Введение
Модуль Solr позволяет эффективно взаимодействовать с сервером Apache Solr в PHP.
Модуль Solr — чрезвычайно быстрая, лёгкая, многофункциональная библиотека, которая позволяет разработчикам PHP эффективно взаимодействовать с экземплярами сервера Solr.
Версии 1.x модуля PECL поддерживают Apache Solr Server 1.3-3.x
Версии 2.x модуля PECL поддерживают Apache Solr Server 4.0+
Есть встроенные инструменты для добавления документов и обновления сервера Solr.
Она также содержит инструменты, которые позволяют создавать сложные запросы к серверу при поиске документов.
User Contributed Notes 1 note
11 years ago
For more up to date information see: http://pecl.php.net/package/solr
«It [the Apache Solr PHP extension] effectively simplifies the process of interacting with Apache Solr using PHP5 and it already comes with built-in readiness for the latest features added in Solr 3.1 . «
- Solr
- Введение
- Установка и настройка
- Предопределённые константы
- Функции Solr
- Примеры
- SolrUtils
- SolrInputDocument
- SolrDocument
- SolrDocumentField
- SolrObject
- SolrClient
- SolrResponse
- SolrQueryResponse
- SolrUpdateResponse
- SolrPingResponse
- SolrGenericResponse
- SolrParams
- SolrModifiableParams
- SolrQuery
- SolrDisMaxQuery
- SolrCollapseFunction
- SolrException
- SolrClientException
- SolrServerException
- SolrIllegalArgumentException
- SolrIllegalOperationException
- SolrMissingMandatoryParameterException
- Copyright © 2001-2024 The PHP Group
- My PHP.net
- Contact
- Other PHP.net sites
- Privacy policy
Docker и виртуализация локальных проектов

Когда какое-то время занимаешься разными проектами, возникает нужда в некоторой виртуализации рабочего пространства. Одному проекту нужен mysql, другому postgresql, третьему mariadb. Для четвертого нужен solr, у пятого старая версия php, и так далее. Даже если не дошло до конфликтов между версиями программ, держать все окружения включенными постоянно — не прикольно, а выключать/включать то что нужно руками — долго и можно запутаться.
Мне всегда хотелось, чтобы можно было запустить условную командочку work on my project , и чтобы все нужные сервисы поднялись, а ненужные — не мешались. А потом написать work on another project , и чтобы окружение переключилось на другой проект. И чтобы можно было легко перенести то или иное окружение на другой компьютер. И чтобы все они были одинаковыми, чтобы я не запутался: одинаковые названия БД, юзеры, пароли — чтобы отличались только тем, что действительно должно отличаться.
В общем, для всего этого лично я несколько лет использую Docker. Основное назначение у него, наверно, не совсем такое. Но на мой взгляд для виртуализции рабочего пространства на локалхосте он подходит практически идеально. Ниже я немного расскажу, как именно его использую. Спойлер: у меня всё предельно примитивно, ничего необычного. Видимо поэтому и прижилось.
Когда до меня добралось осознание, что виртуализация необходима — ребята вокруг активно пользовались Vagrant. Но я как-то почитал матчасть про особенности работы, про скорость старта, и приуныл. Докер тогда был еще совсем молодой, но судя по статьям про него — то, что надо. Так оно и оказалось, контейнеры стартовали — и стартуют сейчас — меньше чем за секунду. Красота!
Вообще, никакой особенной докер-магией я не пользуюсь, даже докерфайлы не пишу. Всё, повторюсь, предельно примитивно: есть образы, и есть контейнеры, которые из них запускаются. Примерно так:
- изначально (один раз) создаю контейнер с ОС, например Debian
docker run -it --name root-container debian /bin/bash- обычным способом ( apt install etc) устанавливаю все что нам может понадобиться в общем случае: LAMP, русификацию консоли, расширения сервера и php, xdebug, ssh и т.д.
- проверяю, что всё работает, и коммичу контейнер в образ:
docker commit root-container graker/my-root-containerЭто всё. Теперь для каждого проекта я могу создать отдельный контейнер из этого общего образа.
docker run -it --name project1 -v ~/devel/project1:/var/www graker/my-root-container /bin/bashИ тогда для каждого проекта в консольке можно написать:
docker start -i project1И окружение немедленно создастся, а консолька прибиндится к этому контейнеру под рутом. Если выйти из консольки — контейнер остановится, и не потеряет изменений. Снова сделаем docker start -i project1 — он снова запустится.
После старта контейнеру нужно поднять сервисы (сервер, БД, и т.п.) Для этого я держу в контейнере скриптик, в котором написано примерно
service apache2 start service mysql start service ssh start # .И запускаю его сразу после старта. Это наверное главное неудобство всего процесса — необходимость вручную выполнять вторую команду после старта. Автоматизированно решить эту проблему мне не удалось: если при создании контейнера указывать скрипт, то он выполняется, но не включается интерактивный режим. А он нужен, так что все равно приходится выполнять вторую команду — входить в интерактивный режим. Так или иначе, Ctrl+R и одинаковое название скрипта во всех контейнерах (startup.sh) легко решает эту проблему, запускаю я скрипт быстро и машинально.
А дальше в рамках запущенного контейнера я могу делать что хочу. Ставить дополнительный софт — мемкэшд какой-нибудь, профилеры, необычные расширения, sqlite для тестов и т.д. Всё сохранится в рамках контейнера а на хосте никак не отразится.
При этом к /var/www контейнера подмонтирована директория с кодом проекта, соответственно, я могу просто открыть ее в IDE и работать.
Если мне захочется поотлаживать код через xdebug, отладку можно пробросить через ssh-туннель.
Если понадобится работать над новым проектом, я из существующих контейнеров выберу наиболее близкий (по установленному софту) к необходимому, а дальше:
docker commit my-old-container graker/image-for-new-project docker run -t -i --name my-new-project graker/image-for-new-project /bin/bashИ у меня создан контейнер для нового проекта, в котором есть всё, что было в старом. Можно просто почистить старые данные (например drop database drupal; create database drupal ) — и работать.
Если понадобится перенести на другой компьютер, можно сохранять/разворачивать контейнеры одной строчкой (docker save/docker load). Да, архивы получатся большие, но это не такая частая операция, на самом деле.
Дополнительная плюшка: в каждом контейнере сохраняется свой файлик .bash_history . Что это значит? Это значит, что если я запускаю в каком-то проекте трехэтажную команду в консоли, скажем, что-нибудь с drush, или artisan, то она никуда не денется. Я могу не трогать проект полгода, а потом запустить контейнер и найти эту команду в истории, поскольку в ней будут команды, релевантные проекту, а не те, что я потом полгода запускал.
Иногда для того или иного проекта создаю дополнительные контейнеры. Но только если так действительно проще и быстрее. Например, Solr используется лишь некоторыми проектами, поэтому поставить контейнер с солром из официального докер-образа и подключить к нему рабочий проект — гораздо быстрее, чем ставить солр руками внутри контейнера. Но если бы солр использовался всегда, было бы проще один раз настроить его внутри контейнера, а потом закоммитить и наследовать.
И наоборот: можно было бы предположить, что рационально держать СУБД отдельным контейнером и подключать к нему проектные контейнеры для работы каждого со своей базой. Оно было бы правильно для организации сервера с несколькими сайтами, но для локальной работы это требует больше действий: подключать каждый раз контейнер к БД, создавать новую базу для каждого проекта, помнить как для каждого она называется и т.д. Вместо этого у меня в каждом контейнере стоит свой MySQL (или аналог), а база всегда называется одинаково: по имени фреймворка, например drupal, или laravel. И юзер, и пароль всегда тоже одинаковый. Освобождает память для более важных вещей.
В результате контейнеры занимают несколько больше места, но на терабайтном HDD мне этого вообще не заметно. А вот то, что меньше действий требуется — наоборот, заметно.
В целом это полностью описывает весь мой флоу по виртуализации проектов и переключению между ними. За несколько лет он прижился и всю разработку я веду только так — в контейнерах докера. Были у меня еще попытки автоматизировать установку Друпала в контейнеры (сделать сборку, или ставить из драш-дампа). Но я обычно стараюсь заниматься крупными/долгими проектами, поэтому необходимость создавать новые контейнеры под новые сайты возникает редко. Через это выгода от автоматизированной установки оборачивается геморроем по поддержанию сборки/дампа в актуальном состоянии. Тем более, для большого проекта все равно потом руками собирать. В общем, не прижилось.
Из недостатков я заметил, что не совсем понятно, как настроить PHPStorm, чтобы запускать тесты прямо из IDE по хоткеям. Приходится вручную их запускать из консоли, что требует чуть больше действий (переключиться на консоль, запустить phpunit с возможными аргументами). Неприятно, но не критично.
Кроме того, когда-то было ограничение для не-дебиан-подобных систем: не более 20 ГБ на контейнер. В openSUSE пару раз в это влетал когда-то, приходилось отцеплять огромную БД от основного контейнера в другой. Но на убунте такого ограничения нет, поэтому не знаю, может его уже вообще давно нет.
Настройте Solr и запустите его
Solr — популярная, быстро развивающаяся корпоративная поисковая платформа с открытым исходным кодом из проекта Apache Lucene. Его основные функции включают мощный полнотекстовый поиск, выделение совпадений, граненый поиск, динамическую кластеризацию, интеграцию базы данных и обработку документов (например, Word, PDF). Solr обладает высокой масштабируемостью, обеспечивает распределенный поиск и репликацию индексов, а также поддерживает функции поиска и навигации на многих крупнейших мировых интернет-сайтах.
Я бы не сказал, что это идеальный интерфейс REST, который воплощает в себе все принципы HTTP 1.1, но дело в том, что данные имеют простое представление, которое передается от клиента к серверу и обратно, и не содержат инкапсуляции в кошмарных оболочках SOAP. Кроме того, он удобочитаем, поскольку XML и JSON могут быть легко написаны для целей исследовательского тестирования.
Год назад, когда я услышал, что CouchDB имеет REST API, я сказал, что это бесполезный уровень абстракции, почему я не могу просто использовать расширение / драйвер PHP, как в MySQL, sqlite и подобных базах данных?
Теперь я вижу потенциал такого универсального интерфейса:
- это не зависит от языка из-за использования XML или JSON, что в настоящее время может интерпретироваться почти всем. Метрикой обычно является JavaScript: если вы можете понять его на JavaScript в браузере со всеми его ограничениями, вы можете сделать это везде. Конечно, JavaScript изначально поддерживает как JSON (посредством eval (), даже если это небезопасно), так и XML (с DOM).
- это не зависит от типа данных из-за HTTP, который может передавать только строки. Там нет безопасности типа, но большая совместимость. Динамические языки, такие как PHP, также очень успешны, потому что базовый протокол не имеет строгих типов. Если интерфейс только собирается его напечатать, почему строки не должно быть достаточно?
- это более или менее стандартный протокол (хотя представление данных — нет): если кто-то, кто изобрел базу данных, публикует свой собственный двоичный протокол связи, у нас будет намного больше библиотек.
Solr написан на Java, но вы можете получить к нему доступ на любом языке по вашему выбору, просто выполняя запросы GET для поиска в индексе и запросы POST для добавления документов.
Конечно, обычно есть библиотека для каждого известного языка программирования, которая оборачивает REST-подобный интерфейс, но создать такую библиотеку, например, с помощью JavaScript, очень просто, и совсем не обязательно использовать библиотеку. И это привело нас к другому вопросу: если бы у Solr был бинарный интерфейс, такой как у MySQL, как бы вы обернули это Javascript? HTTP универсален, так как теперь почти все, от компьютеров до духовок и фенов, может отправлять HTTP-запросы.
Начинающийся
Простота использования, начиная с протокола, является ключевой функцией по сравнению с Lucene, и действительно очень легко настроить Solr и запустить его.
Поскольку основной интерфейс Solr является веб-интерфейсом, ему нужен контейнер сервлета (изобретать колесо и реализовывать полный стек HTTP не было хорошей идеей). У Solr есть несколько сервлетов, которые обрабатывают разные конечные точки, такие как / update или / select.
Тем не менее, он поставляется с готовым примером с Jetty (небольшим, легким контейнером сервлетов), так что он запускается из коробки, но вы можете развернуть его также как веб-приложение Tomcat, если хотите.
Все, что вам нужно для запуска Solr — это распаковать релиз , перейдя в папку example / и запустив ‘java -jar start.jar’. Затем вы можете опубликовать образцы документов и сделать несколько запросов для пробного тестирования.
Конечно, связанная схема является примером, поэтому вы можете быстро изменить schema.xml для создания собственной схемы . Просто добавьте несколько тегов :
Автоматизация испытаний с индексом Solr
Поскольку Solr очень прост в использовании, давайте сделаем что-то страшное: автоматизация тестирования.
Когда я начал интегрировать Solr в свой проект приложения для поиска мультимедиа, я написал интеграционный тест с JUnit и классом SolrWrapper менее чем за два pomodoros , время, которое в основном пошло на изучение Api SolrJ, библиотеки Java, которая обертывает основанную на HTTP интерфейс. Я мог бы также сделать это просто с помощью URL и нативных объектов HttpURLConnection, если бы у меня не было библиотеки.
package it.polimi.chansonnier.test;
import java.util.ArrayList;
import java.util.Collection;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.impl.CommonsHttpSolrServer;
import org.apache.solr.client.solrj.impl.XMLResponseParser;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import junit.framework.TestCase;
public class SolrIntegrationTest extends TestCase private SolrWrapper solrWrapper;
public void testSolrInstanceCanBeStartedQueriedAndStopped() throws Exception solrWrapper = new SolrWrapper();
solrWrapper.start();
String url = "http://localhost:8983/solr";
CommonsHttpSolrServer server = new CommonsHttpSolrServer( url );
server.setParser(new XMLResponseParser());
server.deleteByQuery( "*:*" );// delete everything!
SolrInputDocument doc1 = new SolrInputDocument();
doc1.addField( "id", "id1", 1.0f );
doc1.addField( "name", "doc1", 1.0f );
Collection docs = new ArrayList();
docs.add( doc1 );
server.add( docs );
server.commit();
SolrQuery query = new SolrQuery();
query.setQuery( "*:*" );
//query.addSortField( "name", SolrQuery.ORDER.asc );
QueryResponse rsp = server.query( query );
SolrDocumentList docList = rsp.getResults();
assertEquals("[id1, doc1]", docList.get(0).values().toString());
>
public void tearDown() solrWrapper.stop();
>
>package it.polimi.chansonnier.test;
import java.io.File;
public class SolrWrapper private Process solr;
public void start() throws Exception Runtime r = Runtime.getRuntime();
solr = r.exec("/usr/bin/java -jar start.jar", null, getSolrRoot());
Thread.sleep(5000);
>
public void stop() if (solr != null) solr.destroy();
>
>
private File getSolrRoot() throws Exception String root = System.getProperty("it.polimi.chansonnier.solr.root");
if (root == null) throw new Exception("Solr path is not specified, please add the property it.polimi.chansonnier.solr.root");
>
return new File(root);
>
>Помните, что интеграционный тест по моему определению (и растущему объектно-ориентированному программному обеспечению ) включает только поведение внешнего объекта, чтобы убедиться, что мы понимаем, как он работает, и что контракт, к которому мы программируем в нашем коде, является правильным.
Теперь мои приемочные тесты запускают Solr и останавливают его в конце теста, сбрасывая его индекс в начале каждого метода теста:
package it.polimi.chansonnier.test;
import java.io.IOException;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.CommonsHttpSolrServer;
import org.apache.solr.client.solrj.impl.XMLResponseParser;
import junit.framework.TestCase;
public abstract class AcceptanceTest extends TestCase private SolrWrapper solrWrapper;
protected CommonsHttpSolrServer solrServer;
public void setUp() solrWrapper = new SolrWrapper();
try solrWrapper.start();
String url = "http://localhost:8983/solr";
solrServer = new CommonsHttpSolrServer( url );
solrServer.setParser(new XMLResponseParser());
solrServer.deleteByQuery( "*:*" );
> catch (Exception e) e.printStackTrace();
>
>
public void tearDown() solrWrapper.stop();
>
>Что теперь?
Теперь, когда у меня есть запущенный экземпляр Solr для моего приложения, я планирую использовать AJAX Solr , библиотеку JavaScript, которая отправляет запросы непосредственно в Solr, для создания расширенного интерфейса. AJAX Solr является доказательством того, что браузеры стали мощными сегодня: вы действительно можете видеть, как он выполняет запросы через Firebug (представьте, что вы делаете это с реляционными базами данных в качестве серверной части).
Я всегда боялся приложений с расширенными возможностями из-за сложности тестирования, но теперь инструменты для этого выросли. Конечно, я протестирую свой веб-интерфейс с помощью HttpUnit, как и с обычным HTML; он использует Rhino для сканирования страниц на основе JavaScript и утверждает, что они сгенерированы правильно.
Настройка компьютера разработчика. PHP. Drupal. DDEV
Я PHP разработчик, решил поделиться с Хабром своим опытом в части того, как подготовить на своем компьютере окружение, чтобы можно было создавать сайты PHP. Будет пример для Drupal. Но Drupal или нет, даже не важно, подойдет для любого другого PHP проекта. Грамотная настройка компьютера для разработки поможет в дальнейшем не тратить время и нервы. Этим придется пользоваться каждый день, поэтому стоит уделить время и сделать все так, чтобы было удобно пользоваться.
А что вообще надо чтобы запустился PHP сайт? Обычно нужен целый стек сервисов. Кроме того, чтобы не возникало ситуации: «локально работает, а на сервере — нет», необходимо чтобы сайт локально работал в окружении максимально похожем на то, как если бы сайт находился у провайдера. Это сам web сервер, интерпретатор PHP, база данных, composer, git, почтовый сервис, какой нибудь сервис для хранения индекса поиска (Solr например). Еще чтобы работал валидный https. Наверняка нужен node чтобы скомпилировать scss. То есть для того, чтобы программист мог вести разработку, это все надо иметь на локальном компьютере. Также надо иметь возможность менять версии всех этих сервисов. А для работы в команде необходимо, чтобы у всех разработчиков было одинаково настроенное окружение.
В этой задаче может быть много разных вариантов решения: от «поставить все это по отдельности на свой компьютер» до «разложить все сервисы по docker контейнерам, соединить их и использовать». Эти обе крайности имеют свои недостатки. Если все поставить на компьютер, то будет непросто работать с несколькими проектами у которых разные требования например к версиям сервисов. Настраивать Docker контейнеры это очень интересно, но сложно и вообще не про программирование.
Хорошо что существуют средства, созданные специально для упрощение настройки локальной среды разработки на PHP. Одно из них DDEV. DDEV это абстракция над docker с открытым исходным кодом. Вам не приходится работать с командами docker: перенаправлять порты, пробрасывать переменные и тому подобное. Там это уже настроено. Из коробки имеется один конфигурационный файл: config.yaml в нем есть описание возможных параметров. Самые основные: можно выбрать версию PHP тип и версию базы данных, тип веб-сервера, и другие. Причем эти настройки индивидуальны для каждого проекта и можно запускать несколько сайтов одновременно, они друг другу мешать не будут. Это решение работает на Маке (любой процессор), Линуксе и Винде.
Установка
У DDEV есть хорошая документация в том числе и раздел установка. На примере для MacOS: сначала устанавливается Docker Desktop или Colima. Затем, с помощью менеджера пакетов brew устанавливается сам DDEV.
brew install drud/ddev/ddev mkcert -installСоздание нового проекта
Опять же на примере для MacOS. В терминале создаем папку где будут находится все проекты. Это папка Projects в домашней папке пользователя.
cd ~ mkdir Projects cd ProjectsЗатем создаем папку самого проекта. Она будет называться my-ddev-test
mkdir my-ddev-test cd my-ddev-testТеперь надо загрузить в эту папку Drupal. Это можно сделается с помощью composer:
composer create-project drupal/recommended-project .Теперь инициализируем DDEV в этой же папке
ddev configЗапустится мастер создания проекта: предлагается выбрать имя проекта (обычно совпадает с названием папки, но имя должно быть уникальным), название папки в которой веб-сервер будет искать файлы сайта (он ее определит сам, для Drupal это /web), а так же тип проекта (тоже определит сам). DDEV умеет подстраиваться под работу с популярными CMS: backdrop, drupal10, drupal6, drupal7, drupal8, drupal9, laravel, magento, magento2, php, shopware6, typo3, wordpress. Выбрав из списка, мы получим готовый конфигурационный файл с настройками для базы данных.
Выглядит это так:
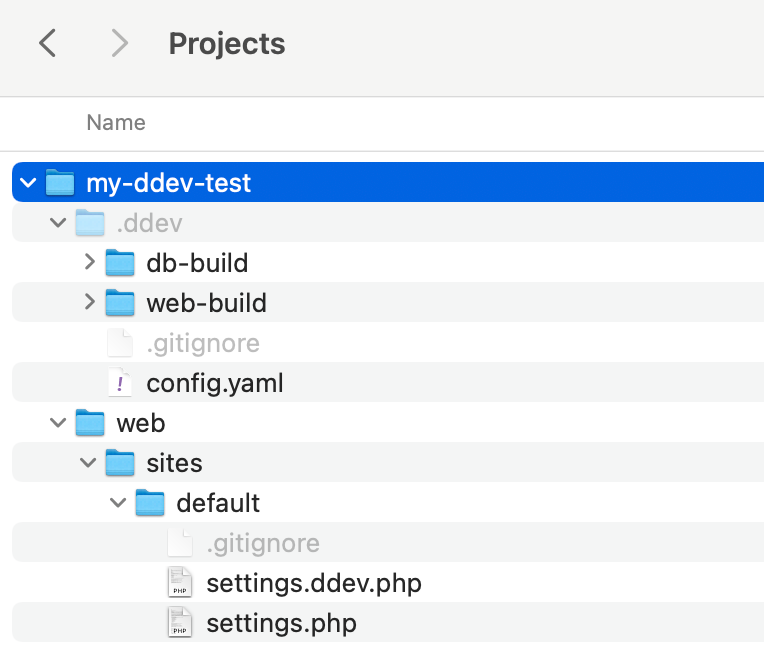
Я специально спрятал файлы Drupal которые мы сначала загрузили с помощью composer, чтобы показать что именно создается при инициализации проекта DDEV. Это сама папка .ddev, в ней главный файл настроек config.yaml, и конфигурации в соответствии с выбранным типом проекта. То есть web/sites/default/settings.php Это тот файл в котором Drupal видит кроме прочих настроек, настройки подключения к базе. Файл web/sites/default/settings.ddev.php динамически генерируется и инжектится в основной файл настроек.
Запуск и основные команды
Чтобы запустить проект надо в терминале в папке проекта (там где находится .ddev) выполнить
ddev startПри первом запуске будут скачаны необходимые Docker image. Они не будут храниться в папке проекта и повторно, например для нового проекта, скачиваться не будут. Проект запустится и в ответ в терминале мы увидим URL по которому сайт можно отрыть в браузере.
ddev describeпокажет основные данные проекта.
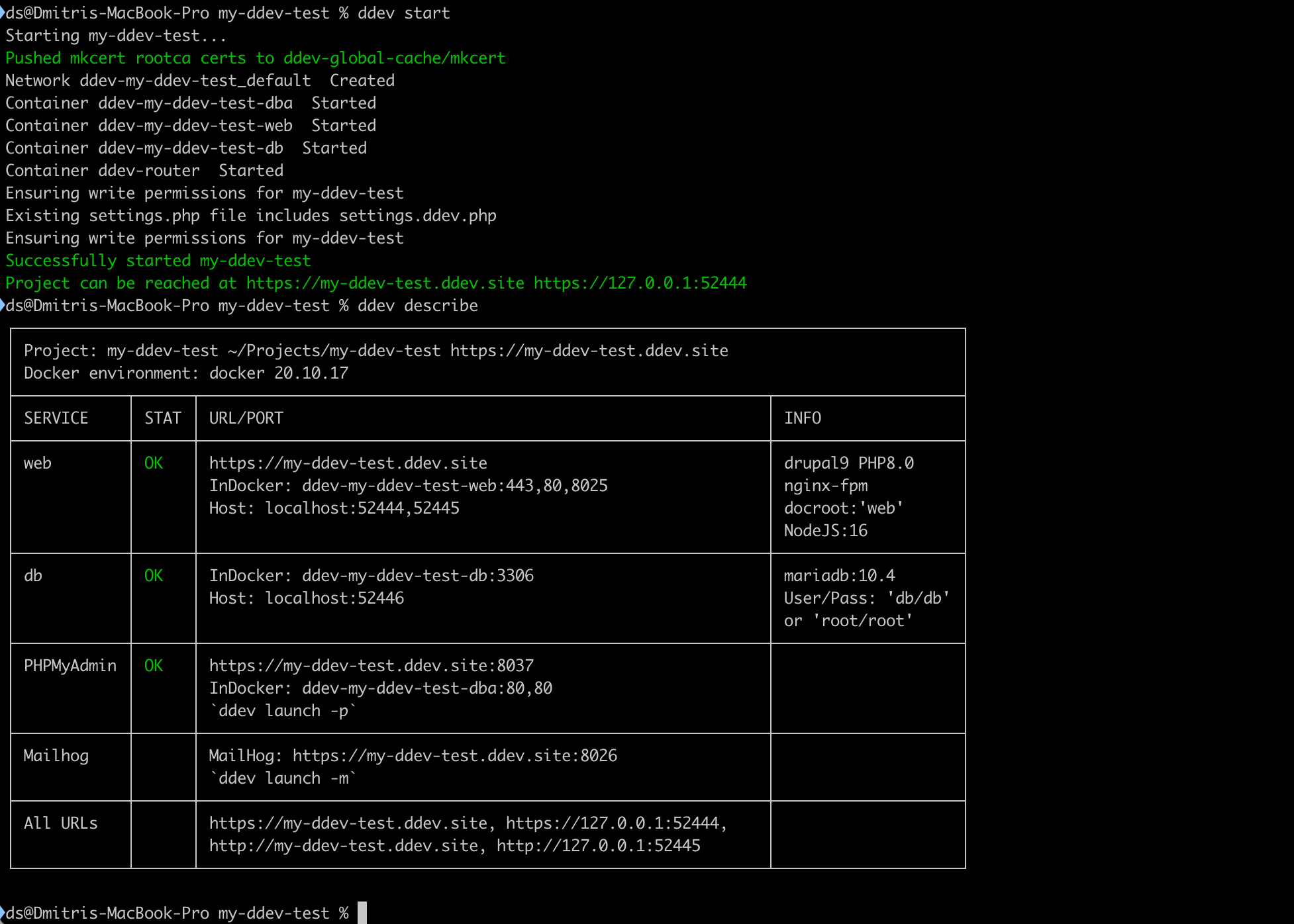
Да, сразу из коробки доступны Mailhog и PHPMyAdmin.
Вот описание всех команд. А вот основные, которые будут использоваться каждый день:
- ddev config — создать проект, поменять настройки. (Так же можно менять файл настроек вручную).
- ddev start — запустить проект
- ddev stop — остановить проект
- ddev delete — удалить проект
- ddev poweroff — остановить все проекты
- ddev xdebug on — включить отладчик кода xdebug
- ddev xdebug off — выключить отладчик кода xdebug
Отдельно надо упомянуть эти команды:
- ddev sequelace — запускает менеджер базы дынных Sequel Ace или Sequel pro смотря что у вас установлено. То есть даже не надо прописывать параметры подключения, DDEV сам их передает!
- ddev ssh — вход в консоль контейнера. Это как если бы подключились к хостинг серверу по ssh. Например можно внутри контейнера установить Node version manager и использовать для компиляции темы. Из коробки node присутствует в виде трех последних версий.
- ddev logs -help — Можно почитать, как смотреть логи сервера. Например чтобы посмотреть логи базы данных надо выполнить: ddev logs -s db
Запущенные контейнеры их статусы и логи можно посмотреть так же в Docker desktop dashboard.
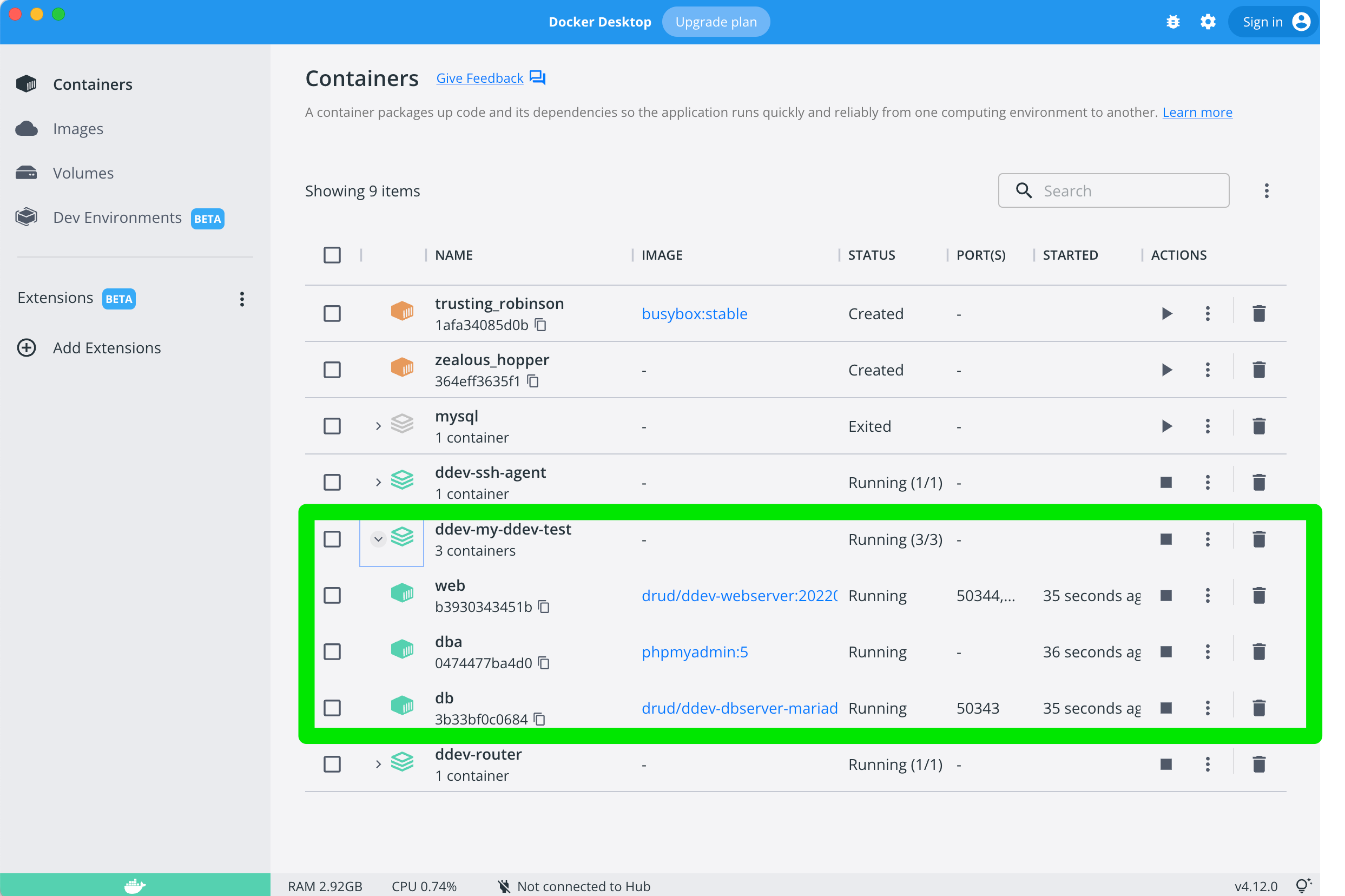
Через команду ddev выполняется ваша команда внутри контейнера. То есть чтобы например очистить кеш Drupal через drush надо выполнить:
ddev drush crЛибо войти в контейнер с ddev ssh и затем как обычно drush cr
Что это за Drush?
У Drupal есть команды, которые запускаются в консоли. Это очень мощная фича, помогает автоматически генерировать код, включать/выключать модули, сбрасывать пароли пользователей, генерировать одноразовые URL для входа в админку, исполнять отдельные методы классов и очень много чего еще. Drush это то, чем разработчик Drupal пользуется постоянно.
Composer тоже лучше запускать внутри контейнера (ddev composer install), тогда он будет видеть правильную версию PHP, а не ту, что установлена у вас на на компьютере.
Настройки
Основные настройки в файле .ddev/config.yaml В документации есть описание как внести расширенные настройки. Если необходимо внести изменения в php.ini, то создаем файл .ddev/php/my-php.ini с настройками. Пример:
[PHP] max_execution_time = 240;Если необходимо внести изменения в настройки MySql, то создаем файл .ddev/mysql/my.cnf с настройками. Пример:
[mysqld] collation-server = utf8_general_ci character-set-server = utf8 innodb_large_prefix=falseЕсть описание как добавлять дополнительные сервисы. Например если нужен Solr, то необходимо выполнить:
ddev get drud/ddev-drupal9-solrДобавится контейнер, который будет доступен в вашем проекте.
После внесения изменений в конфигурацию проекта его необходимо перезапустить, чтобы изменения вступили в силу: ddev restart или просто ddev start
Заключение
Существуют и другие подобные «надстройки» над docker. Я работал с Docksal, вероятно имеются и другие. DDEV действительно удобно использовать. Работает стабильно и быстро. Имеется хорошая документация. Можно настроить любые параметры в этом окружении. То есть воссоздать локально окружение, которое есть на боевом сервере у провайдера. Главный плюс, это то, что программист может больше заниматься программированием, а не devops задачами. Кроме того, настройки DDEV могут и должны храниться в репозитории проекта, в git вместе с кодом сайта. В этом случает другой программист или вы сами просто запускаете ddev start и получаете сразу готовое, настроенное как надо для данного сайта окружение.