Машинное обучение в поиске Яндекса или Как устроен Матрикснет
Анна-Вероника Дорогуш, руководитель группы машинного обучения Яндекса, об основных алгоритмах машинного обучения, которые используются в поиске Яндекса, и о существующей инфраструктуре их использования. Пользователь приходит на сайт поисковой системы, задает свой запрос и задача поисковой системы состоит в том, чтобы выдать по запросу топ самых релевантных документов. Документов, подходящих под данный запрос, в индексе – миллиарды, и даже после первых фильтраций их – миллионы. Эти миллионы нужно как-то упорядочить. На помощь в составлении формулы ранжирования приходит машинное обучение, а именно – Матрикснет, собственный алгоритм градиентного бустинга Яндекса. Матрикснет – это градиентный бустинг на деревьях решений, который поддерживает все основные режимы: классификации, мультиклассификации, регрессии, ранжирования и др. Есть еще более сложные режимы – комбинации вышеперечисленных. Наш отдел разрабатывает новые режимы для нужд смежных отделов, а также внутренние пользователи Яндекса сейчас тоже могут добавлять свои собственные режимы. Матрикснет умеет работать с пропущенными значениями – если значение какого-то фактора не указано, это не будет проблемой. Кроме того, обучение Матрикснета может быть запущено на кластере — это распределенный алгоритм. Это важно потому, что в поиске обучающие выборки сейчас такого размера, что в оперативную память одного сервера они просто не помещаются, вот почему нужно делать распределенное обучение.
Применения Матрикснета в Яндексе
Матрикснет в Яндексе применяется повсеместно. Во-первых, в поиске. Матрикснет изначально писался именно для поиска. Во-вторых, он используется в рекламе для того, чтобы показывать пользователям самые интересные для них объявления, предсказывая количество кликов по рекламе. В-третьих, прогноз погоды в Яндексе строится по формуле Матрикснета. Также алгоритм применяется во внешних проектах Яндекса – YDF, в системе рекомендаций Яндекс.Дзен, в обнаружении ботов, разрешении омонимии, сегментации пользователей и многих других.
Особенности Матрикснета

Сейчас в открытом доступе есть сразу несколько алгоритмов градиентного бустинга, поэтому я расскажу, чем от них отличается Матрикснет. Важной его особенностью является то, что для него почти не нужен подбор параметров. Почему? Когда писался Матрикснет, его тестировали на наборе разных обучающих выборок (пулов) так, чтобы он на всех давал хорошее качество, поэтому на новых дата-сетах мы тоже получаем хорошее качество. Матрикснет легко использовать не только потому, что почти не нужен подбор параметров, но еще и потому, что в Яндексе есть инфраструктура, позволяющая запускать обучение буквально в один клик (об этом подробнее ниже). Матрикснет выигрывает по качеству у других алгоритмов градиентного бустинга на деревьях решений в режиме регрессии. У Матрикснета сильно оптимизированное обучение. Это важно для всех задач Яндекса, но в большей степени для поиска. Хотя у нас и большие обучающие выборки, мы не можем себе позволить, чтобы формула обучалась месяц, потому что от этого будет страдать качество. Поэтому применяются всякие оптимизации, как алгоритмические, так и низкоуровневые, а также оптимизация нагрузки на сеть. Применение формулы Матрикснета тоже сильно заоптимизировано (за 1 сек. в одном потоке формула может быть применена к 100000 документов).
Градиентный бустинг на деревьях решений
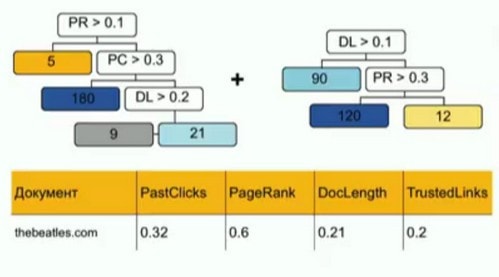
Деревья решений – это такая структура данных — бинарное дерево – где во всех узлах данных, кроме листовых, находится разбиение по какому-то фактору или числу, а в листовых вершинах находятся числа. Вот таким образом дерево можно применить к документу: Градиентный бустинг – это сумма простых моделей (в данном случае деревьев решений), каждая из которых улучшает результат предыдущей комбинации. Матрикснет – это не произвольные деревья решений, а так называемые «oblivious деревья решений», где на каждом уровне находится разбиение по одному и тому же признаку и одному и тому же числу. У такого способа построения дерева есть набор особенностей: • получение очень простых моделей, устойчивых к переобучению • разбиение пространства при помощи гиперплоскости, а значит, что для вычисления значения в листе, нужно вычислить значение всех разбиений, а значит, не важно в каком порядке это делать • регуляризация. Нужно гарантировать отсутствие листьев, в которых почти не бывает объектов, поэтому приходится придумывать различные регуляризации, чтобы штрафовать такие ситуации
Обучение на кластере
Есть несколько способов, как градиентные бустинги на деревьях решений параллелят на несколько серверов: 1. по признакам 2. по документам Если мы параллелим обучение по признакам (когда различные признаки лежат на нескольких серверах), то тогда количество информации, которую нужно будет пересылать по сети, будет прямо пропорционально числу документов. Так как число документов у нас очень большое и постоянно растет, ы не можем себе такое позволить и параллелим обучение по документам. Узким местом в обучении всех градиентных бустингов на деревьях решений является выбор структуры дерева, т.е. набор признаков, из которых будет состоять наше следующее дерево. Выбор делается из двух способов: 1. master-slave режим, когда есть один ведущий узел и набор слейвов, каждый из которых считает какие-то статистики по признакам и отправляет их мастеру, который их агрегирует и выбирает лучший признак 2. all radius режим, где нет выделенного мастера, а каждый узел считает все статистики и агрегирует у себя сам У каждого из этих подходов есть серьезные недостатки. В режиме master-slave мастер становится узким местом по сети, в режиме all radius идет очень много трафика, потому что каждый узел должен получить много информации. Например, XGBoost работает в режиме all radius, поэтому не так хорошо параллелится. В Матрикснете обе эти проблемы решены следующим способом: при выборе очередного дерева, для каждого признака выбирается случайный узел, который объявляется виртуальным мастером, и все остальные слейвы общаются уже с этим узлом. Он агрегирует нужную информацию, обсчитывает этот признак и отправляет мастеру результат. Мы также стараемся минимизировать трафик разными способами. Например, при выборе лучшего разбиения, мы на каждом слейве выбираем набор кандидатов для лучших признаков, и виртуальным мастерам скидываем информацию только по нескольким признакам. Не вообще по всем имеющимся, а только по топу самых лучших.
Матрикснет в ранжировании
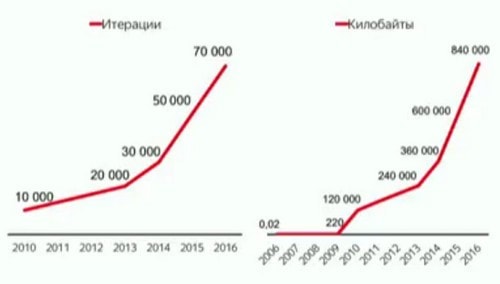
График того, как со временем менялся размер формулы ранжирования, где число итераций – это число деревьев в модели, а килобайты – это размер модели. Как видим, нужно постоянно ускорять как обучение, так и применение модели, чтобы соответствовать вот такому росту. Как же применяется машинное обучение для поиска? Для начала нужно собрать обучающую выборку, в которой будет набор пар (документ, запрос). Каждой такой паре асессоры ставят оценку – насколько этот документ подходит к запросу. Кроме того, в этой строке – документ, запрос, оценка – еще будут признаки (запросные, документные, документно-запросные). Если признак запросный, то мы его просто продублируем для всех документов запроса. По полученной обучающей выборке и будет обучаться модель. Режимы обучения, используемые в поиске Яндекса: • Регрессия (поточечный режим): Отличный = 1, Хороший = 0.8, Плохой = 0 => Минимизация MSE • Попарный режим – генерируем набор пар документов с разными оценками. Формула оптимизирует правильное ранжирование внутри пар. • Оптимизация ранжирующей функции nDCG (не гладкая, не получится сделать шаг по градиенту). Дифференцируемое приближение функции.
Задачи в Матрикснете
• Автогенерация фичей, умный выбор фичей • Ускорение обучения (CPU, GPU) • Оптимизации для разреженных данных • Обучение на кластере с неравномерным распределением ресурсов • Новые регуляризации и функции ошибок • Инструменты для анализа обученной формулы • Предсказание времени обучения и требуемых ресурсов Что нужно сделать исследователю в Яндексе, если ему нужно обучить формулу? Нужно решить ряд очень сложных и первоочередных задач: 1. Найти последнюю версию алгоритма 2. Собрать данные для обучения в нужном формате 3. Найти себе вычислительные ресурсы (кластер) 4. Запустить распределенное обучение В Яндексе есть специальная инфраструктура, которая решает все эти задачи и делает жизнь исследователей лучше – это Нирвана.
Принципы Нирваны

Нирвана – это платформа для запуска произвольных процессов. Основной ее особенностью является то, что все процессы в ней конфигурируются в виде графов. Если взять, например, обучение формулы Матрикснета, то пользователь создает граф, оперируя определенными блоками, связывая их между собой, и запускает. Каждый блок – это операция, принимающая и генерирующая какие-то данные, через которые и осуществляется между ними связь. Пользователь запускает граф с обучением и вся история его запуска сохраняется, после этого он может посмотреть любой свой предыдущий граф, склонировать его, запустить еще раз и гарантированно получить такой же результат. В Нирване специально уделено отдельное внимание воспроизводимости. Любые эксперименты с машинным обучением в Яндексе – воспроизводимы. Кроме того, Нирвана позволяет посмотреть историю экспериментов любых других пользователей в Яндексе, склонировать их эксперимент, как-то его изменить и перезапустить. Например, можно взять обучение нашей поисковой продакш-формулы, посмотреть этот граф, склонировать, изменить там какой-нибудь параметр и получить свою поисковую формулу, которая может быть лучше существующей. В Нирване реализовано множество операций, сейчас их порядка 10 тысяч. Реализованы различные утилиты, есть удобный поиск по операциями. Если нужная операция не находится, то есть возможность создания своей операции. Нирвана поддерживает так называемое визуальное программирование, что значительно облегчает создание функций и композитных операций. И разумеется, в Нирване реализованы наиболее часто используемые в Яндексе алгоритмы машинного обучения – и Матрикснет, и обучение нейросетей. В Нирване очень просто обучить свою нейросеть, ничего сложного в этом нет, и даже не требуется никаких дополнительных специальных знаний. Нирвана – довольно новая система, ее альфа-версия была запущена в 2015 году. Но у нее уже очень много пользователей – на сегодняшний день их более 2 тыс. (треть от всего Яндека), в неделю Нирваной активно пользуется около 500 человек, которые запускают по 50 тыс. графов еженедельно.
Исследование точности метода градиентного бустинга со случайными поворотами Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Китов Виктор Владимирович
В статье рассматривается метод градиентного бустинга с осуществлением случайных поворотов признакового пространства на каждом шаге обучения алгоритма. Исследуется качество данного метода на различных модельных задачах бинарной классификации . Полученные результаты анализируются и даются рекомендации по применению указанного метода.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Китов Виктор Владимирович
Статистическая классификация иммуносигнатур для задач ранней диагностики заболеваний при значительном сокращении размерности признакового пространства
Система автоматической категоризации графического контента
Анализ и предсказание загруженности банкоматов на основе их расположения
Новый метод восстановления пропущенных значений в наборе данных на примере иммуносигнатур
Прогнозирование вероятности дефолта корпоративных заемщиков
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
ACCURACY ANALYSIS OF THE GRADIENT BOOSTING METHOD WITH RANDOM ROTATIONS
Gradient boosting method with random rotations is considered, where before training each base learner random rotation is applied to the feature space. The accuracy metric of the given method is estimated for a broad range of generated problems of binary classification . Obtained results are evaluated and recommendations given for application of this method.
Текст научной работы на тему «Исследование точности метода градиентного бустинга со случайными поворотами»
ИССЛЕДОВАНИЕ ТОЧНОСТИ МЕТОДА ГРАДИЕНТНОГО БУСТИНГА СО СЛУЧАЙНыМИ ПОВОРОТАМИ
Виктор Владимирович Китов,
к.ф.-м. н., математик 1-й категории Московского государственного университета им. Ломоносова, доцент научно-исследовательского университета «Высшая школа экономики», доцент Российского экономического университета им. Г.В.Плеханова. Эл. почта: v.v.kitov@yandex.ru
В статье рассматривается метод градиентного бустинга с осуществлением случайных поворотов признакового пространства на каждом шаге обучения алгоритма. Исследуется качество данного метода на различных модельных задачах бинарной классификации. Полученные результаты анализируются и даются рекомендации по применению указанного метода.
Ключевые слова: прогнозирование, классификация, градиентный бус-тинг, случайные повороты.
PhD in Mathematics, mathematician of Moscow State University, docent at National Research University «Higher School of Economics», docent at Plekhanov Russian University of Economics. E-mail: v.v.kitov@yandex.ru
accuracy analysis of the
GRADIENT BooSTING METHoD
with random rotations
Gradient boosting method with random rotations is considered, where before training each base learner random rotation is applied to the feature space. The accuracy metric of the given method is estimated for a broad range of generated problems of binary classification. Obtained results are evaluated and recommendations given for application of this method.
Keywords: forecasting, classification, gradient boosting, random rotations.
С развитием вычислительных мощностей и запоминающих устройств в последние десятилетия значительно повысились возможности по сбору, обработке, анализу и прогнозированию данных в самых различных предметных областях, таких как торговля, реклама, сотовая связь, предоставление интернет-услуг, и многих других. Наука, занимающаяся алгоритмами анализа и прогнозирования данных в полуавтоматическом режиме, когда большинство параметров моделей подбираются по располагаемым данным, а не вручную, называется машинным обучением.
Одной из важнейших задач анализа данных в машинном обучении является задача прогнозирования. Существует множество прогнозирующих алгоритмов, накладывающих свои предположения о данных, таких как метод ближайших соседей, метод опорных векторов, линейная регрессия, логистическая регрессия, решающие деревья, нейросети и др. — см [1]. Однако, поскольку прогнозируемые данные, скорее всего, имеют более сложные свойства, чем те предположения, которые делаются в рассматриваемых методах, то более выигрышной, с точки зрения точности, стратегией является прогнозирование не единственной моделью, а набором моделей, объединенных в композицию (другое название — ансамбль моделей), см. [2, 3]. В этом случае к данным применяется сразу несколько прогнозирующих моделей, называемых базовыми моделями, а потом результат определяется в виде агрегирования полученных прогнозов — в простейшем случае, в виде линейной комбинации. Одним из наиболее популярных ансамблевых методов прогнозирования является градиентный бустинг. По данным [4], реализация xgBoost данного метода использовалась в большинстве прогнозирующих алгоритмов, победивших в соревнованиях по машинному обучению на сайте kaggle.com в 2015 году.
Ключом к успешному применению ансамблевых методов прогнозирования является разнообразие (diversity) базовых моделей, на базе которых строится финальный прогноз. Очевидно, что если усреднять по идентичным моделям, то выигрыша по сравнению с применением одной базовой модели не будет. И наоборот, чем разнообразнее базовые модели, тем потенциально больше у них возможностей исправлять ошибки друг друга и уточнять финальный прогноз. В работе [5] предложена идея генерации случайных поворотов, которые потом применяются к признакам прогнозируемых объектов перед обучением базовых моделей, в качестве которых выступают решающие деревья. Высказана гипотеза, что за счет различных поворотов базовые алгоритмы становятся более разнообразными, что в результате повышает точность полученной композиции моделей. Данная гипотеза подтверждена для случаев, когда случайные повороты применяются к ансамблевым алгоритмам случайного леса (random forest), и особо случайных деревьев (extra-random trees). Реализация случайных поворотов в алгоритме бустинга менее тривиальна алгоритмически, поскольку требует интеграции поворотов внутри алгоритма, поэтому в указанной статье не рассматривалась (рассматривался упрощенный алгоритм). Тем не менее, интересен вопрос, насколько оправдан данный подход для алгоритма бустинга, который изучается в последующих разделах данной работы.
В разделе 2 дается описание алгоритма градиентного бустинга с поворотами. В разделе 3 дается описание эксперимента по проверке точности метода на различных модельных данных, и обсуждаются результаты. В разделе 4 дается заключение и варианты дальнейших исследований.
2. Градиентный бустинг со случайными поворотами
Для расширения класса функций, моделируемых ансамблями деревьев, в работе [5] предложен подход, согласно которому перед каждой настройкой базового алгоритма в ансамбле делается случайный поворот признакового пространства.
В алгоритме бустинга сначала настраивается базовая модель F1(x), затем настраивается F2(x) так, чтобы максимально исправить ошибки первой модели, затем F3(x) так, чтобы максимально исправить ошибки первых двух моделей и т.д. Результирующий прогноз основывается на суммарном прогнозе F1(x) + F2(x) + . + FM(x), см. рис. 1. В задаче бинарной классификации, рассматриваемой в данной статье, прогнозируемый класс у е будет выражаться формулой:
У = ^ (X) + (X) + . + Рм (Х)\
где sign(u) — функция, возвращающая знак аргумента и.
Рис. 1. Обычная схема бустинга
В методе бустинга со случайными поворотами перед настройкой каждой модели производится случайный поворот признакового пространства. Перед настройкой модели F1(x) производится случайный поворот х ^ R1(x), перед настройкой модели F2(x) производится случайный поворот х ^ R2(x) и т.д., см. схему метода на рис. 2. Поворот на шаге i осуществляется некоторой случайно сгенерированной матрицей поворота Rh обзор методов генерирования таких матриц см. в [6]. После настройки модели последовательность случайных поворотов R1, R2, . Rm запоминается, и на этапах применения модели (прогнозирования) используется та же самая последовательность поворотов.
В качестве базовых моделей в градиентном бустинге обычно используются решающие деревья. Решающие деревья представимы в виде деревьев, где каждому листу сопоставлен прогноз, а каждому внутреннему узлу — проверка усло-
Рис. 2. Схема бустинга со случайными поворотами
Градиентный бустинг с поворотами является более гибким методом. Каждое дерево композиции будет по-прежнему выдавать кусочно-постоянный прогноз, где области постоянства будут прямоугольники в пространстве признаков. Но оси прямоугольников будут параллельны не осям исходного признакового
пространства, а осям повернутого признакового пространства на величину случайного поворота. Это расширяет круг моделируемых функций, в частности, появляется возможность разделять признаковое пространство наклонными линиями за меньшее число разбиений, чем в случае обычного градиентного бустинга над деревьями. На рис. 4 показано применение градиентного бустинга с поворотами к той же обучающей выборке объектов, что и на рис. 3.
На рис. 4 видно, что разделяющая граница между классами уже не является кусочно-линейной с линиями, параллельными осям координат -здесь уже допустимы наклонные разделения. С одной стороны, это позволяет более гибко и более экономично (меньшим числом разбиений) описывать классы объектов, что может повысить точность прогнозирования. А с другой стороны, за счет большей гибкости, это может внести большую степень переобученности модели на обучающую выборку, что в итоге понизит качество прогнозирования новых данных — см. [3]. Какой из данных факторов окажется
15 10 0.5 0.0 -0.5 -1.0
15 10 0.5 0.0 -0.5 -1.0
Рис. 4. Разделение на два класса методом бустинга с поворотами
Рис. 3. Разделение на два класса методом обычного бустинга
более значимым, будет ясно из последующих экспериментов.
3. Эксперимент на модельных данных
Изучим вопрос, как соотносится точность обычного градиентного бустинга и градиентного бустинга с поворотами на искусственно сгенерированных данных, про которые заранее известна зависимость между признаками и классами. Будем рассматривать случай независимых признаков, распределенных равномерно на интервале [-1,1] каждый. Класс будет определяться условием, попадает или не попадает объект х = (хь . хБ) в определенную область. Определим функцию
Г1, если условие и выполнено. Дм] = Г *
I -1, если условие и не выполнено.
Будут рассматриваться следующие типы разделения объектов на классы:
1) Классы разделены линейно:
у = Дх! + . + х^ > 0], показано на рис 5а.
2) Объекты одного класса лежат внутри многоугольника:
показано на рис 56.
3) Объекты одного класса лежат внутри параболы:
Яндекс запустит новый поиск 22 августа
26 июля 2017 года «Яндекс» изменил свой слоган с «Найдется все» на «Поиск №1 в России» в рамках новой рекламной кампании, приуроченной, очевидно, к запуску нового поиска, который намечен на 22 августа 2017 года.

Презентация, посвященная запуску нового алгоритма поиска, будет проходить в Московском планетарии. На мероприятии представители Яндекса расскажут посетителям о новых технологиях, используемых в поиске, и покажут что происходит «по ту сторону» поиска.
От используемого в данный момент Матрикснета Яндекс переходит к категориальному бустингу (CatBoost), так как данный алгоритм способен обрабатывать разнородные данные, и делать это качественнее и быстрее Матрикснета. Матрикснет «нес службу» в Яндексе с 2009 года.
Немного теории из официальных источников
В основе Матрикснета лежит механизм градиентного бустинга. Его особенность — в том, что он хорошо подходит для работы с разнородными данными. Такими данными, скажем, могут быть температура, влажность, сила ветра, снимки со спутников и сводки с наземных радаров — по ним можно предсказать, какая будет погода. Кроме того, градиентный бустинг даёт точные результаты даже там, где данных относительно мало. Этим он отличается от нейронных сетей, которым для обучения требуется огромный массив однородной информации.
Само собой, у моделей на основе градиентного бустинга есть и недостатки. Все данные, на которых учится модель, должны быть представлены в числовом виде. Иногда это не так-то просто — например, когда мы имеем дело с типами облаков, жанрами музыки, породами собак и прочими вещами, которые понятны человеку, но которые трудно объяснить машине.
Сегодня Яндекс представляет преемника Матрикснета — новый метод машинного обучения CatBoost. В нём также используется градиентный бустинг, но CatBoost, во-первых, превосходит Матрикснет по точности предсказаний, а во-вторых, способен учитывать так называемые категориальные признаки — то есть признаки, которые принимают одно из конечного количества значений. Так, облака могут быть кучевыми, перистыми, перисто-кучевыми и так далее. Жанры музыки включают рок, рэп, классику, альтернативу, метал. Пудель, овчарка, спаниель и эрдельтерьер — породы собак. Подобные данные больше не нужно выражать в числах: CatBoost воспринимает их в исходном виде. Обученные с его помощью модели позволяют использовать всё многообразие доступных данных, не тратя время на их перевод в числовую форму.
Яндекс, подробнее о новой технологии на официальном сайте
Яндекс уже опробовал CatBoost в таких сервисах, как:
- Дзен, для ранжирования ленты рекомендаций,
- Яндекс.Погода — для расчета прогноза на основе технологии Метеум.
Видео-презентация
Презентация в Московском планетарии 22 августа
Если вы хотите попасть на презентацию Яндекса в Московском планетарии — у вас есть шанс! Яндекс разыгрывает 100 приглашений среди тех, кто заполнит данную форму — https://yandex.ru/promo/events/newsearch

Рецензент статьи:
Голомолзин Денис
Управляющий партнер компании «Альтера». В прошлом — оптимизатор, ведущий специалист SEO-команды, руководитель отдела продвижения, консультант-евангелист компании.

Вы дочитали статью! Отличная работа!
- В некоторых нюансах продвижения сайтов сложно разобраться без опыта. Вы можете доверить продвижение вашего сайта нам. Отправьте заявку и мы изучим ваш сайт и предложим эффективную стратегию продвижения вашего бизнеса в сети.
- Подпишитесь на нашу рассылку — ежемесячно мы публикуем статьи про SEO-продвижение, онлайн-маркетинг, контекстную рекламу, новости отрасли и многое другое.
- Понравилась статья? Поделитесь ссылкой на статью в социальных сетях — возможно, статья окажется полезной для ваших друзей и коллег.
CatBoost

CatBoost – алгоритм, разработанный Yandex это это гармоничное сочетание инноваций и эффективности, особенно когда дело доходит до работы с категориальными данными.
Первые шаги CatBoost были сделаны в 2017 году, когда мир уже знал об XGBoost и LightGBM. В чем же заключается уникальность CatBoost? Его разработка была направлена на решение специфических проблем, связанных с категориальными данными – той самой головной боли многих специалистов в области машинного обучения. С тех пор CatBoost прошёл долгий путь развития и совершенствования, став не только эффективным инструментом, но и частью больших исследовательских проектов в различных сферах.
CatBoost выделяется на фоне других алгоритмов градиентного бустинга благодаря ряду ключевых особенностей:
- Обработка категориальных данных «из коробки»: В отличие от своих предшественников, CatBoost не требует предварительной обработки категориальных данных, что значительно упрощает жизнь аналитиков.
- Минимизация переобучения: Алгоритмы CatBoost разработаны таким образом, чтобы снизить риск переобучения, что часто является проблемой в градиентном бустинге.
- Высокая скорость и эффективность: Несмотря на свою сложность, CatBoost демонстрирует выдающуюся скорость обучения и предсказания, что делает его идеальным выбором для работы с большими наборами данных.
Принципы градиентного бустинга
Бустинг – это ансамблевый метод машинного обучения, целью которого является объединение нескольких слабых моделей предсказания для создания одной сильной. Слабая модель – это такая, которая выполняет предсказания немного лучше, чем наугад, в то время как сильная модель обладает высокой предсказательной способностью. Цель бустинга – улучшить точность предсказаний.
Бустинг работает путём последовательного добавления моделей в ансамбль. Каждая следующая модель строится таким образом, чтобы исправлять ошибки, сделанные предыдущими моделями. Это достигается путём фокусировки на наиболее проблемных данных, которые были неверно классифицированы или предсказаны ранее.
Одной из основных фич бустинга является динамическое взвешивание обучающих данных. После каждого этапа обучения модели в ансамбле, данные, на которых были допущены ошибки, получают больший вес. Это означает, что последующие модели уделяют больше внимания именно этим трудным случаям.
Когда используются решающие деревья, каждое последующее дерево строится с учетом ошибок, сделанных предыдущими деревьями. Новые деревья учатся на ошибках, улучшая общую точность ансамбля.
Несмотря на свою мощь, бустинг может быть склонен к переобучению, особенно если в ансамбле слишком много моделей или они слишком сложные. Для контроля переобучения к примеру ранняя остановка (early stopping).
Принцип построения ансамбля
Ансамбль в градиентном бустинге обычно состоит из последовательности слабых предсказательных моделей. Чаще всего используются решающие деревья из-за их способности моделировать нелинейные зависимости и взаимодействия между признаками. Каждое новое дерево в ансамбле строится так, чтобы уменьшить оставшуюся ошибку предыдущих деревьев.
В градиентном бустинге каждая следующая модель обучается с учетом ошибок, допущенных всеми предыдущими моделями в ансамбле. Это достигается путем фокусировки на самых трудных для предсказания случаях, которые были неправильно классифицированы или предсказаны ранее.
Суть метода заключается в том, что веса для каждого наблюдения в обучающем наборе данных корректируются на каждом шаге. Наблюдения, которые были неправильно предсказаны предыдущей моделью, получают больший вес, тем самым увеличивая вероятность их правильного предсказания последующими моделями.
Градиентный спуск
Градиентный спуск — это итеративный алгоритм оптимизации, используемый для минимизации функции, чаще всего функции потерь в контексте машинного обучения. Он работает путем нахождения направления, в котором функция потерь уменьшается наиболее быстро, и делает шаги в этом направлении для постепенного уменьшения значения функции потерь.
Градиент функции — это вектор, состоящий из частных производных, который указывает направление наискорейшего роста функции. В контексте оптимизации, мы интересуемся направлением наискорейшего убывания, то есть движемся в противоположном направлении градиента. Частные производные вычисляются для каждого параметра модели (например, весов в нейронной сети).
На каждой итерации алгоритма параметры модели обновляются в направлении, противоположном градиенту функции потерь. Размер шага, который делает алгоритм в этом направлении, определяется скоростью обучения (learning rate). Оптимальная скорость обучения — ключевой параметр, поскольку слишком большой шаг может привести к пропуску минимума, а слишком маленький делает процесс оптимизации медленным.
Формула для обновления параметра θ на каждой итерации выглядит следующим образом:
где η — скорость обучения, а ∇θJ(θ) — градиент функции потерь J по параметру θ.
Виды градиентного спуска
- Пакетный градиентный спуск (Batch Gradient Descent): вычисляет градиент функции потерь по всему обучающему набору данных. Это точно, но может быть очень медленным на больших наборах данных.
- Стохастический градиентный спуск (Stochastic Gradient Descent, SGD): вычисляет градиент для каждого обучающего примера по отдельности и обновляет параметры. Это быстро, но изменения параметров могут быть очень «шумными».
- Мини-пакетный градиентный спуск (Mini-batch Gradient Descent): компромисс между двумя предыдущими методами, вычисляет градиенты на небольших группах обучающих примеров.
Сравнительный анализ с другими алгоритмами бустинга (например, XGBoost, LightGBM)
Основное предназначение
Оптимизирован для работы с категориальными данными
Всецело фокусируется на производительности и эффективности
Ориентирован на скорость и эффективность при работе с большими объемами данных
Обработка категориальных данных
Встроенная обработка без предварительного кодирования
Требует предварительного кодирования (например, one-hot encoding)
Требует предварительного кодирования, но обладает оптимизациями для категориальных признаков
Скорость обучения
Высокая, с поддержкой GPU
Высокая, с поддержкой GPU
Очень высокая, эффективно обрабатывает большие наборы данных
Предотвращение переобучения
Использует ordered boosting и разнообразные стратегии регуляризации
Поддерживает L1 и L2 регуляризацию
Использует механизмы, такие как exclusive feature bundling (EFB)
Работа с большими данными
Оптимизирован для эффективной работы с большими наборами данных
Хорошо масштабируется, но может быть неэффективен на очень больших наборах данных
Оптимизирован для обработки больших объемов данных с низкими требованиями к памяти
Поддержка языков программирования
Поддерживает основные языки, включая Python, R, Java
Широкая поддержка языков, включая Python, R, Java, Scala
Поддерживает Python, R, Java и другие языки
Сложность моделей
Генерирует более сложные модели, но с контролем переобучения
Позволяет настраивать сложность модели через гиперпараметры
Строит более легковесные модели с использованием гистограммного подхода
Интерпретируемость
Обеспечивает хорошую интерпретируемость, особенно при работе с категориальными данными
Обеспечивает средний уровень интерпретируемости
Интерпретируемость может быть затруднена из-за оптимизаций и более сложных структур
Резюмируя
CatBoost выделяется своей способностью эффективно обрабатывать категориальные данные без предварительного кодирования. Он обеспечивает высокую производительность и эффективное предотвращение переобучения.
XGBoost ориентирован на производительность и гибкость. Он предоставляет широкий спектр параметров для тонкой настройки моделей, но требует более тщательной предварительной обработки данных, особенно категориальных.
LightGBM является наиболее эффективным при работе с большими наборами данных благодаря своему гистограммному подходу к построению деревьев и оптимизациям, таким как EFB.
Cat Boost
CatBoost использует решающие деревья глубины 1 или 2 в качестве базовых моделей. Эти неглубокие деревья, которые иногда называют «котэ», имеют следующие характеристики:
- Каждый узел дерева делает бинарное разбиение на основе значения одной из признаков.
- Эти короткие деревья обладают небольшой глубиной, что делает их более устойчивыми к переобучению.
К примеру мы решаем задачу классификации, где необходимо определить, будет ли клиент покупать продукт (1) или нет (0). Один из наших признаков — возраст клиента. Решающее дерево CatBoost может разделить клиентов на две группы: те, кто моложе 30 лет, и те, кто старше 30 лет.
Самая основная фича CatBoost это способность обрабатывать категориальные данные без предварительного кодирования. Другие алгоритмы требуют перевода категориальных данных в числовой формат (например, One-Hot Encoding), что может потребовать большого объема памяти и привести к потере информации.
CatBoost использует счетчики для категориальных признаков. Это означает, что для каждой категории создаются числовые признаки, отражающие статистику по этим категориям. Например, для задачи классификации, это может быть доля положительных и отрицательных классов внутри каждой категории.
Если у нас есть категориальный признак «город проживания», то счетчик для каждого города будет отражать долю клиентов, сделавших покупку, проживающих в этом городе.
CatBoost автоматически определяет категориальные признаки в данных. Это позволяет избежать необходимости вручную указывать, какие признаки являются категориальными.
Обработки категориальных данных может выглядеть так:
from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split # Загрузка данных X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Создание и обучение модели с автоматической обработкой категориальных данных model = CatBoostClassifier(iterations=1000, learning_rate=0.1, depth=6) model.fit(X_train, y_train) # Оценка производительности модели accuracy = model.score(X_test, y_test) print(f"Accuracy: ")CatBoost автоматически определяет категориальные признаки и обрабатывает их с использованием счетчиков. Это позволяет использовать категориальные данные напрямую при обучении модели, без необходимости кодирования их в числовой формат.
Пример использования с явным указанием категориальных признаков:
from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split # Загрузка данных X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Явное указание категориальных признаков cat_features = [0, 1, 3, 5] # Создание и обучение модели с указанием категориальных признаков model = CatBoostClassifier(iterations=1000, learning_rate=0.1, depth=6) model.fit(X_train, y_train, cat_features=cat_features) # Оценка производительности модели accuracy = model.score(X_test, y_test) print(f"Accuracy: ")В этом примере мы явно указываем, какие признаки являются категориальными с помощью списка cat_features . CatBoost будет обрабатывать только эти признаки как категориальные, остальные будут рассматриваться как числовые.
CatBoost включает механизм регуляризации, чтобы предотвратить переобучение модели. Он использует L2-регуляризацию, представляет собой метод добавления штрафа к функции потерь модели с целью предотвратить переобучение. Этот метод основан на добавлении суммы квадратов весов признаков к функции потерь. Формула выглядит следующим образом:
- λ (лямбда) — это гиперпараметр, который контролирует силу регуляризации. Он выбирается заранее и может быть настроен в процессе обучения модели.
- n — количество признаков в модели.
- wi — вес (коэффициент) i-го признака.
Таким образом, L2-регуляризация добавляет к функции потерь сумму квадратов весов всех признаков, умноженную на гиперпараметр λ. Это вынуждает модель уменьшать веса признаков и предотвращает их чрезмерное увеличение в процессе обучения.
Когда λ равно нулю, L2-регуляризация отсутствует, и модель обучается без ограничений на веса признаков. Когда λ большое, L2-регуляризация становится более сильной, и веса признаков близки к нулю. L2-регуляризация штрафует большие значения весов, поощряя модель использовать только наиболее информативные признаки.
Этот метод помогает улучшить обобщающую способность модели и снизить риск переобучения, особенно в случаях, когда у нас много признаков или они коррелированы между собой.
CatBoost автоматически выполняет отбор признаков путем оценки их важности для модели. Это позволяет модели сосредотачиваться на наиболее информативных признаках и уменьшить шум от менее значимых.
Если в задаче прогнозирования цены дома признак «цвет двери» оказывается малозначимым, CatBoost может исключить его из модели.
CatBoost применяет градиентный бустинг для обучения ансамбля решающих деревьев. Градиентный бустинг минимизирует функцию потерь с использованием градиентного спуска, постепенно улучшая качество модели.
На каждой итерации градиентного бустинга добавляется новое решающее дерево, которое исправляет ошибки предыдущих деревьев.
Библиотека Cat Boost
CatBoost (Categorical Boosting) — это библиотека для машинного обучения с открытым исходным кодом, разработанная Яндексом.
CatBoost можно установить с помощью pip, стандартного инструмента для установки Python-пакетов:
pip install catboostБиблиотека CatBoost (Categorical Boosting) представляет собой мощный инструмент для машинного обучения с открытым исходным кодом, разработанный компанией Яндекс. Она специально оптимизирована для работы с категориальными данными и предоставляет высокую производительность и точность в задачах классификации и регрессии. Давайте рассмотрим основной синтаксис CatBoost для создания, обучения и оценки моделей.
Основной синтаксис CatBoost:
CatBoost использует специальный объект Pool для представления данных. Вы можете создать Pool , указав признаки и целевую переменную. Это делается следующим образом:
train_data = Pool(data=X_train, label=y_train, cat_features=cat_features)Далее, вы создаете экземпляр модели ( CatBoostClassifier для классификации или CatBoostRegressor для регрессии) и обучаете его на данных:
model = CatBoostClassifier(iterations=1000, learning_rate=0.1, depth=6) model.fit(train_data)Вы можете оценить производительность обученной модели на тестовых данных:
accuracy = model.score(X_test, y_test) print(f"Accuracy: ")Для получения прогнозов на новых данных используйте метод predict :
predictions = model.predict(X_new)CatBoost позволяет оценить важность признаков с помощью атрибута feature_importances_ :
importances = model.feature_importances_Для оценки производительности модели с помощью кросс-валидации используйте функцию cv :
from catboost import cv cv_results = cv(train_data, model.get_params(), fold_count=5)Вы можете настраивать гиперпараметры модели, чтобы достичь лучшей производительности. Важные параметры включают iterations , learning_rate , depth и другие.
Подробнее изучить библиотеку можно здесь.
Немного примеров
1. Классификация (Бинарная)
from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import pandas as pd # Загрузка данных df = pd.read_csv('your_data.csv') X = df.drop('target', axis=1) y = df['target'] # Разделение данных X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Создание и обучение модели model = CatBoostClassifier(iterations=100, learning_rate=0.1) model.fit(X_train, y_train, verbose=False) # Оценка модели predictions = model.predict(X_test) accuracy = accuracy_score(y_test, predictions) print(f'Точность: ')2. Регрессия
from catboost import CatBoostRegressor import numpy as np # Подготовка данных X = np.random.rand(100, 10) y = np.random.rand(100) # Разделение данных X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Создание и обучение модели regressor = CatBoostRegressor(iterations=200, depth=4, learning_rate=0.01) regressor.fit(X_train, y_train, verbose=False) # Предсказание и оценка predictions = regressor.predict(X_test) print(predictions)3. Работа с категориальными данными
from catboost import Pool, CatBoostClassifier # Подготовка данных cat_features = [0, 2, 5] # индексы категориальных признаков data = Pool(data=X_train, label=y_train, cat_features=cat_features) # Создание и обучение модели model = CatBoostClassifier(iterations=300, learning_rate=0.05) model.fit(data, verbose=False)4. Использование предварительно обученной модели для предсказания
# Загрузка сохранённой модели model = CatBoostClassifier() model.load_model('catboost_model.dump') # Делаем предсказания predictions = model.predict(X_test) print(predictions)5. Перекрёстная проверка (Cross-Validation)
from catboost import cv, Pool # Подготовка данных cv_data = Pool(data=X, label=y, cat_features=cat_features) # Параметры для CV params = # Выполнение перекрестной проверки cv_results = cv(cv_data, params, fold_count=5, plot=True) print(cv_results)Заключение
CatBoost обладает рядом преимуществ, таких как автоматическая обработка категориальных признаков, встроенная регуляризация, автоматический отбор признаков и высокая производительность.
Однако основная крутая фича CatBoost заключается в его способности работать с категориальными данными без необходимости их предварительной обработки, что делает его идеальным выбором для задач, где категориальные признаки играют важную роль.
В завершение хочу порекомендовать вам бесплатный урок, который был создан специально для тех, кто хотя бы раз задумывался о переходе в сферу дата-аналитики, кто еще ничего не знает про инструменты в области анализа данных, но хотел бы попробовать свои силы в этом направлении. Приходите, будет интересно!
- Блог компании OTUS
- Программирование
- Алгоритмы