Метасимвол * повторяет предыдущее соответствие любому метасимволу (.) ноль, один и более раз. Эквивалентный шаблон оператора LIKE — это a%b, где (%) обозначает ноль, одно и более вхождений любых символов.
В Таблице 2 показан полный список операторов повтора. Заметьте, что в ней содержатся специфичные варианты повтора, которые допускают больше гибкости, чем существующие групповые символы оператора LIKE. Если выражение заключить в скобки, в результате чего образуется подвыражение, то подвыражение может повторяться заданное число раз. Например, регулярному выражению b(an)*a соответствует ba, bana, banana, yourbananasplit, и так далее.
Регулярные выражения Oracle поддерживают символьные классы POSIX (Portable Operating System Interface), которые перечислены в Таблице 3. Это значит, что можно искать совершенно особые типы символов. Представьте написание условия с оператором LIKE, которое ищет только символы, не являющиеся буквами – получающееся выражение WHERE легко становится очень сложным.
Символьный класс POSIX должен входить в список символов, обозначаемый квадратными скобками ([]). Например, регулярное выражение [[:lower:]] соответствует одному символу в нижнем регистре, а [[:lower:]] — пяти последовательным символам в нижнем регистре.
Кроме символьных классов POSIX, в список символов можно включать отдельные символы. Например, регулярное выражение ^ab[cd]ef$ соответствует строкам abcef и abdef. Сопоставляются как c, так и d.
Большинство метасимволов списка понимаются как литеры, за исключением вставки (^) и дефиса (-). Регулярные выражения могут казаться сложными, так как одни и те же метасимволы имеют несколько значений в зависимости от контекста. ^ как раз один из таких метасимволов. Если он — первый символ в списке символов, то означает не вхождение в список. Поэтому, [^[:digit:]] ищет соответствие, состоящее только из любых нецифровых символов, в то время как ^[[:digit:]] ищет соответствие, которое начинается с цифры. Дефис (-) обозначает диапазон; регулярное выражение [a-m] соответствует любым буквам от a до m. Однако он является литерой дефис, если находится в начале списка символов, например [-afg].
Один из предыдущих примеров показывал использование скобок для создания подвыражения; они позволяют ввести альтернативы, разделенные вертикальной чертой (|) – метасимволом альтернативы.
Например, регулярное выражение t(a|e|i)n допускает три возможных альтернативных символа между буквами t и n. Этому шаблону соответствуют слова tan, ten, tin и Pakistan, но не teen, mountain или tune. С другой стороны, регулярное выражение t(a|e|i)n можно описать как список символов, например t[aei]n. Эти метасимволы сгруппированы в Таблице 4. Хотя метасимволов значительно больше, этот краткий список важен для понимания регулярных выражений, используемых в настоящей статье.
Оператор REGEXP_LIKE
Когда в базе данных Oracle встречается оператор REGEXP_LIKE, он знакомит с регулярными выражениями. В таблице 5 показан синтаксис REGEXP_LIKE.
Следующий SQL-запрос с выражением WHERE демонстрирует оператор REGEXP_LIKE, который ищет столбец ZIP со значениями, которые удовлетворяют регулярному выражению [^[:digit:]]. Отбираться будут те строки таблицы ZIPCODE, в которых значение столбца ZIP содержит любой символ, не являющийся цифрой.
SELECT zip FROM zipcode WHERE REGEXP_LIKE(zip, '[^[:digit:]]'); ZIP ----- ab123 123xy 007ab abcxy
Этот пример регулярного выражения состоит только из метасимволов, а точнее, из символьного класса POSIX digit, ограниченного двоеточиями и квадратными скобками. Второй набор скобок (как в [^[:digit:]]) ограничивает список символьных классов. Как пояснялось выше, это необходимо, так как символьные классы POSIX могут использоваться только для формирования списка символов.
Функция REGEXP_INSTR
Эта функция возвращает начальную позицию образца, поэтому она работает примерно так, как уже знакомая функция INSTR. Синтаксис новой функции REGEXP_INSTR показан в Таблице 6. Основное различие между этими двумя функциями заключается в том, что REGEXP_INSTR позволяет указать шаблон вместо конкретной строки поиска; обеспечивая, таким образом, большее многообразие. Следующий пример использует функцию REGEXP_INSTR, которая возвращает начальную позицию пятицифрового zip-кода в строке Joe Smith, 10045 Berry Lane, San Joseph, CA 91234. Если регулярное выражение выглядит как [[:digit:]], то вместо zip-кода возвратится начальная позиция номера дома, так как 10045 – это первое вхождение из пяти последовательных цифр. Поэтому выражение необходимо привязать к концу строки метасимволом $, тогда функция отобразит начальную позицию zip-кода вместо набора цифр, соответствующих номеру дома.
SELECT REGEXP_INSTR('Joe Smith, 10045 Berry Lane, San Joseph, CA 91234', '[[:digit:]]$') AS rx_instr FROM dual; RX_INSTR ---------- 45Более сложные шаблоны
Давайте усложним шаблон zip-кода предыдущего примера, чтобы найти дополнительные четыре цифры. Теперь он может выглядеть так: [[:digit:]](-[[:digit:]])?$. Если исходная строка заканчивается пятицифровым zip-кодом или 5-цифровым + 4 zip-кодом, то надо будет показать начальную позицию шаблона.
SELECT REGEXP_INSTR( 'Joe Smith, 10045 Berry Lane, San Joseph, CA 91234-1234', ' [[:digit:]](-[[:digit:]])?$') AS starts_at FROM dual; STARTS_AT ---------- 44
В этом примере в скобки заключено подвыражение (-[[:digit:]]), которое может повторяться ноль и более раз, что показывает оператор повтора? С другой стороны, если попытаться использовать традиционные SQL-функции для получения того же результата, то формулировка будет сложна даже для знатока SQL. Чтобы лучше объяснить различные компоненты этого примера регулярного выражения, в Таблице 7 представлено описание отдельных литер и метасимволов.
Функция REGEXP_SUBSTR
Функция REGEXP_SUBSTR, очень похожа на функцию SUBSTR и возвращает часть строки. В Таблице 8 показан синтаксис новой функции. В следующем примере возвращается строка, которая соответствует шаблону [^,]*. Регулярное выражение ищет запятую, за которой следует пробел; затем ноль и более символов, не являющихся запятыми, что показывает [^,]*; и затем ищет другую запятую. Шаблон будет выглядеть примерно как строка значений, разделенных запятыми.
SELECT REGEXP_SUBSTR('first field, second field , third field', ', [^,]*,') FROM dual; REGEXP_SUBSTR('FIR ------------------ , second field ,Функция REGEXP_REPLACE
Сначала рассмотрим традиционную SQL-функцию REPLACE, которая заменяет одну строку другой. Предположим, что в тексте имеются дополнительные пробелы, а вам хотелось бы заменить их одним пробелом. В функции REPLACE необходимо перечислить ровно столько пробелов, сколько надо заменить. Однако дополнительные пробелы могут располагаться не только в одном месте. Следующий пример имеет три пробела между Joe и Smith. Параметр функции REPLACE показывает, что два пробела следует заменить одним пробелом. В этом случае результат имеет на один дополнительный пробел меньше, в то время как в исходной строке между Joe и Smith было три пробела.
SELECT REPLACE('Joe Smith',' ', ' ') AS replace FROM dual; REPLACE --------- Joe SmithФункция REGEXP_REPLACE выполняет замены на порядок дальше; она описана в Таблице 9. Следующий запрос заменяет два и более любых пробелов на один пробел. Подвыражение ( ) содержит один пробел, который может повторяться два и более раз, что показывает .
SELECT REGEXP_REPLACE(‘Joe Smith’, ‘( )’, ‘ ‘) AS RX_REPLACE FROM dual; RX_REPLACE ———- Joe Smith
Ссылки
Полезная возможность регулярных выражений – это способность запоминать подвыражение для дальнейшего использования; она называется также ссылочность (описана в Таблице 10). Она позволяет выполнять сложные замены, такие как перемещение образца на новую позицию или нахождение повторяющегося слова или буквы. Соответствующая подвыражению часть сохраняется во временном буфере. Буферы нумеруются слева направо, а доступ к ним осуществляется через \цифра, где цифра, это число от 1 до 9, которое соответствует порядковому номеру подвыражения, обозначенному скобками.
Следующий пример показывает, как имя Ellen Hildi Smith преобразовывается в Smith, Ellen Hildi с помощью ссылок на отдельные подвыражения по номеру.
SELECT REGEXP_REPLACE( 'Ellen Hildi Smith', '(.*) (.*) (.*)', '\3, \1 \2') FROM dual; REGEXP_REPLACE('EL ------------------ Smith, Ellen HildiВ этом SQL-предложении есть три отдельных подвыражения, заключенных в скобки. Каждое отдельное подвыражение содержит метасимвол соответствия любому символу (.), за которым следует метасимвол *, показывающий, что любой символ (за исключением перехода на новую строку) должен появиться ноль и более раз. Каждое подвыражение разделяет пробел, который также должен быть сопоставлен. Скобки обозначают подвыражения для фиксации значений, на которые можно ссылаться через \цифра. Первое подвыражение связывается с \1, второе \2 и так далее. Эти ссылки используются в последнем параметре этой функции (\3, \1 \2), которая возвращает измененную подстроку, преобразовав ее в требуемый формат (включая запятую и пробелы). В Таблице 11 подробно описываются отдельные элементы этого регулярного выражения.
Ссылки полезны для замены, форматирования и нахождения подстроки, и могут применяться для поиска расположенных рядом значений. Следующий пример показывает использование функции REGEXP_SUBSTR для поиска дубликатов символьно-цифровых значений, разделенных пробелом. Полученный результат показывает слова, которые продублированы.
SELECT REGEXP_SUBSTR( 'The final test is is the implementation', '([[:alnum:]]+)([[:space:]]+)\1') AS substr FROM dual; SUBSTR ------ is is
Дополнительный параметр сопоставления
Вы, возможно, заметили, что оператор и функции регулярного выражения могут содержать дополнительный параметр сопоставления. Этот параметр управляет учетом регистра, переходом на новую строку и многострочными вхождениями повторов.
Практические приложения регулярных выражений
Регулярные выражения используются не только в запросах, но также в любом месте, где допускаются SQL-операторы и функции, например в PL/SQL. Можно написать триггеры, в которых регулярные выражения полезно использовать для проверки, генерации или выделения значений.
Следующий пример показывает, как оператор REGEXP_LIKE можно применять в check-ограничении на столбец для контроля данных. Он проверяет корректность формата номера социального обеспечения при вставке или изменении записи. Для такого ограничения столбца допустим номер социального обеспечения в формате 123-45-6789 или 123456789. Корректные данные должны начинаться с трех цифр, за которыми следует дефис, две или более цифр, дефис и, наконец, другие четыре цифры. Альтернативное выражение допускает только девять последовательных цифр. Варианты разделяются вертикальной чертой (|).
ALTER TABLE students ADD CONSTRAINT stud_ssn_ck CHECK (REGEXP_LIKE(ssn, '^([[:digit:]]-[[:digit:]]-[[:digit:]]|[[:digit:]])$'));
Символы перед или после не допускаются, что показывают ^ и $. Необходимо убедиться, что регулярное выражение не разбито на несколько строк и не содержит лишних пробелов, если только не требуется, чтобы они были частью шаблона и поэтому сопоставлялись. В Таблице 12 объясняются отдельные элементы этого примера регулярного выражения.
Сравнение регулярных выражений с существующей функциональностью
Регулярные выражения имеют некоторые преимущества перед обычным оператором LIKE и функциями INSTR, SUBSTR и REPLACE. Эти традиционные SQL-функции не имеют возможности сопоставления с шаблоном. Только оператор LIKE может выполнять символьное сопоставление с помощью символов группировки % и _, однако LIKE не поддерживает повторы выражения, сложное чередование, диапазоны символов, списки символов, символьные классы POSIX, и др. А новые функции с регулярными выражениями позволяют найти еще и дубликаты, и выполнить перестановку. Примеры, показанные в этой статье, позволяют кратко заглянуть в мир регулярных выражений и понять, как применять их в приложениях.
Полезное добавление к инструментарию
Регулярные выражения очень полезны, так как помогают решить сложные задачи. Некоторые возможности регулярных выражений трудно воспроизвести с помощью традиционных SQL-функций. Когда будет изучено создание основных конструкций этого несколько сложного языка, регулярные выражения станут необходимой частью инструмента в контексте не только SQL, но и других языков программирования. Хотя тестирование и допущение ошибок иногда необходимо для получения индивидуальных навыков написания шаблонов, элегантность и мощность регулярных выражений бесспорна.
Таблица 1: Метасимволы привязки
Метасимвол Описание ^ Привязать выражение к началу строки $ Привязать выражение к концу строки Таблица 2: Квантификаторы и операторы повтора
Квантификатор Описание * Встречается 0 и более раз ? Встречается 0 или 1 раз + Встречается 1 и более раз Встречается ровно m раз Встречается по крайней мере m раз Встречается по крайней мере m раз, но не более n раз Таблица 3: Предопределенные символьные классы POSIX
Таблица 4: Альтернативное сопоставление и группировка выражений
Метасимвол Описание | Альтернатива Разделяет альтернативные варианты, часто используется с оператором группировки () ( ) Группа Группирует подвыражения для альтернативы, квантификатора или ссылочности (см. раздел «Ссылки») [char] Список символов Обозначает список символов; большинство метасимволов в списке символов представляют собой литеры, за исключением символьных классов и метасимволов ^ и — Таблица 5: Оператор REGEXP_LIKE
Синтаксис Описание REGEXP_LIKE(исходная_строка, шаблон[, параметр_сопоставления]) “исходная_строка” поддерживает символьные типы данных (CHAR, VARCHAR2, CLOB, NCHAR, NVARCHAR2 и NCLOB, но не LONG). Параметр “шаблон” — это другое название регулярного выражения. “параметр_сопоставления” позволяет использовать дополнительные параметры, такие как символ перехода на новую строку, многострочное форматирование и обеспечение управления учетом регистра. Таблица 6: Функция REGEXP_INSTR
Синтаксис Описание REGEXP_INSTR(исходная_строка, шаблон
[, начальная_позиция
[, вхождение
[, опция_возврата
[, параметр_сопоставления]]]])Эта функция ищет по шаблону и возвращает первую позицию. Дополнительно можно указать параметр “начальная_позиция”, с которой должен начинаться поиск. Параметр “вхождение” по умолчанию имеет значение 1, если пользователь не укажет поиск последовательных вхождений. Значение по умолчанию для параметра “опция_возврата” — это 0, тогда возвратится начальная позиция шаблона; при значении 1 возвращается позиция символа, следующего за шаблоном. Таблица 7: Описание выражения для 5-цифрового + 4 Zip-кода
Синтаксис Описание Пробел, который должен быть сопоставлен [:digit:] Числовой класс POSIX ] Конец списка символов Повторять список символов ровно пять раз ( Начало подвыражения — Литера дефис, так как он не является метасимволом диапазона внутри списка символов [ Начало списка символов [:digit:] Класс POSIX [:digit:] [ Начало списка символов ] Конец списка символов Повторять список символов ровно четыре раза ) Закрывающая скобка – конец подвыражения ? Квантификатор ? относится к групповому подвыражению 0 или 1 раз, в результате чего 4-цифровой код становится дополнительным $ Метасимвол привязки, чтобы показать конец строки Таблица 8: Функция REGEXP_SUBSTR
Синтаксис Описание REGEXP_SUBSTR(исходная_строка, шаблон
[, позиция [, вхождение
[,параметр_сопоставления]]])Функция REGEXP_SUBSTR возвращает подстроку, которая соответствует шаблону. Таблица 9: Функция REGEXP_REPLACE
Синтаксис Описание REGEXP_REPLACE(исходная_строка, шаблон
[, строка_замены [, позиция
[,вхождение, [параметр_сопоставления]]]])Эта функция заменяет подстроку, соответствующую шаблону на заданную “строку_замены”, используя сложные операции поиска-и-замены. Таблица 10: Метасимвол ссылки
Метасимвол Описание \digit Обратная косая черта За ней следует цифра от 1 до 9, обратная косая черта связана с предыдущим сопоставлением с соответствующим номером заключенного в скобки подвыражения. Таблица 11: Описание регулярного выражения замены-по-шаблону
Таблица 12: Описание регулярного выражения для номера социального обеспечения
Алиса Ришет ( ar280@yahoo.com ) работает в Database Application Development и Design track в Columbia University’s Computer Technology and Application Program. Она автор Oracle SQL Interactive Workbook 2nd edition (Prentice Hall, 2002) и готовящейся в публикации Oracle SQL by Example (Prentice Hall, 2003). Ришет — архитектор баз данных, DBA и руководитель проекта с 15-летним стажем для Fortune 100 компаний и работает с Oracle, начиная с 5-ой версии.